目标网站介绍
36氪 36氪通过全面,独家的视角为用户深度剖析最前沿的资讯,致力于让一部分人先看到未来,内容涵盖快讯,科技,金融,投资,房产,汽车,互联网,股市,教育,生活,职场等,秉承着…

开始Scrapy
数据采集准备
1. 不了解5分钟快速抓网站思路的小伙伴先看
【Scrapy 五分钟撸网站】全站数据必备基础知识
2. 不了解数据抓取业务管理整理小伙伴先看
【Scrapy 五分钟撸网站】爬虫目标整理和数据准备
3. 不了解Scrapy模板量产的小伙伴先看(必看)
【Scrapy 五分钟撸网站】数据抓取项目框架通用模板
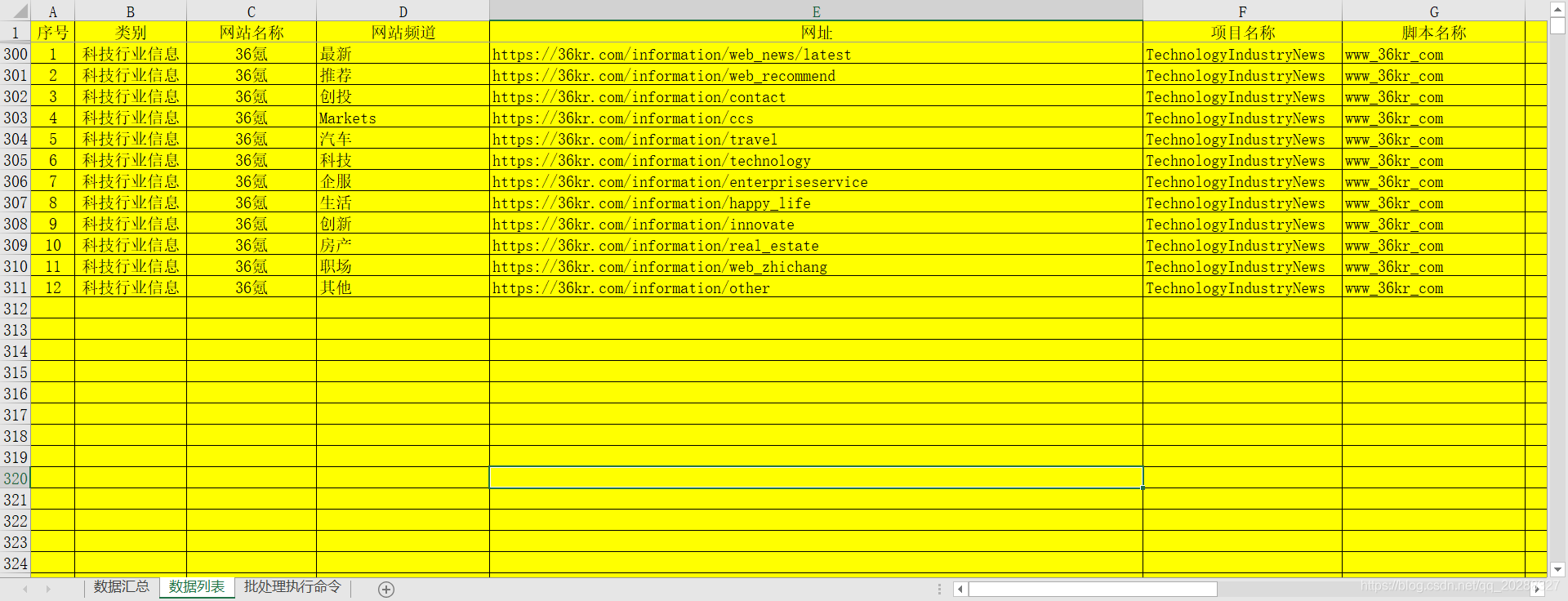
数据整理结果
1. 全频道Url获取地址

2. Excel保存截图
模板套用
Spider下的<项目>.py文件
1. 创建spider项目
scrapy genspider www_36kr_com " "
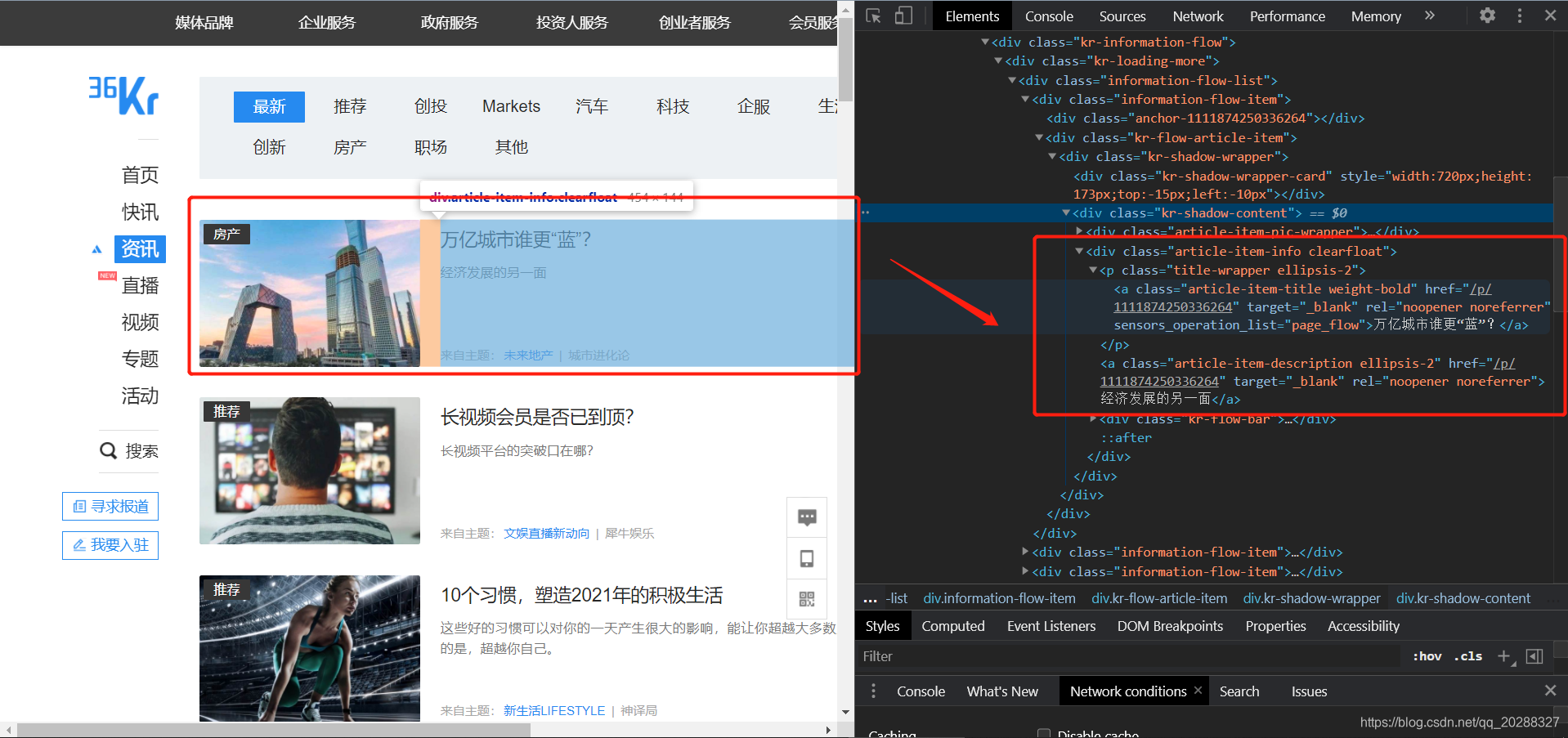
2. 整理全站css样式
先来看下页面的CSS样式,全站统一样式。
3. 修改www_36kr_com.py的的内容
这里将需要修改的地方进行说明,其他地方参考模板,不需修改。
- 作用域&自定义说明
allowed_domains = []
web_name = "36氪"
- 添加抓取数据信息
start_menu = [
# 全资讯频道第一页部分
[
{
"channel_name": "最新", "url": "https://36kr.com/information/web_news/latest", },
