存储结构
1、存储概念特点
特点
优先读写内存- 写:直接写入内存
- 读:先读内存,如果读不到,再读HDFS
- 整个Hbase 中所有的数据都是按照Rowkey顺序排列的
- 查询数据时可以根据
rowkey前缀匹配查询 Rowkey是整个Hbase的唯一索引- 数据类型:Hbase底层存储类型都是字节
- 数据结构:
KV结构,每一列在底层存储都是一个KVKey:Rowkey+列族名称+列的名称+时间戳- 20200101_001 column=basic:age, timestamp=1593247238403
Value:值- value=18
概念
RowKey:类似于主键的概念
- 唯一标记一行
基于rowkey排序唯一索引
RegionServer:HBASE架构中的从节点
- 所有Hbase的数据都是写入RegionServer的,也是从RegionServer中读取数据
- 写:写入了Regionserver的内存中
- 读:先读RegionServer的内存
- 从节点会有多台
每一台RegionServer上都可以有很多个Region- 类似于DataNode
RegionServer是将数据存储在内存中- RegionServer会调用HDFS的客户端将数据写入HDFS
DataNode是将数据存储在磁盘上
Region:RegionServer中的存储单元
- 就是
数据表的分区

一个Region必然会被某一个RegionServer所管理一个RegionServer可以管理多个Region
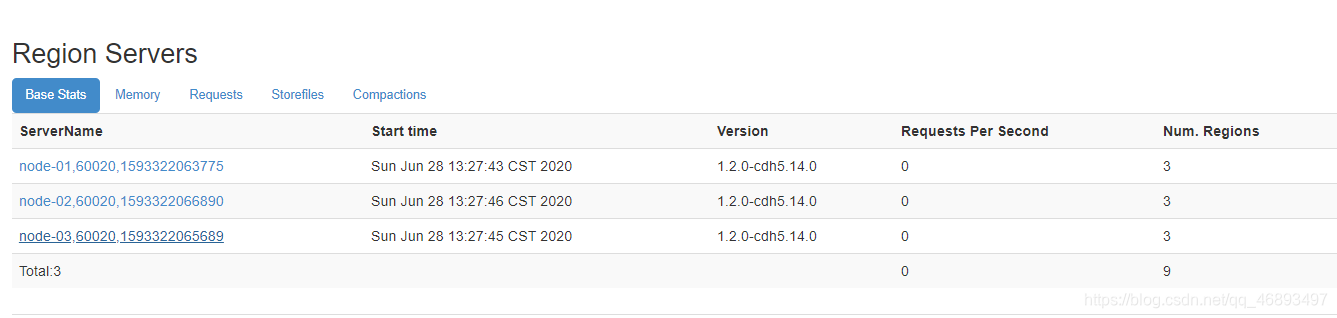
思考:我有一张表,我有很多数据,我要写入这张表,我怎么让这张表变成分布式的?
- 只有这张表是
分布式的,我才能分布式的并行将数据进行读写? - 让一张表有多个分区,不同的分区存储在不同的机器上
region:分区regionserver:region所在的机器
- 往表中写数据,会根据一定的规则,写入某一个分区
- 假设有一张表,有三个分区
- region0:node-01
- region1:node-02
- region2:node-03
- 第一条数据:写入第一个分区region0
- 第二条数据:写入第二个分区region1
- 第三条数据:写入第三个分区region2
- ……
- 实现分布式的存储
- 假设有一张表,有三个分区
Hbase中:
- 每一张表,默认开始只有一个分区
每个Region都有一个范围- 如果一张表只有一个region:-oo ~ +oo

- 如果一张表有两个region
