文章目录
- 1.神经网络
-
- 1.1各个激活函数的优缺点?
- 1.2 为什么ReLU常用于神经网络的激活函数?
- 1.3 梯度消失和梯度爆炸的解决方案?梯度爆炸引发的问题?
- 1.4 如何确定是否出现梯度爆炸?
- 1.5 神经网络中有哪些正则化技术?
- 1.6 批量归一化(BN) 如何实现?作用?
- 1.7 谈谈对权值共享的理解?
- 1.8 对fine-tuning(微调模型)的理解?为什么要修改最后几层神经网络权值?
- 1.9 什么是Dropout?原理?为什么有用?它是如何工作的?
- 1.10 如何选择dropout 的概率?
- 1.11 什么是Adam?Adam和SGD之间的主要区别是什么?
- 1.12 一阶优化和二阶优化的方法有哪些?为什么不使用二阶优化?
- 1.12 为什么Momentum可以加速训练?
- 1.13 什么时候使用Adam和SGD?
- 1.14 batch size和epoch的平衡
- 1.15 SGD每步做什么,为什么能online learning?
- 1.16 学习率太大(太小)时会发生什么?如何设置学习率?
- 1.17 神经网络为什么不用拟牛顿法而是用梯度下降?
- 1.18 BN和Dropout在训练和测试时的差别?
- 1.19 若网络初始化为0的话有什么问题?
- 1.20 sigmoid和softmax的区别?softmax的公式?
- 1.21 改进的softmax损失函数有哪些?
- 1.22 调参有哪些技巧?
- 1.23 调参要往哪些方向想?
- 1.24 训练中是否有必要使用L1获得稀疏解?
- 1.25 数据预处理方法有哪些?
- 1.26 如何初始化神经网络的权重?神经网络怎样进行参数初始化?
- 1.27 为什么构建深度学习模型需要使用GPU?
- 1.28 前馈神经网络(FNN),递归神经网络(RNN)和 CNN 区别?
- 1.29 神经网络可以解决哪些问题?
- 1.30 如何提高小型网络的精度,同时尽量不损失压缩模型?
- 1.31 列举你所知道的神经网络中使用的损失函数
- 1.32 什么是鞍点问题?
- 1.33网络设计中,为什么卷积核设计尺寸都是奇数?
1.神经网络
1.1各个激活函数的优缺点?
