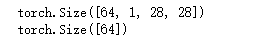import numpy as np
import torch
from torch import nn, optim
from torch. autograd import Variable
from torchvision import datasets, transforms
from torch. utils. data import DataLoader
train_data = datasets. MNIST( root= "./" ,
train = True ,
transform= transforms. ToTensor( ) ,
download = True
)
test_data = datasets. MNIST( root= "./" ,
train = False ,
transform= transforms. ToTensor( ) ,
download = True
)
batch_size = 64
train_loader = DataLoader( dataset= train_data, batch_size= batch_size, shuffle= True )
test_loader = DataLoader( dataset= test_data, batch_size= batch_size, shuffle= True )
for i, data in enumerate ( train_loader) :
inputs, labels = data
print ( inputs. shape)
print ( labels. shape)
break
class Net ( nn. Module) :
def __init__ ( self) :
super ( Net, self) . __init__( )
self. fc1 = nn. Linear( 784 , 10 )
self. softmax = nn. Softmax( dim= 1 )
def forward ( self, x) :
x = x. view( x. size( ) [ 0 ] , - 1 )
x = self. fc1( x)
x = self. softmax( x)
return x
model = Net( )
mse_loss = nn. CrossEntropyLoss( )
optimizer = optim. Adam( model. parameters( ) , lr= 0.001 )
def train ( ) :
for i, data in enumerate ( train_loader) :
inputs, labels = data
out = model( inputs)
loss = mse_loss( out, labels)
optimizer. zero_grad( )
loss. backward( )
optimizer. step( )
def test ( ) :
correct = 0
for i, data in enumerate ( test_loader) :
inputs, labels = data
out = model( inputs)
_, predicted = torch. max ( out, 1 )
correct += ( predicted== labels) . sum ( )
print ( "Test acc:{0}" . format ( correct. item( ) / len ( test_data) ) )
for epoch in range ( 10 ) :
print ( "epoch:" , epoch)
train( )
test( )