问题场景
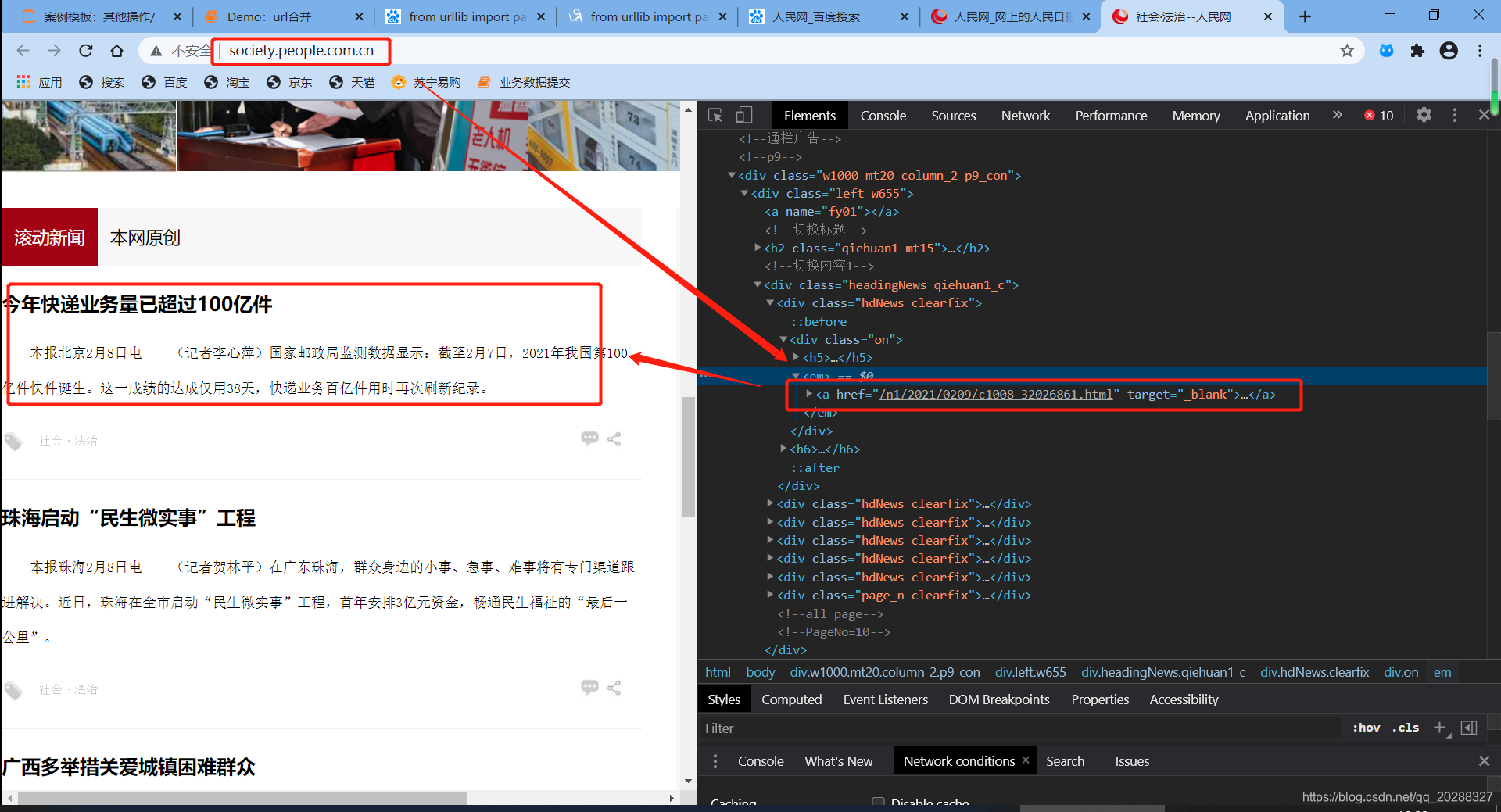
类似 人民网-科学频道 在我们进行数据抓取的时候会遇见文章列表页url是绝对路径的情况,这个抓取下来直接访问详情页是没有结果直接404的,因此需要将网址url进行拼接或者详情页的网址。
处理方式
处理方式有很种,这里介绍一种最简单的方法。
# 加载第三方包
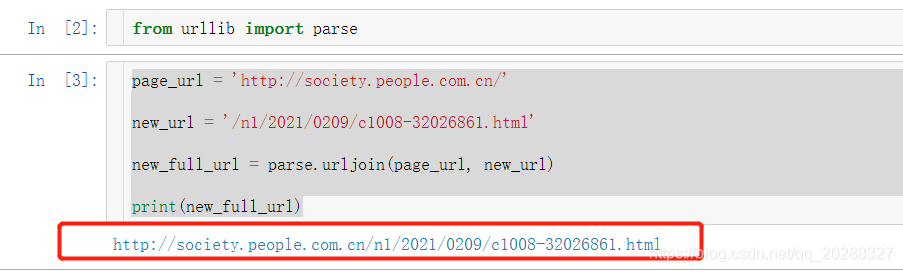
page_url = 'http://society.people.com.cn/'
new_url = '/n1/2021/0209/c1008-32026861.html'
new_full_url = parse.urljoin(page_url, new_url)
print(new_full_url)