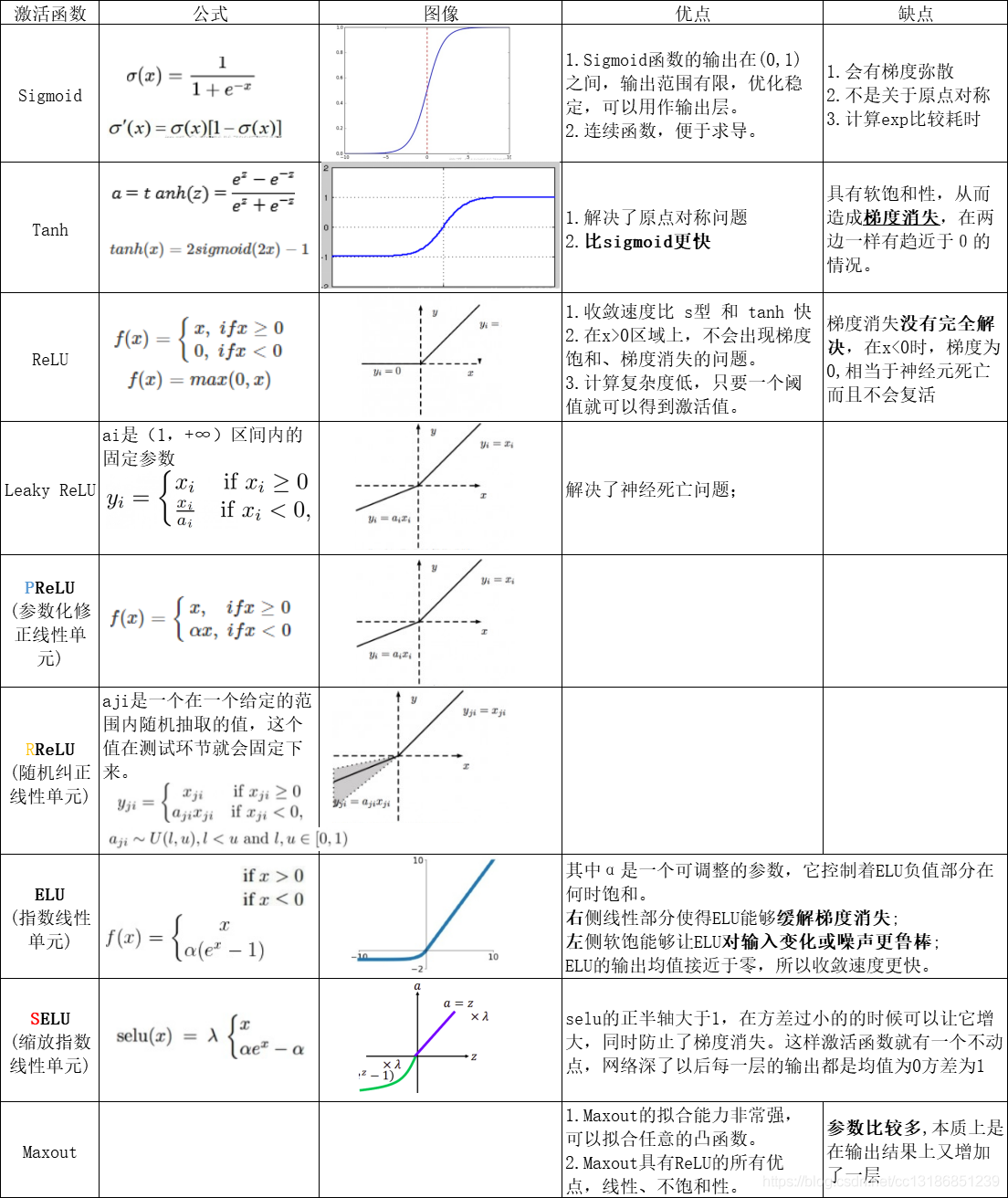
激活函数的选择顺序:
SELU>ELU>Leaky Relu及其变体>Relu>tanh>sigmoid
1.2 为什么ReLU常用于神经网络的激活函数?
1.在前向传播和反向传播过程中,ReLU相比于Sigmoid等激活函数计算量小;
2.避免梯度消失问题。对于深层网络,Sigmoid函数反向传播时,很容易就会出现梯度消失问题(在Sigmoid接近饱和区时,变换太缓慢,导数趋于0,这种情况会造成信息丢失),从而无法完成深层网络的训练。
3.可以缓解过拟合问题的发生。Relu会使一部分神经元的输出为0,这样就造成了网络的稀疏性,并且减少了参数的相互依存关系,缓解了过拟合问题的发生。
4.相比Sigmoid型函数,ReLU函数有助于随机梯度下降方法收敛。
为什么需要激活功能?
激活函数是用来加入非线性因素的,因为线性模型的表达能力不够。
1.3 梯度消失和梯度爆炸的解决方案?梯度爆炸引发的问题?
梯度消失:靠近输出层的hidden layer 梯度大,参数更新快,所以很快就会收敛;
而靠近输入层的hidden layer 梯度小,参数更新慢,几乎就和初始状态一样,随机分布。
另一种解释:当反向传播进行很多层的时候,由于每一层都对前一层梯度乘以了一个小数,因此越往前传递,梯度就会越小,训练越慢。
梯度爆炸:前面layer的梯度通过训练变大,而后面layer的梯度指数级增大。
①在深度多层感知机(MLP)网络中,梯度爆炸会引起网络不稳定,最好的结果是无法从训练数据中学习,而最坏的结果是出现无法再更新的 NaN 权重值。
②在RNN中,梯度爆炸会导致网络不稳定,无法利用训练数据学习,最好的结果是网络无法学习长的输入序列数据。

1.4 如何确定是否出现梯度爆炸?
模型不稳定,导致更新过程中的损失出现显著变化;
训练过程中模型梯度快速变大;
训练过程中模型权重变成 NaN 值;
训练过程中,每个节点和层的误差梯度值持续超过 1.0。
1.5 神经网络中有哪些正则化技术?
L2正则化(Ridge);
L1正则化(Lasso);
权重衰减;
丢弃法;
批量归一化;
数据增强;
早停法
对于所有权重,权重衰减方法都会为loss func 加上½λw2
1.6 批量归一化(BN) 如何实现?作用?
