1.内存条/总线/DMA(硬件):CPU和DMA是同级,对总线控制是轮换的
硬件–>OS–>用户程序系统调用,内核帮我们调内存–>jvm。io总线最常见的USB(通用串行总线),PCIE总线也是io总线。
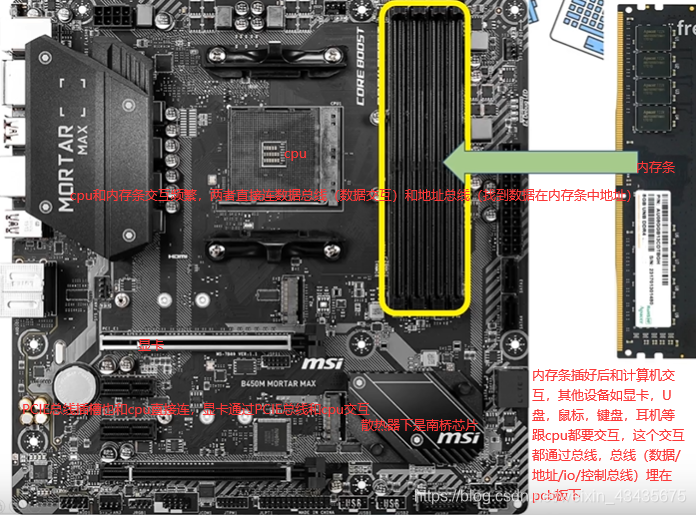
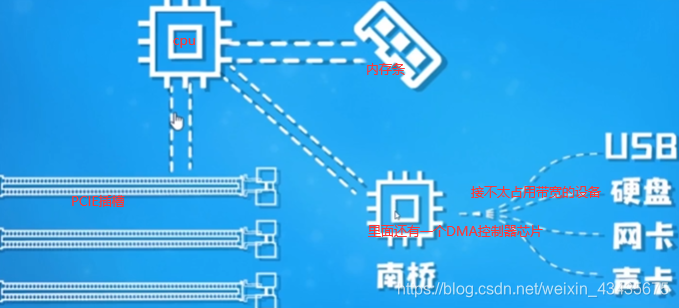
Nodejs是单线程,但在读文件时,文件还没读完却可以执行下面几行程序,文件读完后触发一个回调。因为单线程按理来说cpu直接读磁盘中文件的话,应该一直读取这文件,读完前不能进行其他操作,它怎么做到执行其他操作的呢?需要有硬件支持即DMA,读文件操作是非常机械劳动,cpu资源宝贵不能干这种活,下面xxx是内存地址。


2.OS内存管理与分类(操作系统):分页,页大小位数=偏移量
用户态和内核态都是程序处于的状态。读写文件和申请内存是用户态转内核态的两个例子。brk和mmap申请的都是虚拟内存,不是物理内存,想真拿到物理内存空间还要第一次访问时发现虚拟内存地址未映射到物理内存地址,于是促发一个缺页中断(也叫缺页异常)。C语言是malloc,而java和c++中new对象申请内存空间,也是经过这么过程。
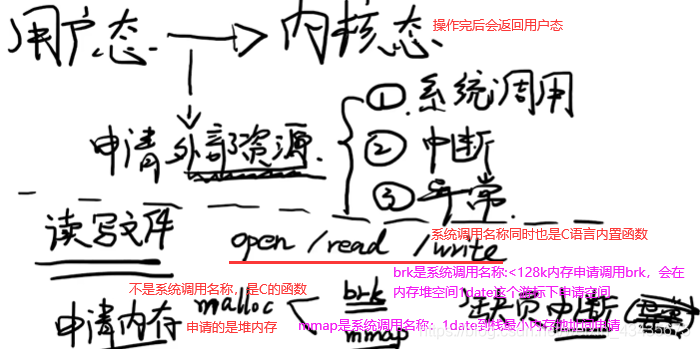
man syscalls

逻辑地址:程序自身看到的内存地址空间,是抽象地址。逻辑地址需要映射到物理内存才能完成对内存操作,那为什么程序操作是虚拟的逻辑地址,不能直接操作物理地址即对内存条操作?因为程序是写死的,这样操作的地址是固定的,而硬件可用的地址是变化的:内存条哪些地址被占用了是一直在变化的。
操作系统多进程,当前进程需操作的地址可能其他进程在使用,这样的话不能使用这块地址了,所以说除非是单进程机器,否则为了进程安全必须做出逻辑地址和物理地址的映射,所以必须要有逻辑地址,必须要有映射。如何映射?如下程序1的偏移量是0,程序2的偏移量200。如果程序1操作的逻辑地址是100,那么映射的物理地址也100(因为偏移量0)。如果程序2操作的逻辑地址是50,映射到物理内存250(因为偏移量200)。
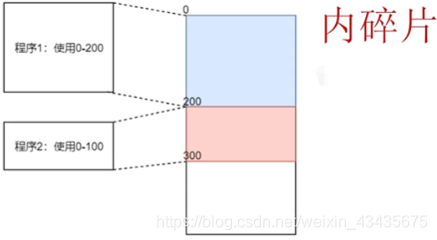
