在前面的要素渲染——地理数据可视化之道中详细介绍了QGIS的10种要素渲染方式,其中,渐进渲染(Graduated)是数值型字段分析的常用可视化方法。
渐进渲染的前提是选择合适的数据分类模式,QGIS提供优雅分段、对数尺度、标准差、等数量(分位数)、等间隔、自然间断点 6种分级模式,选择不同分级模式将影响到落入每个等级的要素数量,进而影响到地图的表达效果。
ArcMap作为行业成熟的商用GIS软件,在符号化方面做得非常全面,定量数据可以按照分级颜色或者分级符号进行可视化,提供手动分类、相等间隔(同QGIS的等间隔)、自定义的间隔、分位数、自然间断点分级法(Jerks)、几何间隔、标准差 7种分类方法。
其中,二者共有的数据分类方式为:等间距、分位数、自然间断点和标准偏差。本文将从中断点异同、实现逻辑差异、分类结果的可视化表达三个方面比较两个软件分类效果的异同,为数据分类可视化表达提供参考。
01 示范数据
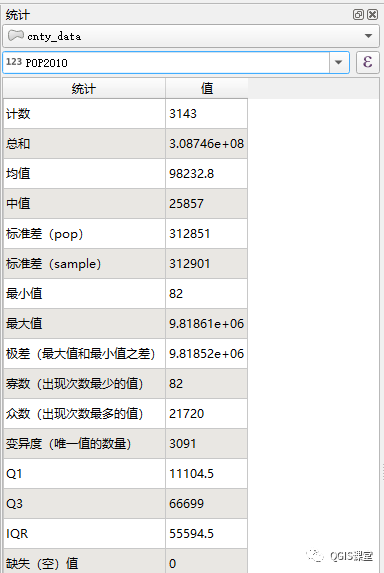
本文选择美国县级2010年人口作为演示,剔除无数据的县,以分5个类别为例,对分类效果进行比较。
数据的情况如下:
02 等间距分段
等间距是以字段的最大值和最小值为依据将数据分为间距相等的组。
分别在ArcGIS和QGIS使用等间距将Pop2010分为5类,结果如下:
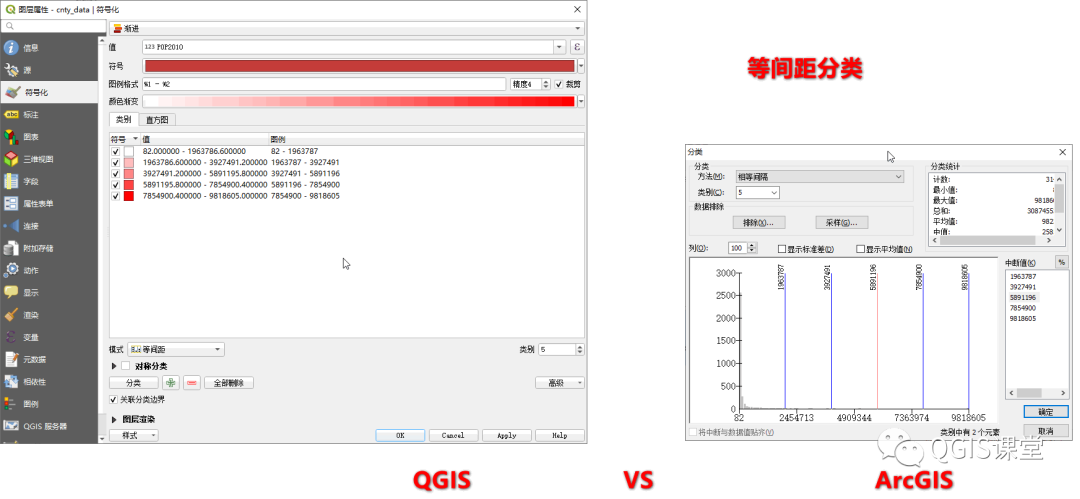
由上图可见,QGIS和ArcGIS的等间距分类方式得到的分组断点完全相同,分组断点的计算方式为:
示范数据Pop2010中,最大值为9818605,最小值为82,那么,组间距为:(9818605-82)/5=1963704.6,所以从小到大的第一个数据中断点为最小值加上组间距:82+1963704.6=1963787,第二个中断点为最小值加上2倍组间距:82+2*1963704.6=3927491.2,以此类推求出其他断点,各个分组的区间如下:
第一组:82 – 1963787 [3131]——括号内的数字表示共3131个要素在此范围;
第二组:1963787 – 3927491 [9];
第三组:3927491 – 5891196 [2];
第四组:5891196 – 7854900 [0];
第五组:7854900 – 9818605 [1]。
直方图查看一下数据分布情况:

用颜色渐变将分类效果渲染到地图上:
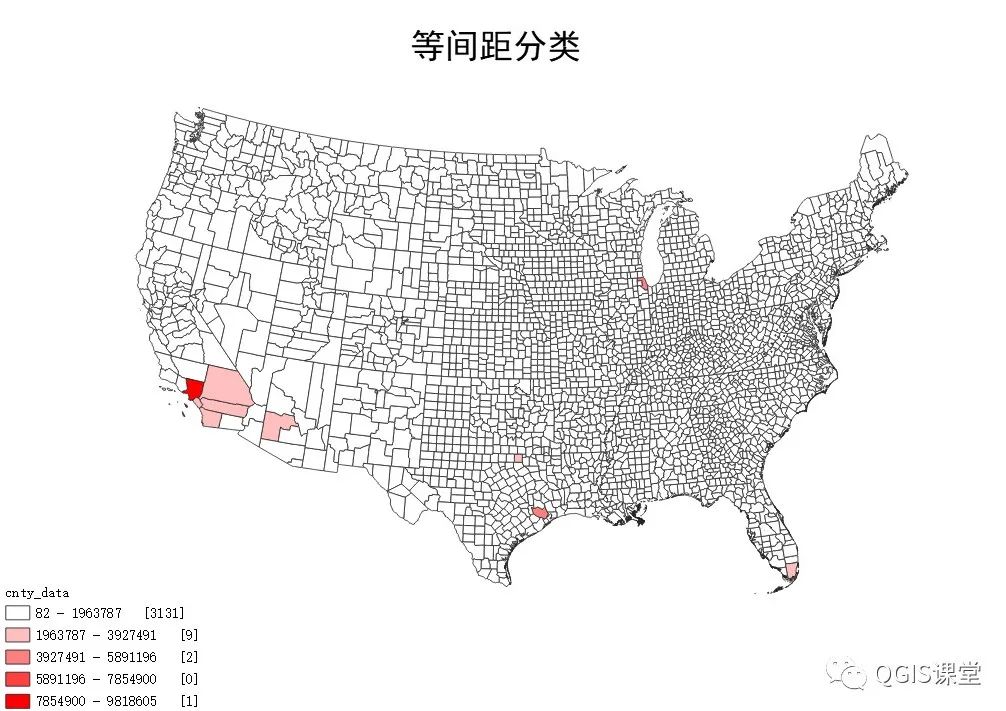
等间距分类计算过程简单易懂,适用于表现随刻度均匀分布的数据,但是其缺点也显而易见:对于数据分布不均匀的情况表现不强(有些分组聚集了大量的要素,有些分组的要素为0个)。从直方图和地图可以看出,绝大多数的县落入第一组范围,其他组的数量几乎可以忽略,导致看不出数据分布规律,因此对于所使用的示范数据而言,等距离分类并不能为数据分析提供有效的解读信息。
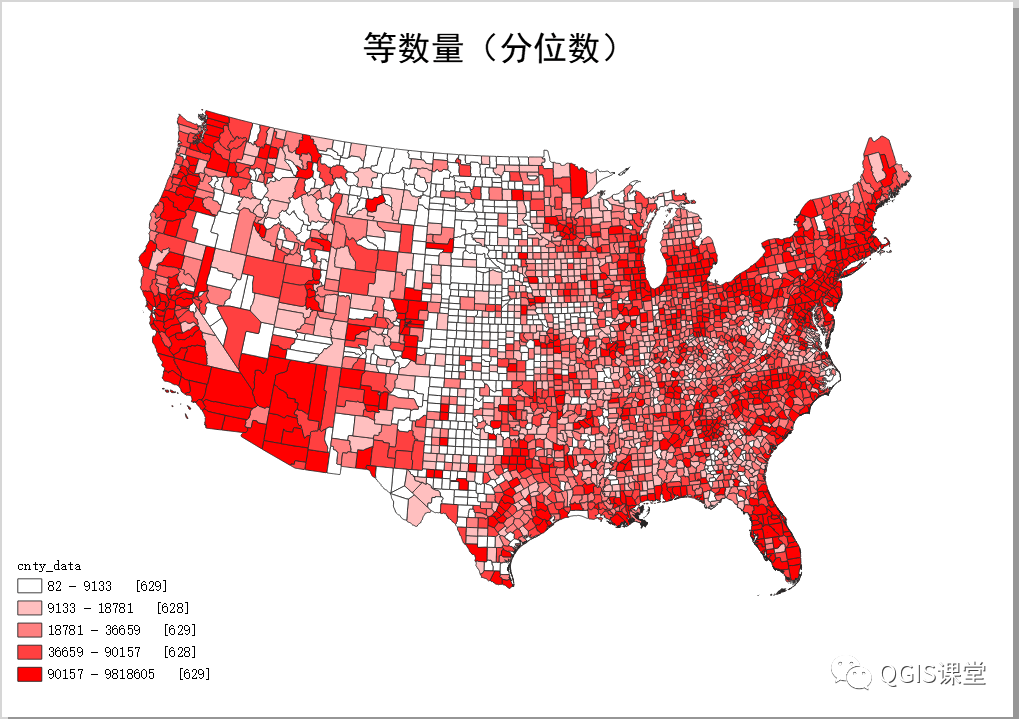
03 等数量(分位数)
