标题一、数据获取–增删改查
1、创建表
// 课程表 --主表
create table subject(
id int not null,
subject varchar(200)
);
//学生表-- 从表
create table student(
id int not null identity(1,1) primary key,//主键自增长 auto_increment/identity(1,1)
name char(20) not null,
sex char(20) not null defult 'F',
subjectid int ,
constraint stu_sub foreign key student(subjectid) references subject(id) //外键:从表引用主表
);
2、插入值
//直接插入数据
insert into table student(
id,name,sex,subject)
values(
1,'aa','F',001),
2,'bb','M',002);
//检索的数据插入新表
insert into stu_emp(
id,name,sex,subject)
select id,name,sex,subject from student;
//复制一个表到另一张表
select * into b from a;
create table b as select * from a;
//更新表
alter table a add address varchar(100);//新增一列
alter table a drop column address;//删除列
alter table a add primary key(subjectid);//设置主键
drop table a ; //删除后不可找回
3、更新数据
//更新指定数据
update student set sex ='M' , subjectid = 2 where name='aa';
//删除指定数据
delete from student where id = 1;
4、基础查询&联结
4.1多表联结
left join/right join/inner join /outer join /full ouer join
左连接以左边为准,查出左表所有数据及能够与左表匹配上的右表数据
outer join 查询左表、右表所有数据并去重,不去重用full outer join
//联结的两种方式,注意左表一条id可匹配到右表多条时,查询出来的数据量大于左表查询前的数据量。
select * from a left join b on a.id = b.id
select * from a,b where a.id =b.id
4.2 union 表格纵向拼接
select id,name,sex from a union select id,name,sex from b
4.3 条件过滤、排序、取指定行数
select subject ,count(*) from a
where name like 'a%' and sex ='F'//对行进行过滤,不可使用别名
group by subject //分组,开始可以使用别名
having count(*)>1//可对行进行过滤,也可对聚合后的数据进行过滤,可使用别名
order by subject desc//排序
limit 1,offset(2);//取指定行数,offset 从多少行开始取数
4.4 SQL语句的执行顺序
开始->FROM子句->join->on->WHERE子句->GROUP BY子句->avg、sum->HAVING子句->SELECT子句->distinct->ORDER BY子句->LIMIT子句->最终结果
二、聚合函数
除count外,聚合函数忽略空值,常与group by 一同使用。
1、常用基础聚合函数
1.1 count 计数 : count() 包含空值,count(*)不包含空值
1.2 avg() 平均值
1.3 sum()/max() /min()/stdev()/var() 加合/最大/最小/标准差/方差
1.4 count_big()返回指定组中的项目数量。count_big()返回bigint值,而count()返回的是int值。
1.5 自定义函数
Create FUNCTION AggregateString //自定义函数名
(@Id int)//传入变量
RETURNS varchar(1024) AS //返回变量
BEGIN
declare @Str varchar(1024) //申明变量
set @Str = ''
select @Str = @Str + [Name] from AggregationTable
where [Id] = @Id
return @Str
END
select dbo.AggregateString(Id),Id from AggregationTable
group by Id
三、窗口函数
<窗口函数> over ([partition by <列清单>]
order by <排序用列清单>)
窗口函数大体可以分为以下两种:
1.能够作为窗口函数的聚合函数(sum,avg,count,max,min)
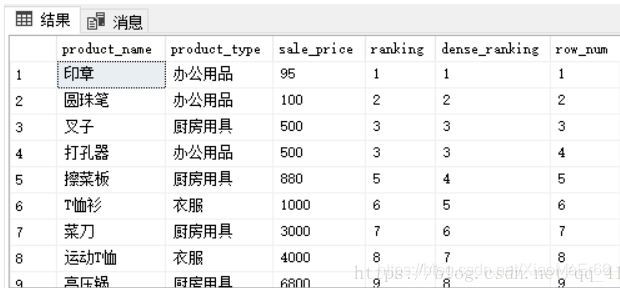
2.rank,dense_rank、row_number、leap()等专用窗口函数。
rank()如果存在相同位次记录,会跳过之后的位次。
dense_rank(),相同位次并列,不会跳过,位次连续。
select product_name, product_type, sale_price,
rank () over (order by sale_price) as ranking,
dense_rank () over (order by sale_price) as dense_ranking,
row_number () over (order by sale_price) as row_num
from Product;
四、时间函数
4.1 获取当前日期
current_date()--mysql
sysdate -- Oracle
getdate() -- sql server
4.2 dateadd 指定日期加几天
select dateadd(day,2,'2010-10-15') // --> 2010-10-17
select * from table where time between dateadd(day,-3,getdate()) and getdate() order by c_Id desc
4.3 datediff 指定日期间的时间差
select datediff(day,'2004-09-01','2004-09-18') -- > 17
4.4 datepart 返回指定日期部分
select datename(weekday, '2004-10-15') -- 返回:星期五
4.5 day()、month()、year()
select 当前日期=convert(varchar(10),getdate(),120) -- > yyyy-mm-dd 120/114 对应不同标准
,当前时间=convert(varchar(8),getdate(),114) -- > hh:mi:ss:mmm(24h)
select datename(dw,'2004-10-15')
select 本年第多少周=datename(week,'2004-10-15')
,今天是周几=datename(weekday,'2004-10-15')