- region0:-oo ~ 1000
- region1:1000 ~ +oo
- ……
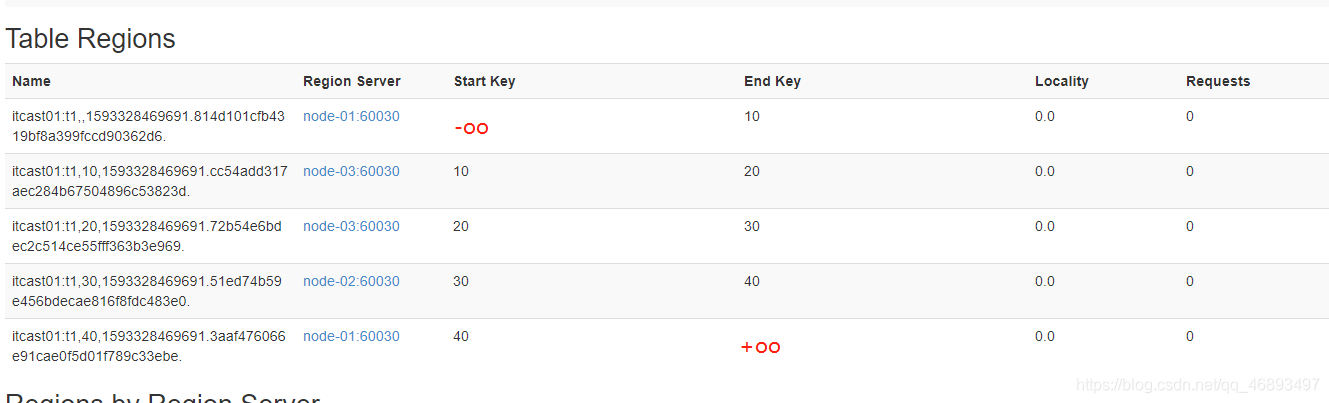
- 如果一张表有五个分区
- region0:-oo ~ 10
- region1:10 ~ 20
- region2:20 ~ 30
- region3:30 ~ 40
- region4:40 ~ +oo
分区规则:根据rowkey所属的范围- 类比
| 概念 | HDFS | Hbase |
|---|---|---|
| 数据 | 文件 | 表 |
| 拆分 | 分块:Block | 分区:Region |
| 规则 | 128M一个Block | 范围 |
| 机器 | DataNode | RegionoServer |
| 块有副本 | 分区没有副本 |
- 演示:一张表有多个分区
create 'itcast01:t1', 'info', SPLITS => ['10', '20', '30', '40']

- 分区规则:根据rowkey来进行分区
- 1111:region1
- 10 < 1111 < 20
- 5:region4
- 40 < 5 < +oo
- 1111:region1
- Region与表的关系
Region就是表的分区,一张表默认只有一个分区,可以有多个分区- 往表中写入数据时,根据分区规则会写入这张表的不同的分区
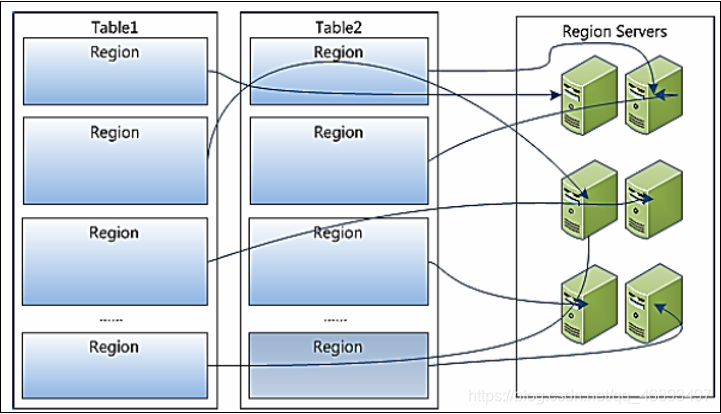
- Region与RegionServer的关系
- Region存储在RegionServer中,由RegionServer进行管理
Region是RegionServer负载均衡的最小单元- regionserver1:10个region
- regionserver2:5个region
- regionserver3:3个region
- |
- |负载均衡:均衡分配Region
- |
- regionserver1:6个region
- regionserver2:6个region
- regionserver3:6个region
Store:Region中更小的存储单元
region是表在rowkey的方向上进行了划分多个分区- Rowkey:-oo ~ +oo
Store是表中列的划分,store就是列族- 这张表中的每个Rowkey对应的数据有一个列族,对应的region中就有一个Store
- 不同列族的数据存储在不同的Store中,相同列族的数据存储在一起
- 为什么要设计列族这个概念?