实现过程: 计算训练阶段mini_batch数量激活函数前结果的均值和方差,然后对其进行归一化,最后对其进行缩放和平移。
对每一个mini-batch数据的内部进行标准化处理吧使输出规范到N(0,1)的正态分布。
作用:
1.可以使用更高的学习率进行优化;
2.减少(取消)dropout;
3.降低L2权重衰减系数;起到正则化作用,简化网络结构。
4.调整了数据的分布,不考虑激活函数,它让每一层的输出归一化到了均值为0方差为1的分布,这保证了梯度的有效性,可以解决反向传播过程中的梯度问题。
moving-mean 计算:0.1当前均值 + 0.9上次训练的均值
1.6.1 BN为什么防止过拟合?
在训练中,BN的使用使得一个mini-batch中的所有样本都被关联在了一起,因此网络不会从某一个训练样本中生成确定的结果。
1.7 谈谈对权值共享的理解?
权值共享这个词是由LeNet5模型提出来的。以CNN为例,在对一张图偏进行卷积的过程中,使用的是同一个卷积核的参数。
比如一个3×3×1的卷积核,这个卷积核内9个的参数被整张图共享,而不会因为图像内位置的不同而改变卷积核内的权系数。
通俗说:就是用一个卷积核不改变其内权系数的情况下卷积处理整张图片。
1.8 对fine-tuning(微调模型)的理解?为什么要修改最后几层神经网络权值?
使用预训练模型的好处:在于利用训练好的SOTA模型权重去做特征提取,可以节省我们训练模型和调参的时间。
理由:
1.CNN中更靠近底部的层(定义模型时先添加到模型中的层)编码的是更加通用的可复用特征,而更靠近顶部的层(最后添加到模型中的层)编码的是更专业化的特征。微调这些更专业化的特征更加有用,它更代表了新数据集上的有用特征。
2.训练的参数越多,过拟合的风险越大。很多SOTA模型拥有超过千万的参数,在一个不大的数据集上训练这么多参数是有过拟合风险的,除非你的数据集像Imagenet那样大。
1.9 什么是Dropout?原理?为什么有用?它是如何工作的?
背景:如果模型的参数太多,数据量又太小,则容易产生过拟合。为了解决过拟合,就同时训练多个网络。然后多个网络取均值。费时!
介绍:Dropout可以防止过拟合,在前向传播的时候,让某个神经元的激活值以一定的概率 P停止工作,这样可以使模型的泛化性更强。
原理:可以把dropout看成是一种集成方法,每次做完dropout相当于从原网络中找到一个更瘦的网络。
强迫神经元和其他随机挑选出来的神经元共同工作,减弱了神经元节点间的联合适应性,增强泛化能力,使用dropout得到更多的局部簇,同等数据下,簇变多了,因而区分性变大,稀疏性也更大。
Dropout效果跟bagging效果类似(bagging是减少方差variance,而boosting是减少偏差bias)。
加入dropout会使神经网络训练时间长,模型预测时不需要dropout,记得关掉。
具体流程:
i.随机删除(临时)网络中一定的隐藏神经元,输入输出保持不变,
ii.让输入通过修改后的网络。然后把得到的损失同时修改后的网络进行反向传播。在未删除的神经元上面进行参数更新
iii.重复该过程(恢复之前删除掉的神经元,以一定概率删除其他神经元。前向传播、反向传播更新参数)
1.10 如何选择dropout 的概率?
input 的 dropout 概率推荐是 0.8, hidden layer 推荐是0.5
为什么dropout可以解决过拟合?
1.取平均的作用:
Dropout产生了许多子结构之后的操作,父神经网络有N个节点,加入Dropout之后可以看做在权值不变的情况下(参数共享)将模型数量扩增到指数级别
2.减少神经元之间复杂的共适应关系,迫使网络去学习更加鲁棒;
Dropout 在训练和测试的区别?
训练时随机删除一些神经元,在测试模型时将所有的神经元加入。
1.11 什么是Adam?Adam和SGD之间的主要区别是什么?
1.12 一阶优化和二阶优化的方法有哪些?为什么不使用二阶优化?