更详细可参考 :https://blog.csdn.net/weixin_30338461/article/details/95578246
五、存储过程
一组为了完成特定功能的SQL语句集合,分为系统存储过程和自定义存储过程
5.1优点:
- 提高应用程序的通用性和可移植性,可重复调用
- 可以更有效的管理用户操作数据库的权限
- 可以提高SQL的速度,大量的SQL代码或分别被执行多次比单条sql 执行速度快很多。
- 减少网络流量
5.2 具体语句如下:
-- 建立无参数存储过程
create procedure p1_all
as
begin
select * from bookinfo
where publish='清华大学出版社'
end -- 执行后自动存储在存储过程中,可直接调用
execute p1_all; -- 直接调用即可
-- 有参数的存储过程
create proc p3_writer
@editor varchar(8)
as
begin
select *
from BookInfo
where Writer=@editor
end
exec p3_writer '胡伏湘' -- 调用需传入参数
六、事务
保持数据的一致性及可恢复性
begin tran -- 开启事务,transcation 的简写
declare @errorNo int --定义变量,用于记录事务执行过程中的错误次数
set @errorNo=0
begin try
update Student set C_S_Id='2' where S_StuNo='003'
set @errorNo=@errorNo+@@ERROR
select 'S_StuNo=003 已经修改啦'
update Student set C_S_Id='3' where S_StuNo='002'
set @errorNo=@errorNo+@@ERROR -- @@ERROR 系统全局变量,记录错误次数,出现一次错误 @@ERROR 值+1
select 'S_StuNo=002 已经修改啦'
if(@errorNo>0)
begin
--抛出自定义的异常,在最后的catch块中统一处理异常
RAISERROR(233333,16,3)
end
end try
begin catch
select ERROR_NUMBER() errorNumber, --错误代码
ERROR_SEVERITY() errorSeverity, --错误严重级别,级别小于10 try catch 捕获不到
ERROR_STATE() errorState, --错误状态码
ERROR_PROCEDURE() errorProcedure, --出现错误的存储过程或触发器的名称
ERROR_LINE() errorLine, --发生错误的行号
ERROR_MESSAGE() errorMessage --错误的具体信息
if(@@trancount>0) -- @@trancount 系统全局变量,事务开启 @@trancount 值+1,判断事务是否开启
begin
rollback tran; -- 回滚事务
end
end catch
if(@@trancount>0)
begin
commit tran; -- 提交事务
end
七、游标
SQL的游标是一种临时的数据库对象,既可以存放储存在数据库表中数据行的副本,也指向数据行的指针。
7.1作用:
1.遍历数据行;
2.保存查询结果,方便下文调用。概念中提到使用游标会保存数据行的副本,那么创建游标后,下文查询即可从副本中查询,要比直接查数据库快很多。
7.2创建游标:
declare cursor_name --游标名称,唯一标识
[insensitive] [scroll] cursor
for
select_statement --查询语句
[for {
read only| update [of column_name [,...n]]}]
7.3参数说明:
insensitive
告诉DBMS产生查询结果的临时副本,而不是使用指针指向数据库表中源数据。
指定insensitive时,对底层表任何改动都不会反映到游标数据中。反之,对底层表的改动都会反映到游标数据中。insensitive游标是只读的,因此不能修改其内容,也不能通过它修改底层表数据。
scroll
表明所有的提取操作,即fetch选项(具体选项在下文提到),若不指定只能进行next提取。
read only
设置游标数据只读,指定read only后,对底层表的改动不会更新其游标数据。
update [of column_name[,…n]]
定义在游标中可被更改的列。如果只指定了update,表示所有列都可以更新。
7.4FETCH语句检索数据
--创建游标
declare cursor_school scroll cursor
for
select Num,ChineseName from School order by Num
--打开游标
open cursor_school
--定义变量
declare @num bigint, @schoolname nvarchar(50)
--提取最后一行学校信息
fetch last from cursor_school into @num, @schoolname
print '学校编号:' + cast(@num as varchar) + '学校名称:' + @schoolname
--关闭游标
close cursor_school
fetch语句中,SQL Server提供了6种定位选项:
- next :返回结果集当前行的下一行,首次提取返回第一行。
- frior :返回结果集的上一行,首次提取无数据返回。
- first : 返回结果集第一行。
- last :返回结果集最后一行。
- absolute :移动到结果集的第n行。如果n为正数,从结果集的第一行(包含第一行)起移到第n行;如果n为负数,则从结果集的最后一行起移到第n行。
- relative :从游标指针的当前位置移动n行。如果n为正数,则读取游标当前位置起向后的第n行数据;如果n为负数,则读取游标当前位置起向前的第n行数据。
7.5 基于游标的定位UPDATE语句和定位DELETE语句
使用update或delete语句时要先创建游标
//update
update table_name set column_name,...
where current of cursor_name
//delete
delete from table_name
where current of cursor_name
7.6 游标关闭与释放
CLOSE(关闭)游标后不会释放其占用的数据结构。那么想要释放占用的数据结构需要用DEALLOCATE语句,该语句不仅删除游标中的数据,还会将游标作为对象从数据库中删除。
释放游标语句:
deallocate cusor_name
八、视图
是一张虚拟表,视图的字段是由我们自定义的,视图只供查询,数据不可更改,查询数据来源于我们建立的实体表。
优点:
1.简化用户操作
2.能以不同的角度观察同一个数据库
3.对重构数据库提供了逻辑独立性:
利用视图将需要的数据合并或者筛选,但是不影响原表的数据和结构
3.对机密数据提供安全保护:
可以建立不同的视图对用不同的用户,以达到安全的目的。
建立视图的语法:
Create view 视图名称[(字段1) (字段2) (字段3)…]
AS
Select 查询语句
[with check option]
-- 参数:[with check option]可选项,防止用户对数据插入、删除、更新是操作了视图范围外的基本表的数据。
-- 删除视图的语法:
Drop view 视图名称