- 就是
为了将经常一起读写的数据存在一起(相似io属性) 加快读写的 效率
- 就是
- 为什么要设计列族这个概念?
memstore:Store中存储数据的内存区域
每个store中都有一个memstore,用于存储写入的数据不同列族就是store的数据写入不同的内存- 使用的是这个region所在的regionserver的内存
StoreFile:每个Store中内存刷新出来的文件就是storefile
一个Store中逻辑上可能会有多个storefile文件- Storefile存储在HDFS上,对HFILE的封装

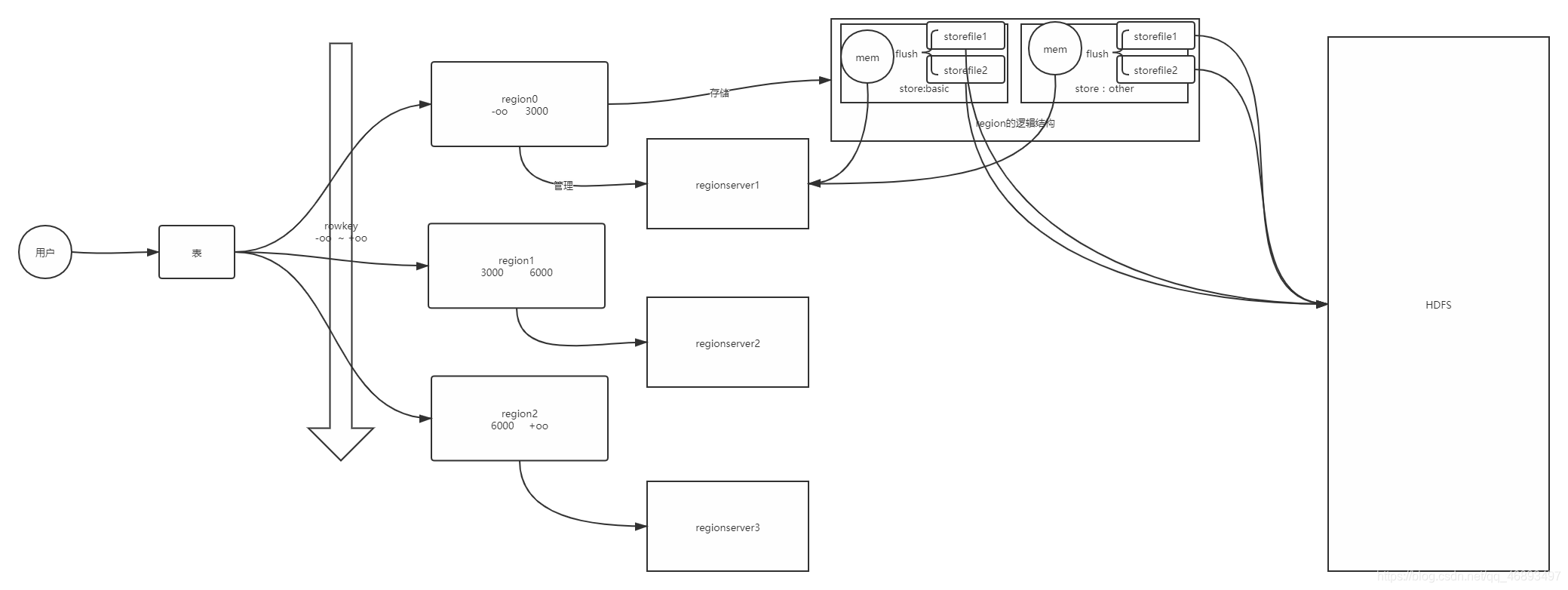
2、逻辑结构
- Put语句
put 'ns:tbname','rowkey',cf:col,value
- RegionServer:从节点,用于存储Hbase中所有的数据
- Table:所有的数据都是以表的形式存在,读写都是指定表
- Region:实现表与RegionServer的关联,表的分区,用于根据
rowkey将表变成分布式的- Store:每个分区内部按照
列族进行划分store,更小的分区- MemStore:Regionserver的内存区域,每个Store有1个MemStore
- StoreFIle:多个,内存中刷写出来的数据
- 逻辑上属于这个Store
- 真正存储在HDFS上
分区没有副本,如果分区所在的宕机了怎么办?- Hbase会在别的regionserver上恢复这个region
- 数据怎么保证不丢失?