分位数分类力图使每个分组有相同数量的要素,分位数分类不存在空类,也不存在过多或过少的类,非常适用于呈线性分布的数据。
分别在ArcGIS和QGIS使用分位数将Pop2010分为5类,结果如下:
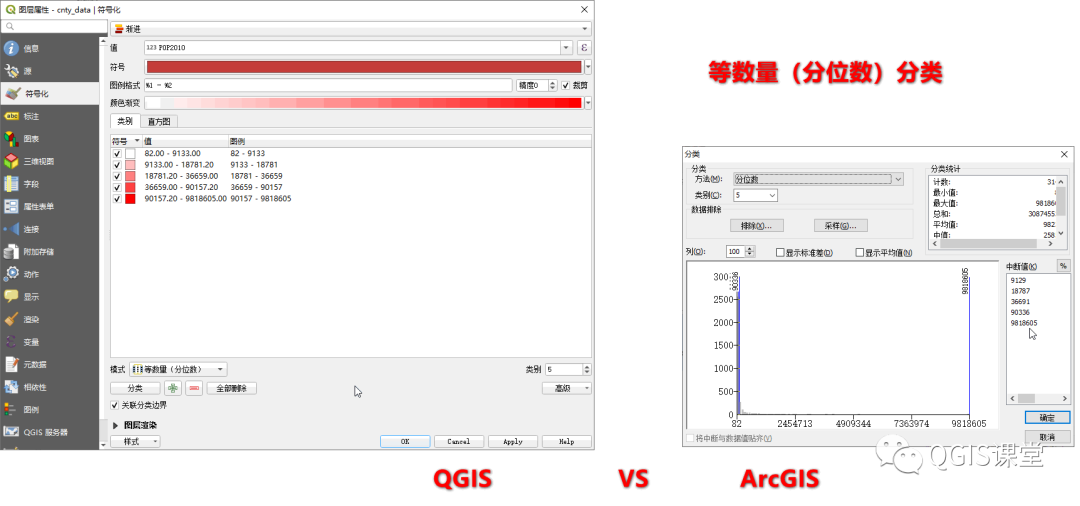
可以看到,QGIS与ArcGIS分类的断点有细微的差别(括号内的数字为落入该区间的要素数量):
由于分位数分组的目的是尽量使得每个分组内要素数量相等,可以得出其断点计算方式为:先用要素总数除以分类数求每个类别的要素数量,将要素按从小到大排序后,根据每组数量取得分组断点。
以本示范数据为例,要素总数为3143,分类数为5,那么每个分组内要素的数量为3143/5= 628.6。显然,3143并不能被5整除,因此无法做到每个分组绝对数量,将出现3个分组有629个县,2个分组为628个县的情况。
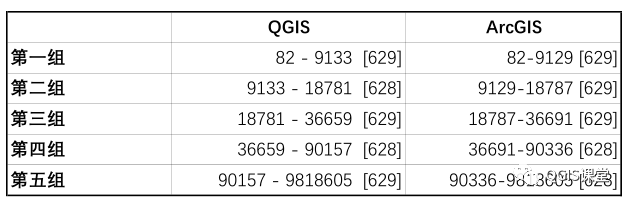
QGIS采用交替取629、628进行分组,即第一组分得629个县,第二组分得628个县,以此类推;而ArcGIS采用先将三组629个县分完,再分2个628的县,所以导致两个软件计算出的断点出现差异,所影响到的县为:
Haywood县2010年人口数为18787,在QGIS中被归入第三组,在ArcGIS中属于第二组;
Dodge县2010年人口数为36691,在QGIS中被归入第四组组,在ArcGIS中属于第三组;
Campbell县2010年人口数为90336,在QGIS中被归入第五组组,在ArcGIS中属于第四组。