一阶优化方法有:
SGD -> SGDM ->NAG -> AdaGrad -> AdaDelta / RMSProp(加速梯度下降) -> Adam -> Nadam
动量优化法: Momentum、NAG
自适应学习率优化算法主要有:AdaGrad,AdaDelta,RMSProp,Adam,Nadam
二阶优化
定义:对目标函数进行二阶泰勒展开,也就是二阶梯度优化方法
牛顿法 + BFGS法
利用二阶泰勒展开,即牛顿法需要计算Hessian矩阵的逆,计算量大,在深度学习中并不常用。因此一般使用的是一阶梯度优化。

Adam算法步骤:
更新step --> 计算梯度 --> 计算一阶矩的估计(即mean )–> 计算二阶距的估计(即var) --> 对mean和var进行校正,因为mean和var的初始值为0 --> 梯度下降。注意alpha后的梯度是用一阶距和二阶距估计的。
torch.optim.SGD(net_SGD.parameters(), lr=LR)
torch.optim.SGD(net_Momentum.parameters(), lr=LR, momentum=0.8)
torch.optim.RMSprop(net_RMSprop.parameters(), lr=LR, alpha=0.9)
torch.optim.Adam(net_Adam.parameters(), lr=LR, betas=(0.9,0.99)) β1 β2
1.12 为什么Momentum可以加速训练?
原理:在GD梯度下降算法中引入指数加权平均数,在更新梯度方向的过程中,在一定程度上保留了之前梯度更新的方向,同时利用当前mini_batch的梯度方向微调最终的更新方向。
动量其实累加了历史梯度更新方向,所以在每次更新时,要是当前时刻的梯度与历史时刻梯度方向相似,这种趋势在当前时刻则会加强;要是不同,则当前时刻的梯度方向减弱。动量方法限制了梯度更新方向的随机性,使其沿正确方向进行。
1.13 什么时候使用Adam和SGD?
Adam等自适应学习率算法对于稀疏数据具有优势,且收敛速度很快;
但精调参数的SGD(+Momentum)往往能够取得更好的最终结果
Adam+SGD 组合策略:先用Adam快速下降,再用SGD调优。
如果模型是非常稀疏的,那么优先考虑自适应学习率的算法;
在模型设计实验过程中,要快速验证新模型的效果,用Adam进行快速实验优化;
在模型上线或者结果发布前,可以用精调的SGD进行模型的极致优化。
1.14 batch size和epoch的平衡
Adam: 不需要调lr;
SGD: 多花时间调lr 和initial weights.

1.15 SGD每步做什么,为什么能online learning?
online learning强调的是学习是实时的,流式的,每次训练不用使用全部样本,而是以之前训练好的模型为基础,每来一个样本就更新一次模型,这种方法叫做OGD(online gradient descent),目的是快速地进行模型的更新,提升模型时效性。而SGD的思想正是在线学习的思想。
1.16 学习率太大(太小)时会发生什么?如何设置学习率?
1.基于经验的手动调整
通过尝试不同的固定学习率,如3、1、0.5、0.1、0.05、0.01、0.005,0.0001等,观察迭代次数和loss的变化关系,找到loss下降最快关系对应的学习率。
太小,收敛过程将变得十分缓慢;
太大,梯度可能会在最小值附近来回震荡(loss爆炸),甚至可能无法收敛。
2. 基于策略的调整
①fixed 、exponential、polynomial
②自适应动态调整。adadelta、adagrad、ftrl、momentum、rmsprop、sgd
Logit:对它取对数。
 Logit:对它取对数。
Logit:对它取对数。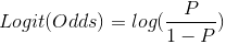
1.17 神经网络为什么不用拟牛顿法而是用梯度下降?