如上固定偏移量映射做法看上去简单高效,但存在两个重大缺陷,第一个缺陷:程序使用的内存其实无法计算的,随时间的推移,进程使用的内存不断变化的。这里我们说程序1使用200的内存,这种说法本身不太对的,因为我们没法去限定一个程序使用的内存大小,当然你可以说我估算了这程序使用的最大内存就是200,但这也代表整个200的一段内存中,程序使用的内存绝大多数时间都小于200的,以及这蓝色区域中内存使用率并不高,其中存在很多没有利用起来的内存,我们把没利用起来的内存叫内碎片。
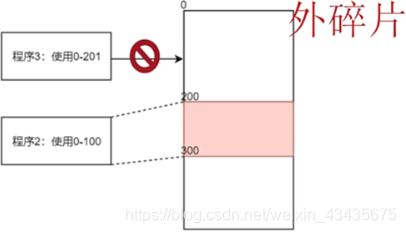
第二个缺陷:当程序运行完,内存被释放,比如程序1执行完后,0-200这块地址被释放出来了,此时程序3使用了内存大小是201,这时程序3没法直接使用0-200这段内存了,假设很长一段时间内都没有占用200以内的内存这样的程序被创建,那么0-200一直被闲置,称这段内存为外碎片。
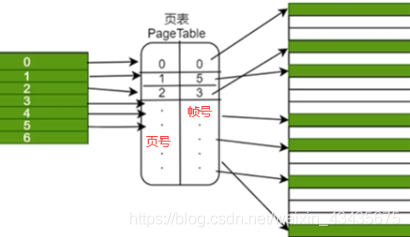
为了减少碎片问题,于是提出了分页映射:将内存空间包括逻辑内存(左)和物理内存(右)都进行切分,分成固定大小很多片,每一片称它为页(逻辑地址:页,物理地址:帧)。页到帧的映射需要有个表来维系,这个表就叫页表即pagetable(pagetable存了页号帧号,还有当前这一页读写权限等等)。
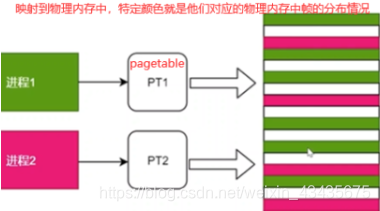
页表是每个进程都需要维护的,因为每个进程映射关系是互相独立的,所以不能共用映射表,每个进程有自己的pagetable。
第2和3点引发第4点。

操系内存管理主要使用虚拟内存(左),即我们的程序看到的内存地址是虚拟地址(这些地址连续),但实际映射到真正物理地址(右)可能不连续,散落在各个页中。如下左边1,2,3…每一块叫页,虚拟地址可能比物理地址大,盛不下时多出来部分可将虚拟地址的页映射到磁盘上,但映射到磁盘上导致下一次读映射到磁盘上这一页内存时会触发一个缺页中断进入到内核态,整个会产生一个大(major)错误
下面分析OX000011a3这个逻辑地址(程序)映射到物理地址(机器内存)过程:0-9999的数,你需要用多少位数表示?是4位就行,9999就是256M,4就是28 。二进制到十六进制:8421,最后3个8421即12位(bit)。

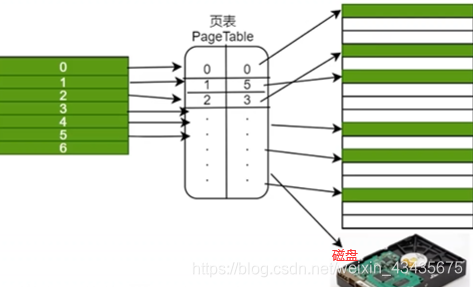