StoreFile可以通过HDFS副本进行恢复- memStore中的数据如何 恢复?
- Store:每个分区内部按照
- Region:实现表与RegionServer的关联,表的分区,用于根据
- Table:所有的数据都是以表的形式存在,读写都是指定表
- 监控逻辑结构
- 表

- 分区:Region

3、物理结构
- regionServer所在的机器
内存- 看不到
- DataNode所在的机器
- 磁盘
- HDFS上存储的结构
- NameSpace:在HDFS都对应一个目录
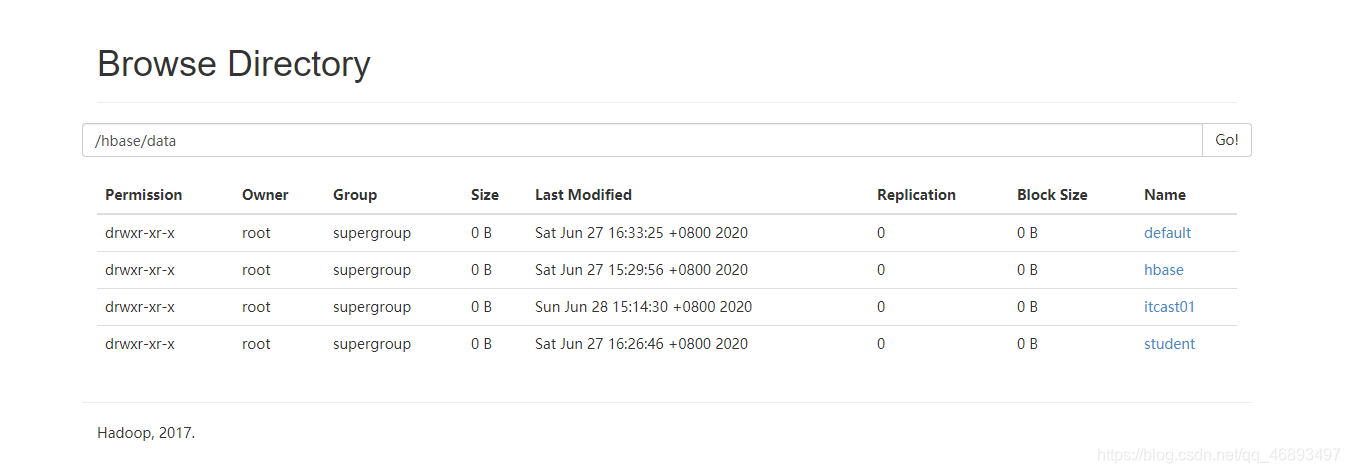
- NameSpace:在HDFS都对应一个目录