牛顿法: 二阶优化算法是寻找梯度为0的点
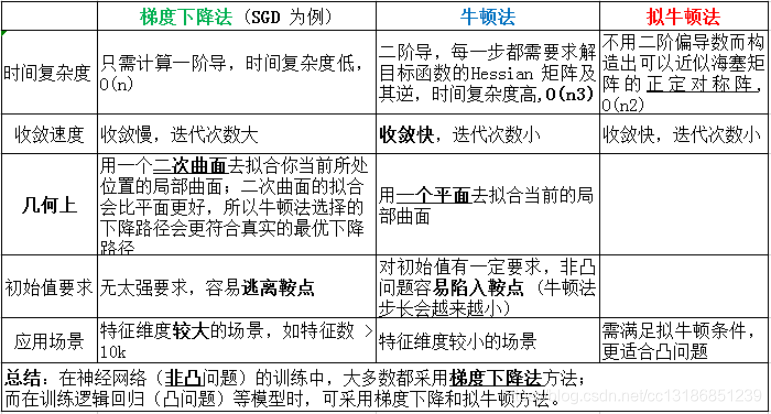
牛顿法原理:使用函数f(x)的泰勒级数的前面几项来寻找方程f(x)= 0的根。
1.18 BN和Dropout在训练和测试时的差别?
BN:
训练时:是对每一个batch的训练数据进行归一化,也即是用每一批数据的均值和方差。
测试时:都是对单个样本进行测试。这个时候的均值和方差是全部训练数据的均值和方差,这两个数值是通过移动平均法求得。
当一个模型训练完成之后,它的所有参数都确定了,包括均值和方差,gamma和bata。
Dropout:只有在训练的时候才采用,是为了减少神经元对部分上层神经元的依赖,类似将多个不同网络结构的模型集成起来,减少过拟合的风险。
1.19 若网络初始化为0的话有什么问题?
w初始化全为0,很可能直接导致模型失效,无法收敛。
1.20 sigmoid和softmax的区别?softmax的公式?

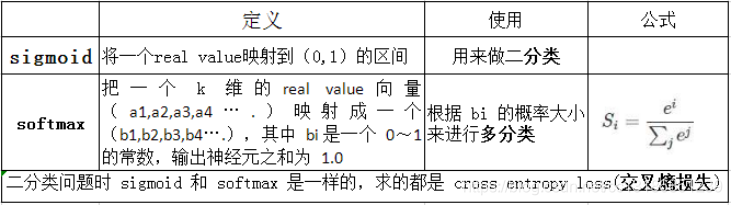
1.21 改进的softmax损失函数有哪些?
1.Large Margin Softmax Loss (L-Softmax)
加了一个margin,要保证大于某一个阈值。这样可以尽量实现让类间间距更大化,类内距离更小。
2.Center Loss
通过将特征和特征中心的距离和softmax loss一同作为损失函数,使得类内距离更小,有点L1,L2正则化。
1.22 调参有哪些技巧?
1.准备数据
1.1 保证有大量、高质量并且带有干净标签的数据;
1.2 样本要随机化,防止大数据淹没小数据;尽量对数据shuffle;
1.3 样本要做归一化.
2.预处理
0均值和1方差化
3.minibatch
建议值128,不要用过大的数值,否则很容易过拟合
4.梯度归一化
其实就是计算出来梯度之后,要除以minibatch的数量。
5.梯度剪切
6.学习率
6.1 用一个一般的lr开始,然后逐渐的减小它;
6.2 建议值是0.01,适用于很多NN的问题,一般倾向于小一点;
6.3 对于调度学习率的建议:如果在验证集上性能不再增加就让学习率除以2或者5,然后继续,学习率会一直变得很小,到最后就可以停止训练了。
6.4 很多人用的一个设计学习率的原则就是监测一个比率(范数和权值范数之间的比率),如果这个比率在10-3附近,如果小于这个值,学习会很慢,如果大于这个值,那么学习很不稳定,由此会带来失败。
7.权重初始化的选择
7.1 用高斯分布乘上一个很小的数
7.2 在深度网络中,随机初始化权重,使用SGD的话一般处理的都不好,这是因为初始化的权重太小了。这种情况下对于浅层网络有效,但是当足够深的时候就不行了,因为weight更新的时候,是靠很多weight相乘的,越乘越小,有点类似梯度消失。

8.训练RNN或LSTM
如果训练RNN或者LSTM,务必保证gradient的norm被约束在15或者5(前提还是要先归一化gradient),这一点在RNN和LSTM中很重要。
如果使用LSTM来解决长时依赖的问题,针对遗忘门bias的用1.0或更大一点。
9.优化器
Adam收敛速度的确要快一些,可结果往往没有sgd + momentum的解好(如果模型比较复杂的话,sgd是比较难训练的,这时候用adam较好);
若使用sgd,lr=0.1/1.0,隔一段时间,在验证集上检查,cos未下降,lr减半。
10.数据增强
尽可能想办法多的扩增训练数据,如果使用的是图像数据,不妨对图像做一点扭转之类的操作,来扩充数据训练集合。
11.使用dropout
CNN: full层部分使用,conv层不使用,设为0.5,小数据上用dropout+sgd效果更明显。
RNN: 在上下层连接时使用。
1.early stop,发现val_loss没更新,就尽早停止。
2.评价最终结果的时候,多做几次,然后平均一下他们的结果。
1.23 调参要往哪些方向想?