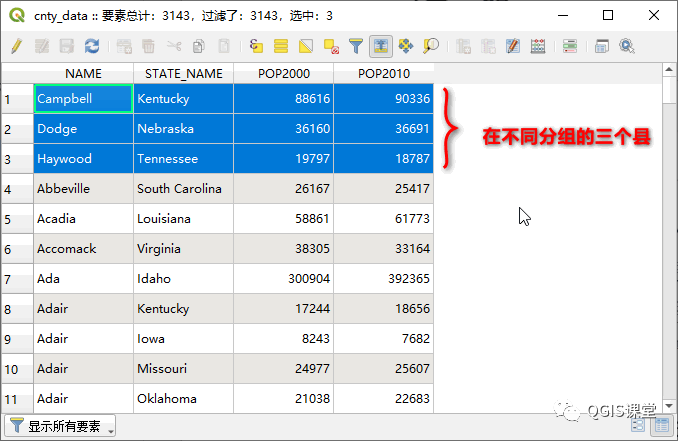
由于每组要素的数量几乎相等,因此分位数分组的地图颜色表现得相对比较均衡,但是对于数据呈现跳跃增加的情况,分位数分类将对地图读者产生误导:人们习惯于将相同颜色归入同一个类别,而实际上两个数可能相差很远。
以本例中分组结果为例,第五组的下界限为90157,上界限为9818605,两个数之间相差非常大,归入同一个类别容易让人以为它们的人口数量差异不大。
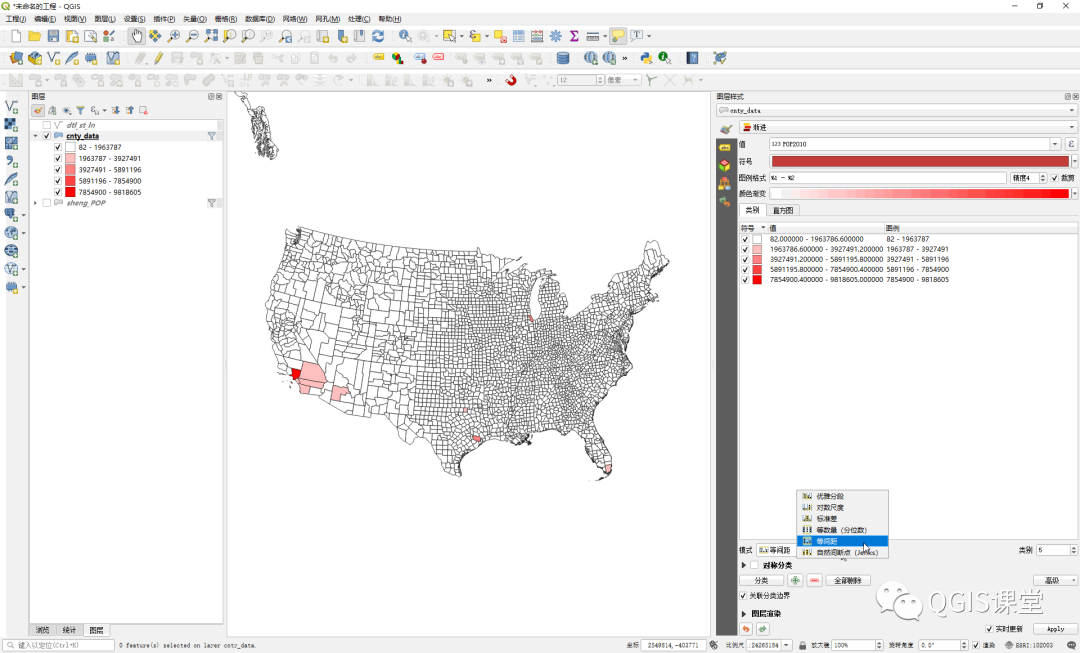
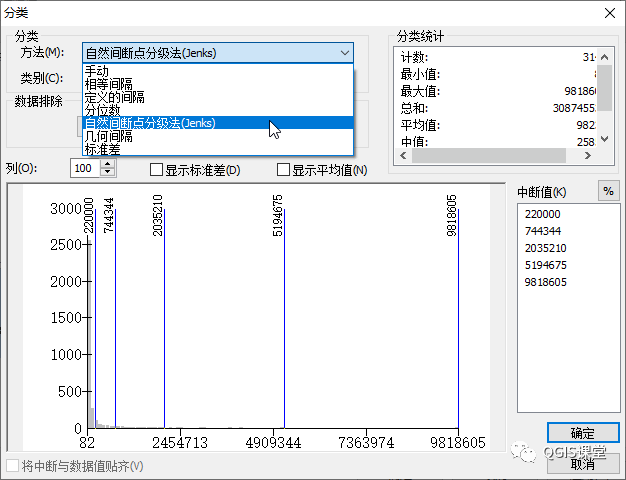
04 自然间断点分级法(Jenks)
自然间断点分级法(Jenks)是一种数据聚类方法,通过最小化每个类别内的平均偏差,同时最大化每个类别与其他类别平均偏差来实现不同类别的最佳分组,换句话说,该方法寻求减小类别内的差异并使类别之间的差异最大化。[1]
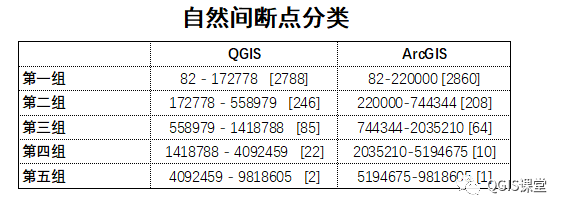
分别在ArcGIS和QGIS使用自然间断点分级法(Jenks)将Pop2010分为5类,结果如下:

可以看到,使用自然间断点分类,QGIS和ArcGIS的中断点差异非常大(括号内的数字为落入该区间的要素数量):
为了理解差异产生的原因,我们先看看自然断点分类的计算过程:
1) 根据分类数量(class=5),将数值随机分成5类;
2) 计算每个类别的方差;
3) 找到各类别方差的最大值和最小值;
4) 将方差最大值的类别向最小值类别方向移动一个数值;
5) 再次计算方差;
6) 重复2-5步,直到类别方差的变化小于设定的阈值或者达到最大迭代次数。
根据QGIS的源代码,自然断(Jenks)法的代码参考了R语言classInt包的实现方式,结合Python和Java的实现方式做了修正,特别是在要素个数大于3000个时,QGIS将会对要素进行随机采样,形成一个小的样本,然后在该样本内计算断点。
根据Geospatial Analysis—A Comprehensive Guide[2]中对Natural breaks (Jenks)算法的解释,ArcGIS中Natural breaks (Jenks)的计算步骤基本与QGIS相同,但是ArcGIS的步骤中并未提到数据量大时会进行重采样。
另外,无论是QGIS还是ArcGIS,对于自然断点分段法均不保证能找到最优解,也就是说分类断点不唯一,间接说明了两个软件对同一个数据分类出现差异的原因。
自然断点分类法的地图可视化效果:
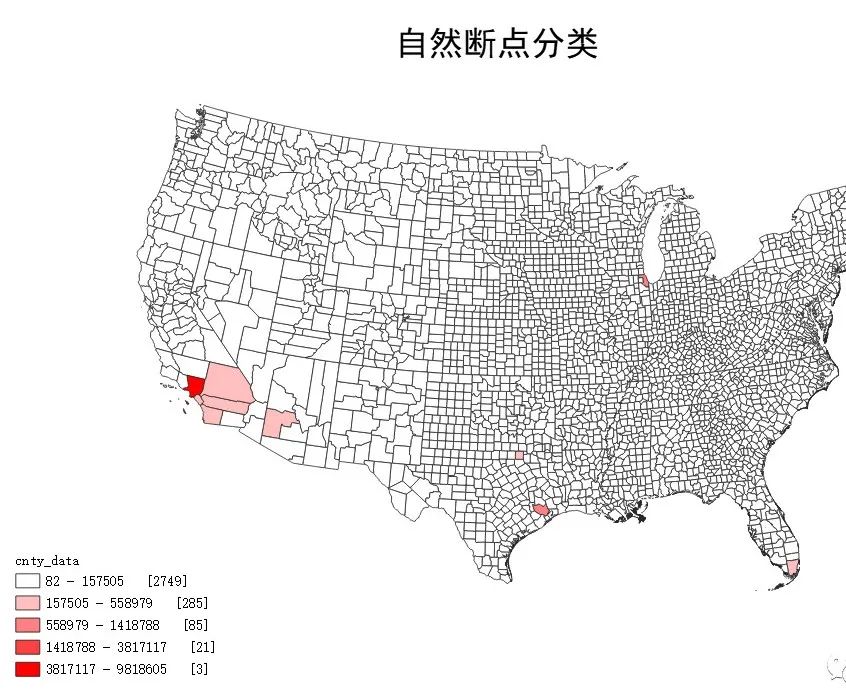
根据自然断点法的分组原理,该方法比较适合表现有明显聚类特征、且每个聚类内部样本比较均衡的数据。在每个聚类数量差异大的情况下,各个分组的要素数量差异也相对较大,例如本范例数据中,约90%的县都在第一个分组内,使得分组表达的意义不大。
即便如此,由于自然断点分段法具有统计意义上的优势,成为很多GIS软件默认的数据分段方法。
05 标准偏差
标准偏差分类通过计算属性值的平均值和标准差,并根据其与平均值的偏差对数值进行分类,通常是以标准偏差的倍数为间隔,例如1.0或0.5个标准差。
分别在ArcGIS和QGIS使用标准偏差将Pop2010分为5类,结果如下:
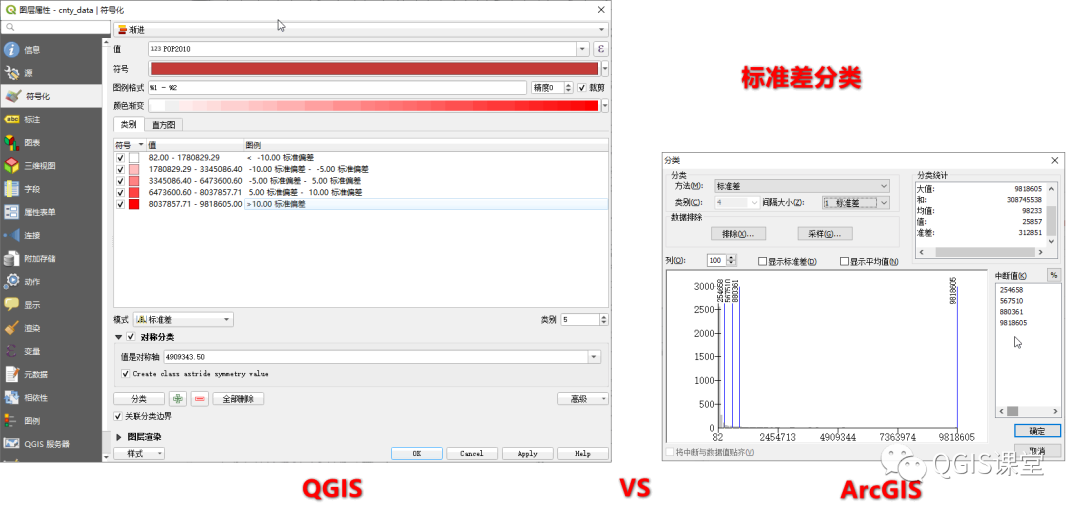
由上图可见,QGIS与ArcGIS的标准差分类差异巨大,不仅中断点的选取完全不同,设置方式也不同:
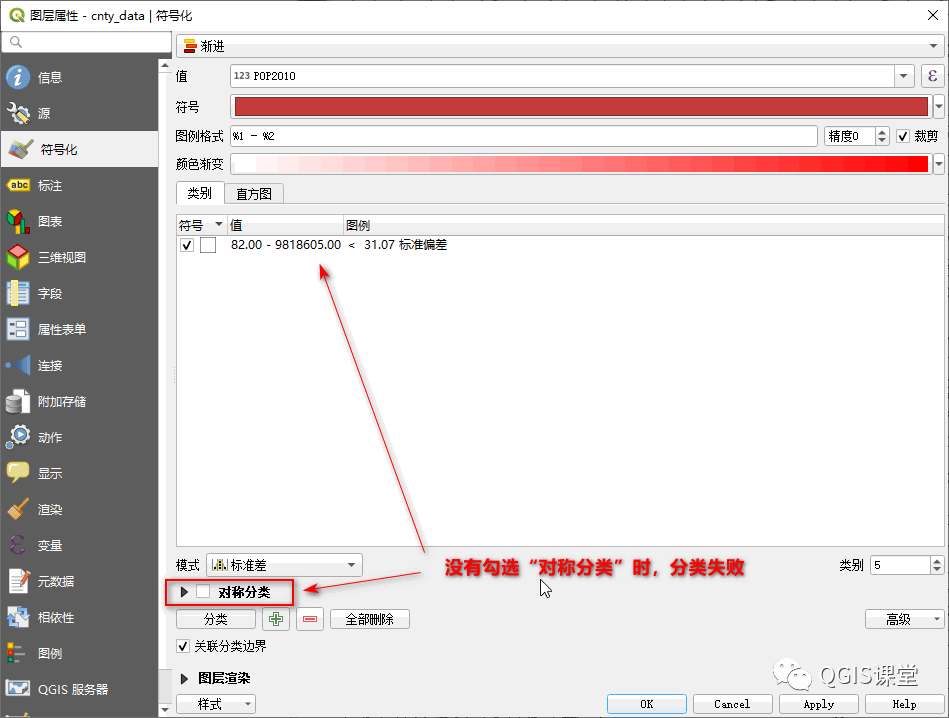
在QGIS中,除了选择属性字段外,还需要设置分类数,并勾选下方的“对称分类”复选框,输入对称轴,方可得到分类结果,否则将导致分类失败:
在ArcGIS中,标准差分类无需选择分类的数量,而是提供了4种分类间隔:1标准差、1/2标准差、1/3标准差、1/4标准差,根据所选择的间隔自动计算分类数量。
例如,对于本文范例数据,当选择间隔为1标准差时,数据将被分成4类;当选择间隔为1/2标准差时,数据将被分为8类;当选择间隔为1/3标准差时,数据将被分为11类;当选择间隔为1/4标准差时,数据将被分为14类。
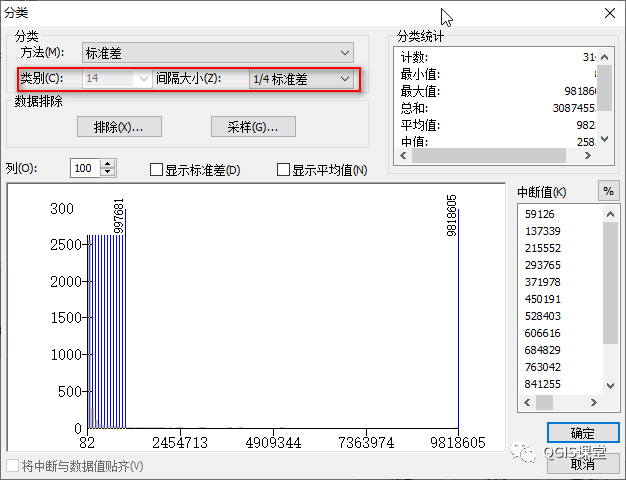
我们来看看QGIS与ArcGIS标准差分类断点计算方式的差异。
首先,标准偏差分类必须先计算所选属性数据的均值和标准差。
两者的计算方法从第二步开始出现差异化。
ArcGIS根据所选的间隔计算分类的中断点,类别的间隔为固定为1、1/2、1/3、1/4标准差。从均值开始,向上/向下扩展1/2所选间距,得到第一个中断点,然后根据区间两边的要素数量,以所选间距为步长增加分组,直到最小值和最大值所在区间的要素数量达到阈值。
以本文所选数据为例,均值为98233,标准差为312851,如果选择间隔为1标准差,则先计算出1/2*标准差,即1/2*312851=156425.5,所以第一个区间的界线为:均值±1/2标准差,即98233±156425.5=254658.5/-58192.5,取整后为254658/-58192,因为-58192比最小值82还小,取254658 第一个区间上界限,其范围是[82, 254658];第二区间的上界限为:第一区间上界限+1标准差,即254658+312851=567510,所以第二区间的范围是[254658, 567510],以此类推计算其他中断点。
QGIS则根据所选择的分类数量,使用Pretty Breaks算法将距离均值的标准差个数分组,根据返回的中断点确定分组的范围。
以本文所选数据为例,均值为98233,标准差为312851,最小值82,与均值的偏差为-0.314个标准差;最大值为9818605,与均值的偏差为个31.070标准差。QGIS将[-0.314, 31.070]和类别数(如本文5个类)作为参数调用PrettyBreaks函数,得到0.5、1、2、5倍数的中断点,如[-10,-5,0,5,10]。然后根据对称轴计算出真正的中断点数值,如第一个断点为:对称轴+个数*标准差。默认的对称轴为均值,由于所选的示范数据均值位于直方图非常偏左的位置,QGIS自动计算并更改对称轴为4909343.5,所以断点为:4909343.5-10*312851=1780829.29。同理计算出其他断点。
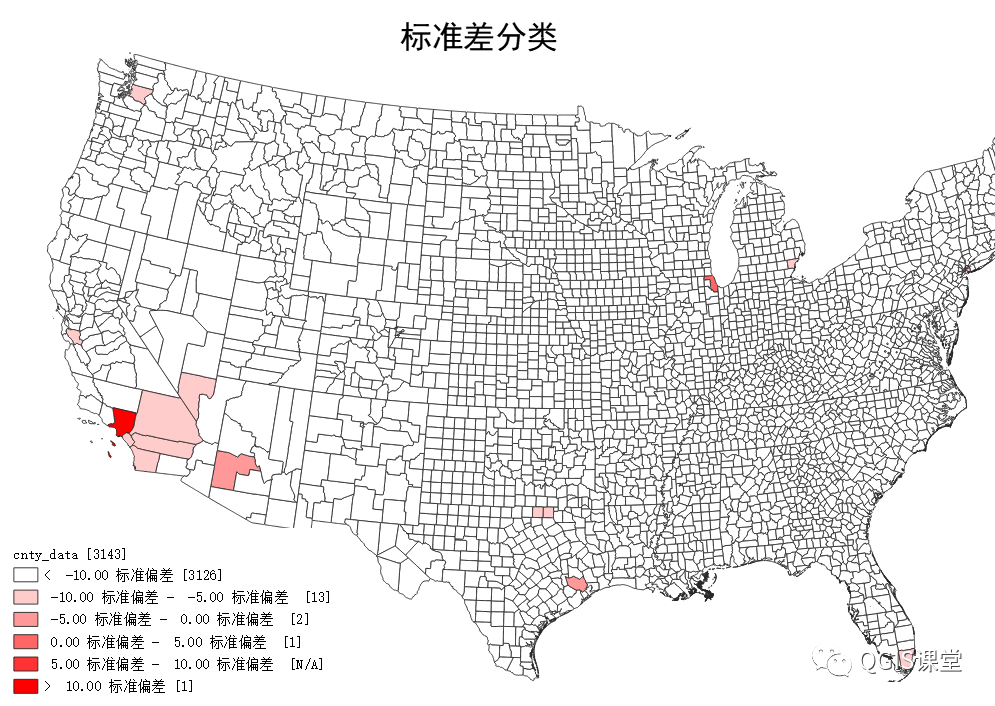
标准差分类适合于表现呈现正态分布的数据,对于本文所选的数据,两个软件的分类效果都不理想。
QGIS的标准差分类将数据分类映射为数据距均值的标准差个数的分类,即用PrettyBreaks算法求得标准差个数的断点后再计算原始数据断点,然而标准差个数中断点的合理并不代表对应的数据断点合理。例如本例中,第一个断点为-10个标准差。将绝大多数(3126个)县被分到第一组,其他分组的要素非常少。
ArcGIS的标准差分类兼顾了数据分布的特点,在数据分布密集的地方提供了较多分组,虽然由于原始数据选择不合理导致分组仍然出现扎堆现象,但是固定标准差间隔得到的分组解读起来更加容易。

参考资料:
[1] https://en.wikipedia.org/wiki/Jenks_natural_breaks_optimization。
[2]Michael J de Smith , Michael F Goodchild), Paul A Longley ,Geospatial Analysis: A Comprehensive Guide,ISBN-10 : 1912556030。
[3] ArcGIS帮助手册。

版权声明
本文欢迎转载,转载时请注明出处。