- Table:在HDFS上对应一个 目录
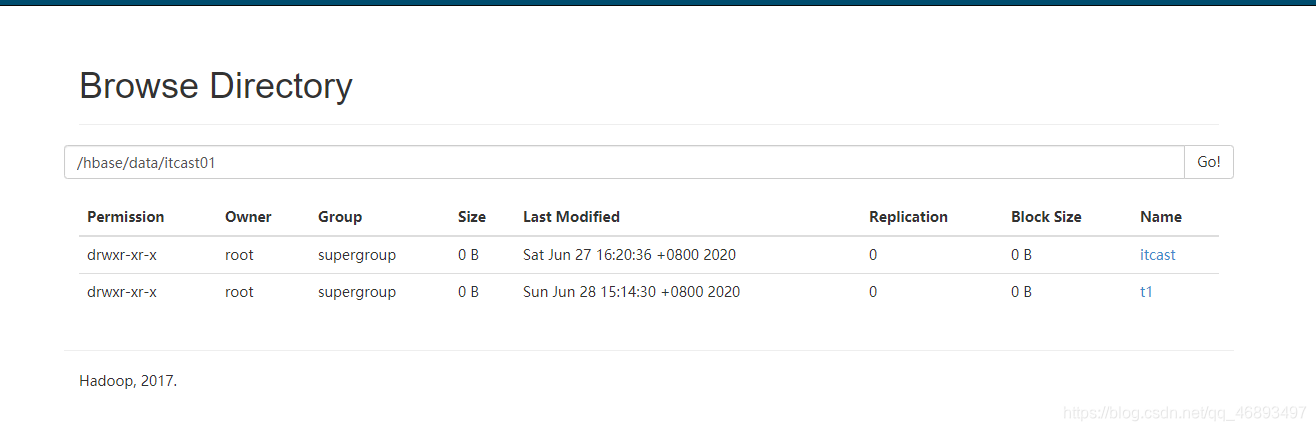
- Region:在HDFS上对应一个目录
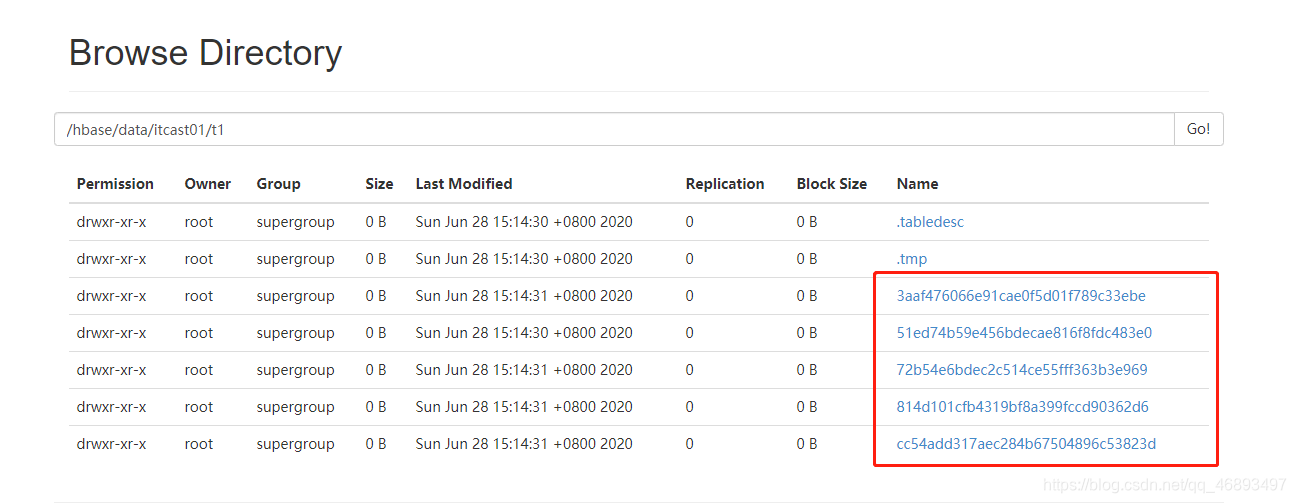
- Store:在HDFS上对应一个目录,就是列族

- StoreFile:HDFS上的文件
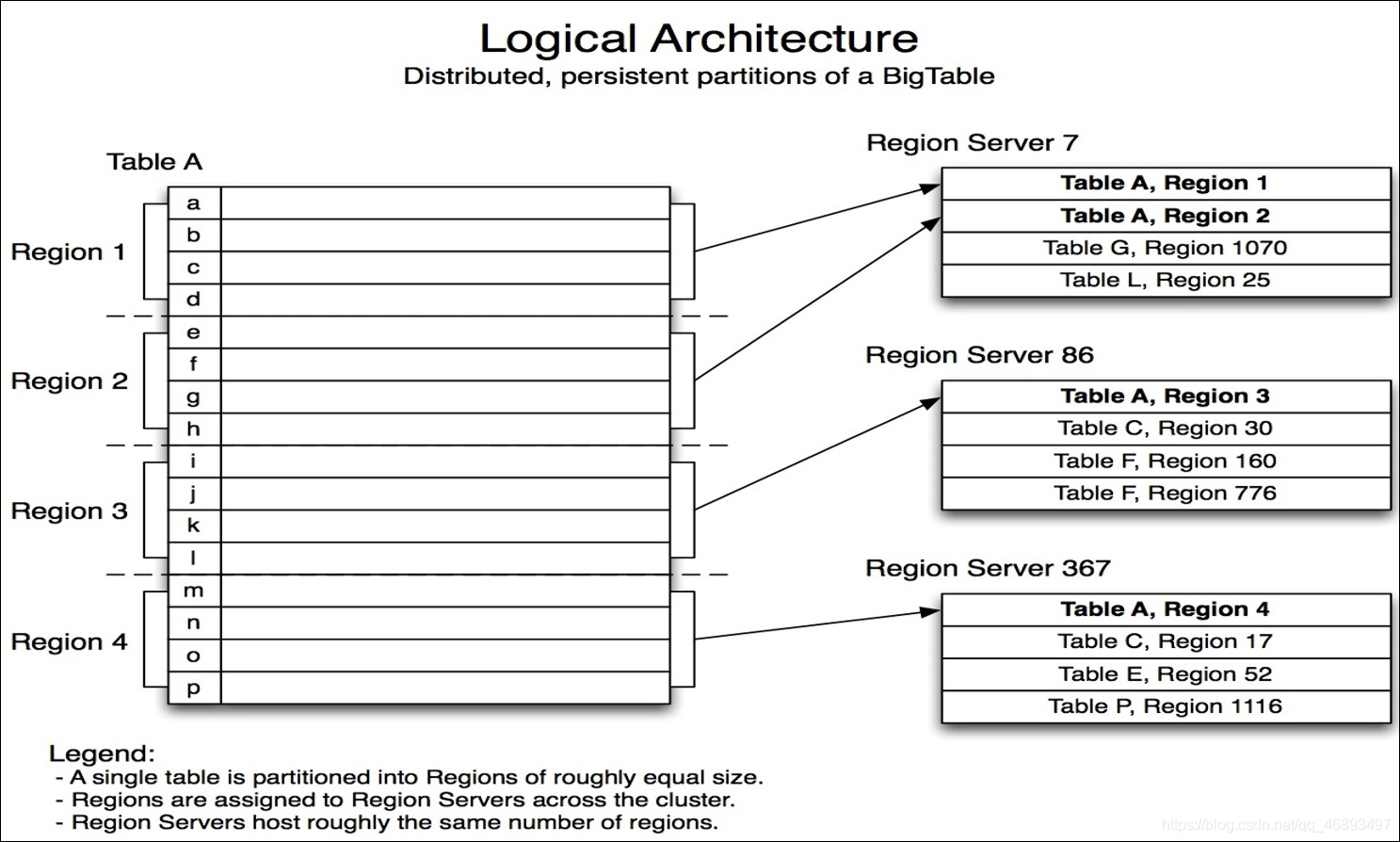
4、存储架构
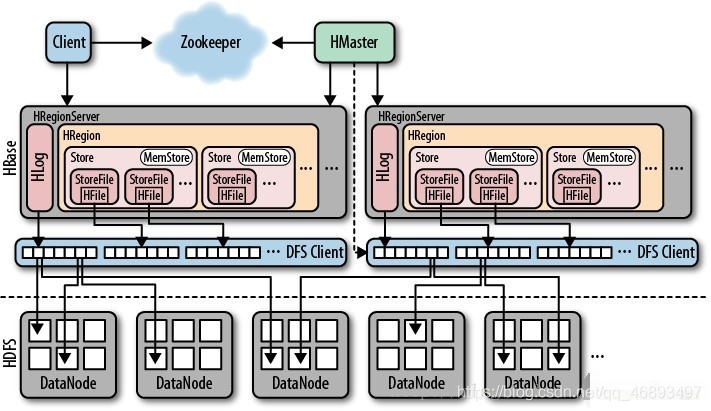
- 第一步:客户端根据表名和rowkey,找到对应region
- 它怎么知道这个表有些region的呢?
- 它怎么知道每个region的范围?
- 它怎么知道这个region在哪台regionserver上的呢?
- 第二步:
客户端会请求这个region所在的Regionserver,提交写请求 - 第三步:
RegionServer根据我们的请求来写入Region,根据列族来判断写入哪个Store - 第四步:
将这个数据读写Store中的MemStore- 如果是读:
先读memstore ,如果没有读StoreFIle - 如果是写:直接写入MemStore
- MemStore中的数据达到一定条件,会自动触发Flush
- 将memStore中的数据刷写变成Storefile文件,写入HDFS
- MemStore中的数据达到一定条件,会自动触发Flush
- 如果是读: