前言
数据库有重复的数据时,我们有时候需要取出时间最近的一条,来满足业务场景。 下面介绍一下通过sql是怎么实现的。一、数据准备
1. 表结构
CREATE TABLE `t_iov_help_feedback` (
`ID` int(11) NOT NULL AUTO_INCREMENT COMMENT '主键ID',
`USER_ID` int(11) DEFAULT NULL COMMENT '用户ID',
`problems` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci DEFAULT NULL COMMENT '问题描述',
`last_updated_date` timestamp NULL DEFAULT NULL ON UPDATE CURRENT_TIMESTAMP COMMENT '最后更新时间',
PRIMARY KEY (`ID`)
) ENGINE=InnoDB AUTO_INCREMENT=6 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
2. 表数据
INSERT INTO `t_iov_help_feedback`(`ID`, `USER_ID`, `problems`, `last_updated_date`) VALUES (1, 1, '时间比较小', '2021-02-23 10:11:49');
INSERT INTO `t_iov_help_feedback`(`ID`, `USER_ID`, `problems`, `last_updated_date`) VALUES (2, 2, '时间小', '2021-02-23 10:12:49');
INSERT INTO `t_iov_help_feedback`(`ID`, `USER_ID`, `problems`, `last_updated_date`) VALUES (3, 3, '我乱写的', '2021-02-23 11:19:19');
INSERT INTO `t_iov_help_feedback`(`ID`, `USER_ID`, `problems`, `last_updated_date`) VALUES (4, 1, '时间比较大', '2021-02-23 11:16:01');
INSERT INTO `t_iov_help_feedback`(`ID`, `USER_ID`, `problems`, `last_updated_date`) VALUES (5, 2, '时间大', '2021-02-23 11:19:13');
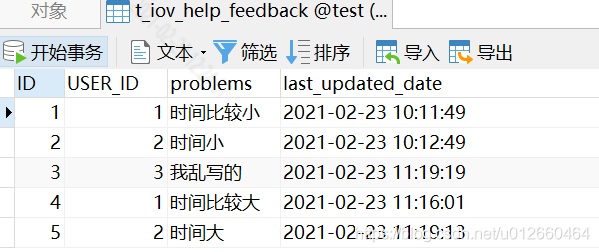
可以看到,USER_ID为1和2都有重复数据。
USER_ID为1 时间最大的条记录为 2021-02-23 11:16:01,USER_ID为2 时间最大的条记录为 2021-02-23 11:19:13。
我们希望找到时间最大的这两条记录。
二、实现方式
1.SQL模板
SELECT
t1.重复列,
t1.时间列,
t1.其余列
FROM
表 t1
INNER JOIN ( SELECT t2.重复列, max( t2.时间列 ) AS 时间列 FROM 表 t2 GROUP BY t2.重复列 ) AS t3
ON t1.重复列 = t3.重复列 AND t1.时间列 = t3.时间列
思想:
1)先把该表进行 group by 分组,并查询出每组最大的时间列,得到一个子表;
2)再将原本的表和子表通过重复列和时间列关联起来;
这样查询出来的数据,都是以原表数据为准的。既去重了,又得到了时间最大的那条记录所有字段信息。
2.SQL实现
SELECT
t1.USER_ID,
t1.last_updated_date,
t1.ID,
t1.problems
FROM
t_iov_help_feedback t1
INNER JOIN ( SELECT t2.USER_ID, max( t2.last_updated_date ) AS last_updated_date FROM t_iov_help_feedback t2 GROUP BY t2.USER_ID ) AS t3
ON t1.USER_ID = t3.USER_ID AND t1.last_updated_date = t3.last_updated_date
3.执行结果

可以看到,USER_ID为1和2的两条记录,都是取的时间比较近的那条数据。
这样,就达到想要的效果啦~