1、核函数
- 将样本值映射到高维空间,使得非线性不可分的问题可分。如高斯核函数
- 解决内积产生过大的时间复杂度的问题
面试题:
1)为什么在SVM中应用核函数?
- 对于线性不可分的数据,需要把它映射到高维空间,使它线性可分
- 对于svm的目标函数,有内积项,如果映射增加degree,会使得时间复杂度特别大。
2)有哪些常见的核函数:
- 线性核
- 多项式核函数
- 高斯核函数
- sigmoid核函数
3)如何在svm中选择核函数?
- 如果特征的数量大到和样本数量差不多,使用LR或者线性svm
- 如果特征的数量小,样本的数量正常,使用高斯核svm
- 如果特征数量小,而样本数量巨大,需要手动添加一些特征。
2、变分法 Variational Inference
是一个优化型得算法。是一个bias的算法。使用更简单的方式去替代后验概率。
Gibbs sampling(MCMC)是 unbias 的
随着采样的数量越多,会得到真正正确的答案。
2.1 Introduction
如果对于隐变量的条件概率很难计算,那么可以选择一个新的后验概率替换。
最理想的状态是p=q

因为实际上q不可能完全等于p,所以是bias的
问题:p(z|x, α \alpha α)=======>q(z| α \alpha α)
对于两个分布,希望新的分布和原来的分布相似度越来越高。使用KL散度
如何估计两个分布的相似度:
- KL divergence
- Wasserstin distance
- 卷积
2.2 KL divergence

2.3 如何定义目标函数:ELMO+p(x)
简化kl散度的计算公式:

Elmo:前两项:
最小化kl散度意味着最大化ELMO部分的值
加粗样式

使用jenson不等式:

期望的函数值小于函数的期望。
最大化p(x)就是最大化它的lower bound,elmo是p(x)的lower bound
2.4 变分法——LDA

LDA flow chart:

超参数(无需参与计算)是和每个文档每个单词是已知的
文档和主题的关系,主题和词的性质,每个词在每篇文档中对应的主题是未知的
根据贝叶斯网络的条件性质,拆分:
第一部分

对于 θ , ϕ , z i , j \theta,\phi,z_{i,j} θ,ϕ,zi,j的超参数进行定义:

第二部分,是用新定义的超参数把q(z)拆开

2.5 重写LDA目标函数
重写新的目标函数:

可以使用coordinate descent 对于每个隐状态分别进行优化。

拆分目标函数:
1)先关注z和 θ \theta θ之间的关系
服从多项式分布

2)关注于在q下,z和 ϵ \epsilon ϵ

3) 关注 θ \theta θ和 α \alpha α
遵从dir 分布

4)关注在q分布下的 θ \theta θ:
服从dir分布

5)关注 ϕ \phi ϕ在p和q分布中的概率分布:
也可以转换为遍历所有文档后,隐变量的log gamma参数+对log dirichilet分布求期望的加和。
将七个项相加得到:

优化目标函数
分别对q分布中的三个超参数求偏导
1)对 θ \theta θ的超参数求导:
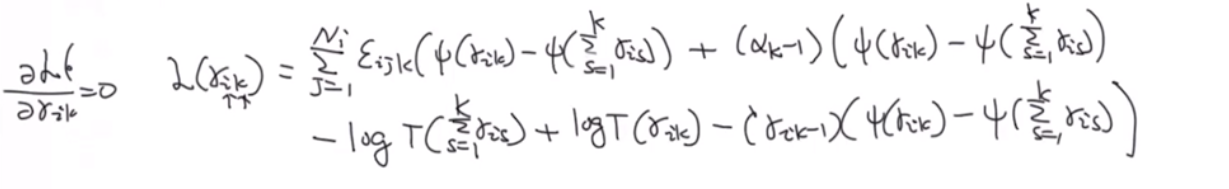

2)对于Z的超参数求导:
提取所有与 ϵ \epsilon ϵ相关的项:
需要加入拉格朗日乘子项

3)对于 ϕ \phi ϕ的超参数求导:

三个超参数的汇总:

直到收敛为止
问题:时间复杂度很高
解决:SVI

直到局部的参数收敛,再更新全局参数