硬盘数据加载到内存帧中即磁盘换进物理内存,如果当前所有帧满了,那这时加载到哪个帧中呢?有一个页/帧置换算法,将最少使用的一帧逐出放到磁盘中,当前需要的数据放入物理帧中,所以linux下这磁盘部分又叫swapping(与物理帧交换)。
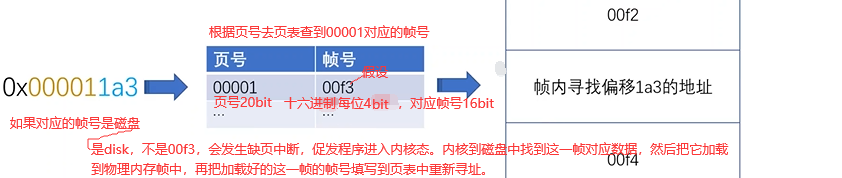
分页小结:1.分页使得每个程序都有很大的逻辑地址空间,通过映射磁盘和高效置换算法,使得内存无限大
2.分页使不同进程的内存隔离,保证了安全(不同进程各自维系了一个页表,只要页表中value即帧号这一栏不互相冲突,保证不同程序间内存隔离,保证安全性)
3.分页降低了内存碎片问题。空间优化:多级页表
第四点是缺点:页表存在我们主存中即存在内存中,如果我们要对某一个内存进行访问的话其实要读取两次内存。因为先读取页表,从页表中拿到对应帧号,再拿帧号去内存中再查询一遍,对内存操作有两次读取,时间上要优化(快表)。页表存在主存中其实也比较占空间,空间上要优化(多级页表)。

上面讲的是分页,程序内部的内存管理即分段,堆区和栈区就是程序的段。早期纯的分段其实将程序分成多个大的内存区,比如分成4个段,每个段分别对应很多页,每一段所看到的逻辑地址都从0开始。如下图左边是右边的说明。
分段和分页可结合,每个段有很多页(页即逻辑地址),页表可设计成含3项:段号,页号,帧号,原来是页号对应帧号,现在使用段号+页号才能对应一个固定帧号,这种方式效率低,目前被大多数软硬件抛弃了。
完全意义上分段现在不太存在了,X86_64这些架构的cpu种不再使用这种段页结合式只使用分页。这么说好像分段已经被淘汰了,但现在还是听到和段相关的如:C语言中段错误,如写程序中用到堆栈这样的段概念,这是为什么呢?原来段保留了逻辑上意义但并不在分页内存管理中起作用。
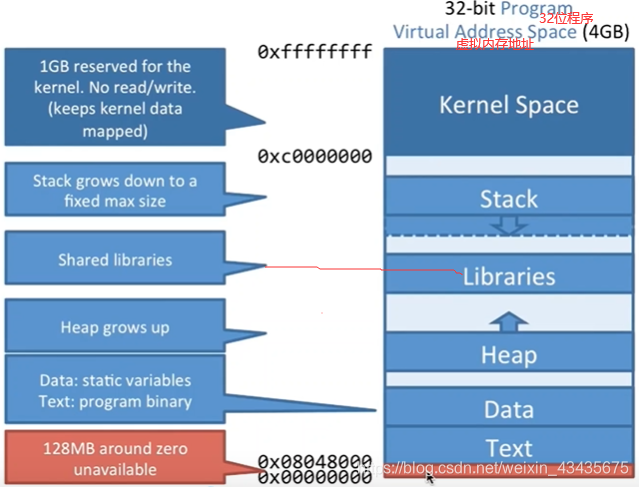
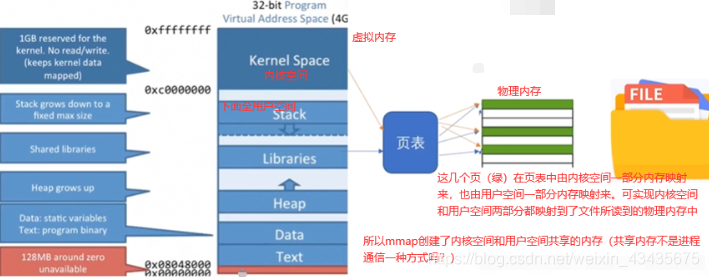
如上是一个C语言分段形式,如果是一个32位程序,它的虚拟地址就是4GB,分段就是对虚拟地址分成了多个段,从低到高,最高1G空间留给内核(kernel space),不同程序是共享这1G空间的。
最下面有两个段是text,data(text:存程序本身二进制字节码,data存程序中一些静态的变量)。再往上是堆Heap,堆是向上增长的(也就是地址往上增长的),高区stack栈区从高往低增长。