{
"channel_name": "推荐", "url": "https://36kr.com/information/web_recommend", },
{
"channel_name": "创投", "url": "https://36kr.com/information/contact", },
{
"channel_name": "Markets", "url": "https://36kr.com/information/ccs", },
{
"channel_name": "汽车", "url": "https://36kr.com/information/travel", },
{
"channel_name": "科技", "url": "https://36kr.com/information/technology", },
{
"channel_name": "企服", "url": "https://36kr.com/information/enterpriseservice", },
{
"channel_name": "生活", "url": "https://36kr.com/information/happy_life", },
{
"channel_name": "创新", "url": "https://36kr.com/information/innovate", },
{
"channel_name": "房产", "url": "https://36kr.com/information/real_estate", },
{
"channel_name": "职场", "url": "https://36kr.com/information/web_zhichang", },
{
"channel_name": "其他", "url": "https://36kr.com/information/other", },
]
# 动态加载部分,及后面的页码
# 加载网址是 https://gateway.36kr.com/api/mis/nav/ifm/subNav/flow
# 参数是 下面这样 需要后面页码自行整理
# {"partner_id": "web", "timestamp": 1614135556442,
# "param": {"subnavType": 1, "subnavNick": "web_news", "pageSize": 30, "pageEvent": 1,
# "pageCallback": "eyJmaXJzdElkIjozMjIwNjQ1LCJsYXN0SWQiOjMyMjAyNjgsImZpcnN0Q3JlYXRlVGltZSI6MTYxNDEyMTg5ODE2NSwibGFzdENyZWF0ZVRpbWUiOjE2MTQwNzc5ODUwMDB9",
# "siteId": 1, "platformId": 2}}
]
- 样式整理
整体网站数据列表有多少种样式就要做多少个parseX,并添加到
parse_list = [
self.parse1, # 全资讯频道第一页部分
]
- 标题&链接&封面
Item_title = response.xpath('//div[@class="kr-shadow-content"]/div[2]/p/a/text()').extract() # 文章标题列表