损失函数的选择是否是合适的
学习率的选取是否合适
batch size选择是否合适
训练样本是否正常,是否需要增强
是否有设置batch normlaztion(数据归一化)
激活函数的类型需要选取恰当
选取合适的优化算法(例如梯度下降,Adam等)
是否存在过拟合
a.Early Stopping
b. Regularization(正则化)
c. Weight Decay(收缩权重)
d. Dropout(随机失活)
e. 调整网络结构
1.24 训练中是否有必要使用L1获得稀疏解?
没必要。对于加了L1正则的神经网络,大部分深度学习框架自带的优化器训练获得不了稀疏解;如果稀疏解的模式是无规律的,这种稀疏意义不大。
1.25 数据预处理方法有哪些?
中心化/零均值,归一化
1.26 如何初始化神经网络的权重?神经网络怎样进行参数初始化?
a:将所有的参数初始化为0
b:对w随机初始化
c: Xavier初始化:尽可能的让输入和输出服从相同的分布,这样就能够避免后面层的激活函数的输出值趋向于0
d: 何氏初试法
如果权重初始化太小,会导致神经元的输入过小,随着层数的不断增加,会出现信号消失的问题;也会导致sigmoid激活函数丢失非线性的能力,因为在0附近sigmoid函数近似是线性的。如果参数初始化太大,会导致输入状态太大。
对sigmoid激活函数来说,激活函数的值会变得饱和,从而出现梯度消失的问题。
1.27 为什么构建深度学习模型需要使用GPU?
VGG16(在DL应用中经常使用16个隐藏层的卷积神经网络)大约具有1.4亿个参数,又称权重和偏见。如果用传统的方法,训练这种系统需要几年的时间。
神经网络的计算密集部分由多个矩阵乘法组成,可以简单地通过同时执行所有操作,而不是一个接一个地执行,要使用GPU(图形处理单元)而不是CPU来训练神经网络。
1.28 前馈神经网络(FNN),递归神经网络(RNN)和 CNN 区别?
FNN 是指在一个vector内部的不同维度之间进行一次信息交互。
CNN是以逐次扫描的方式在一个vector的局部进行多次信息交互。
RNN就是在hidden state上增加了loop,看似复杂,其实就是从时间维度上进行了展开。是在不同时刻的多个vectors之间进行信息交互。
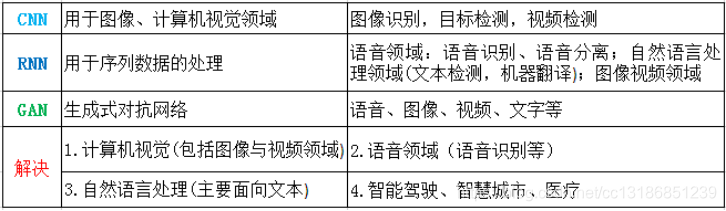
1.29 神经网络可以解决哪些问题?
1.30 如何提高小型网络的精度,同时尽量不损失压缩模型?
1.模型参数量化:将float32型权重、激活映射到低bit位(int8、fp16,二值、三值…)存储
2.模型剪枝
3.知识蒸馏
4.替换轻量化网络结构(mobilenet系列、shufflenet、squeezenet…)
1.30.1 模型剪枝常用策略?
层剪枝,根据bn层的gamma系数剪枝,bn层的gamma系数代表该层特征的方差,方差越大说明该层特征越明显,保留该层,gamma系数小的网络层可以剪掉。
通道剪枝,根据经验缩小通道系数,多次训练对比实验
1.31 列举你所知道的神经网络中使用的损失函数
欧氏距离,交叉熵,对比损失,合页损失
1.32 什么是鞍点问题?
梯度为0,海森矩阵不定的点,不是极值点。
1.33网络设计中,为什么卷积核设计尺寸都是奇数?
① 保证像素点中心位置,避免位置信息偏移
② 填充边缘时能保证两边都能填充,原矩阵依然对称