Item_url = response.xpath('//div[@class="kr-shadow-content"]/div[2]/p/a/@href').extract() # 文章链接列表
Spider下的parse_detail.py文件
1. 抓取详情页内容
修改列表数据详情页的CSS抓取样式
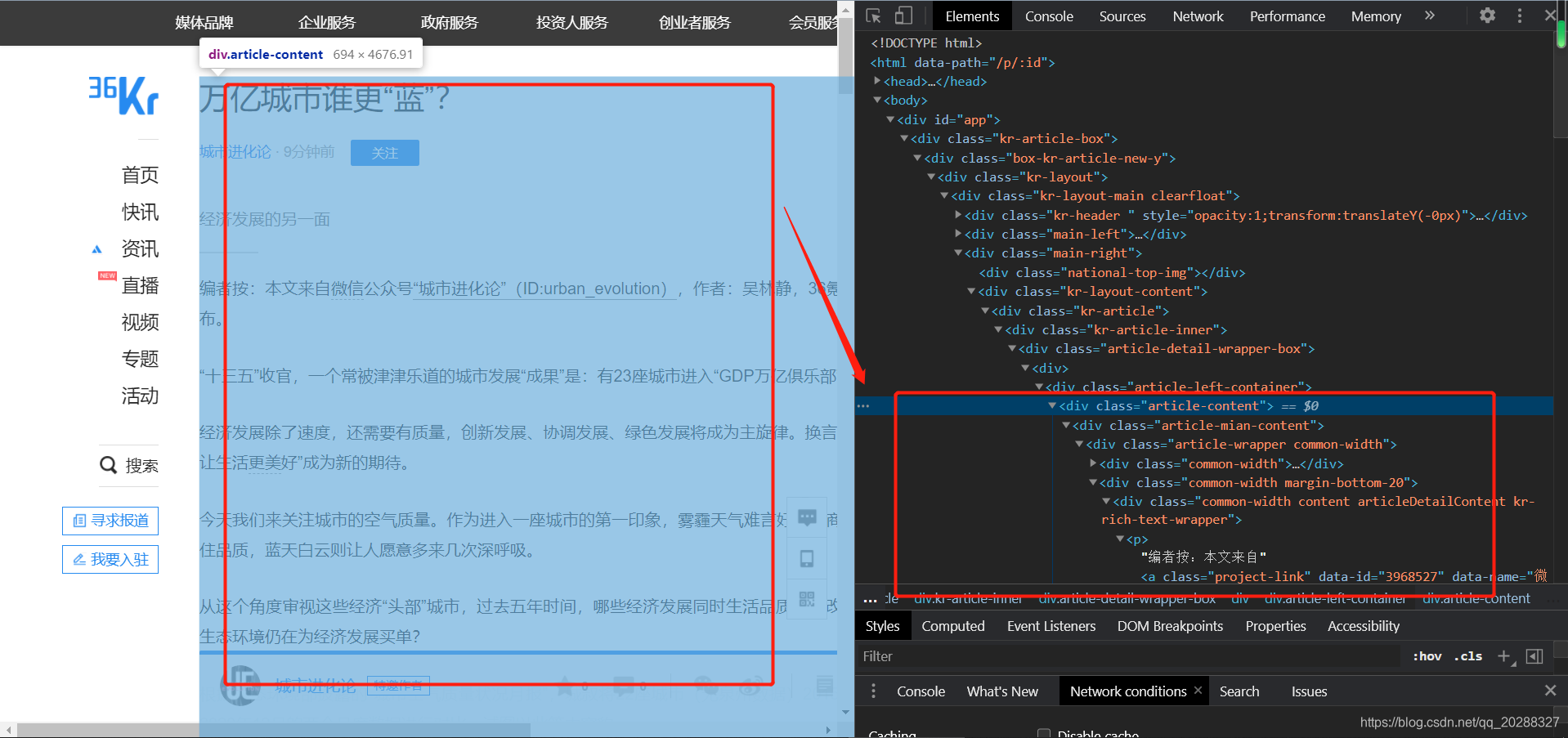
# 处理详情页带格式,这里整个页面进行抓取
item['content'] = ""
if 'class="article-content"' in response.text and len(None2Str(item['content'])) < 5:
item['content'] = response.xpath('//div[@class="article-content"]').extract_first()
2. 特别说明
有些网站的程序员丧心病狂到一定程度10个页面9种样式这种,由于我们不可能每个页面都打开看一下详情页的CSS格式,因此有个通用的解决办法。
- 第一次抓取完内容之后打开MongoDB数据库执行下面的命令会把包含body的页面数据筛选出来,这些是没有根据指定样式抓取的数据,而是直接抓的全部页面的数据。
db.你的表名.find({content:/body/})
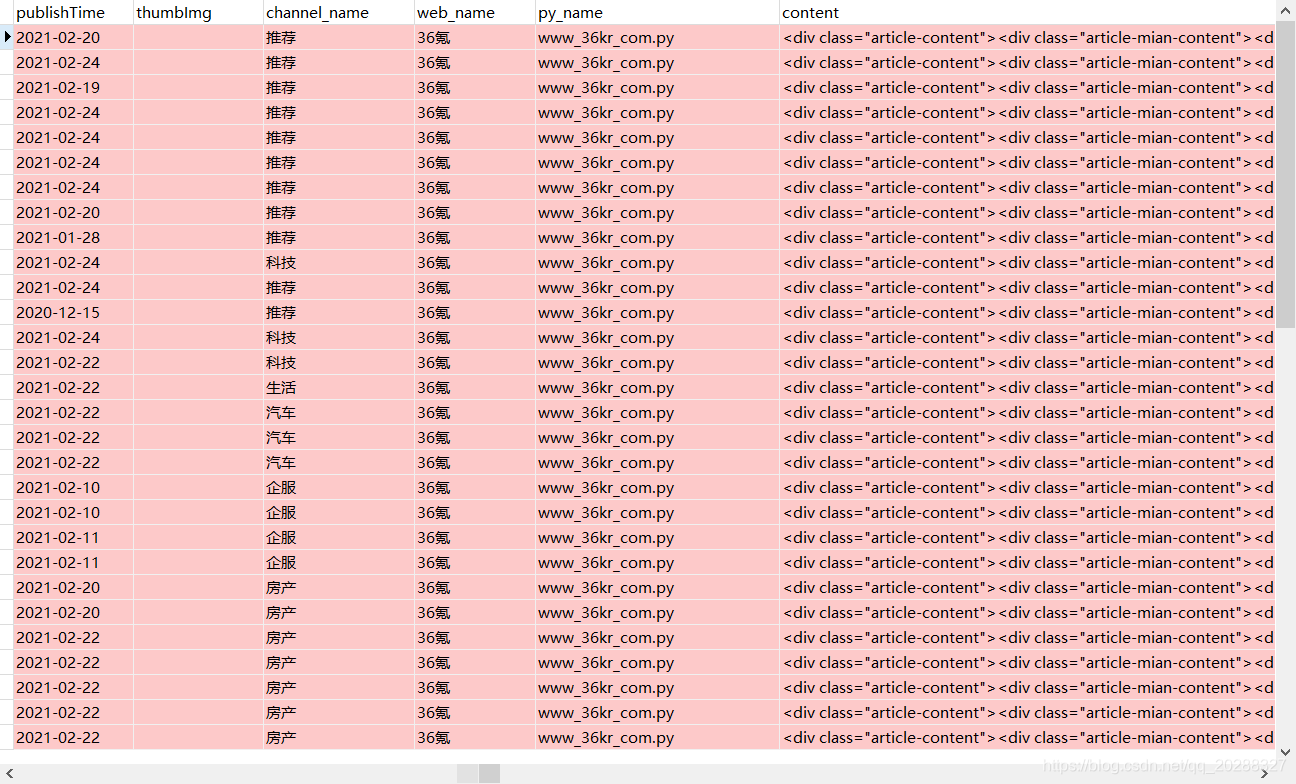
- 打开任意的link循环处理详情页的内容直到mongo命令没有筛选出来内容为止即可。