中间是Libraries函数库区,如linux中C常见的函数库so文件,windows下的dll动态链接库都放到堆和栈中间一段区域的(malloc若申请>128k的内存会调用mmap,mmap就是文件映射内存的系统调用,在堆和栈之间区域申请内存和这里lib区其实是相同位置,因为他们都是页进行映射磁盘)。
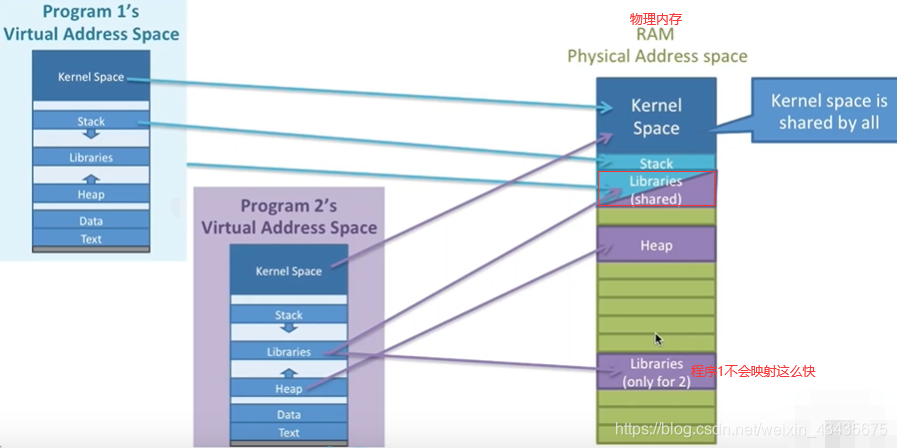
进程是可共享这段Libraries函数库,这就是之前讲的进程间通信的共享内存方式。共享内存极其常见,例如windows下选择文件的那个对话框。
栈区各自有自己映射的栈区(堆区也是),但库区(libraries)可能是多个进程共享一个或多个库(蓝紫相间库区是2个进程所共享)
如下free206M和available1.6G这两什么关系呢?目前能用的内存到底206M还是1.6G呢?是1.6G,一般used包含shared,free是真正的空闲,没有任何东西在使用的大小。文件磁盘缓存指读过的文件暂时帮我们缓存到内存中下次再读的时候直接从内存中拿出来就能加速对文件读写操作。
比如说现在free的空间只有206M,我有个程序要用1G内存,能用吗?能,buffer/cache这边1.6G有800M扔出去释放掉+206M=1G给程序用,也就是说buff尽量缓存一些文件,如果其他程序要用了,buff优先级很低立马释放掉了,所以一般要看能用的内存有多大,一般看available,不是去关注free。
buff/cache中间为什么有个/,较早内核中free-h看分buffcache(以磁盘扇区为单位直接对磁盘缓存,从硬件扇区看缓存)和pagecache(以页为单位对磁盘文件缓存,从文件系统看缓存)两项。两项有重复的地方,文件本质也是磁盘,如缓存一文件,如果有buffercache再缓存pagecache重复,所以较新的内核中看就是合起来的buff/cache。
上面是linux内存,下面看window内存,虚拟内存映射到物理内存也能映射到磁盘中(linux中看到的mem和swap两个分区),已提交的69.2G=mem(物理内存64G)+swap(windows下不是swap分区,而是.sys文件,文件管理器下看不到受系统保护)。
已提交:目前电脑上运行的所有程序向操系os申请了58G内存,但使用只有34G,原因:你申请了这么多,OS不一定给你这么多,比如C用malloc申请1G内存,假如只使用了1M,这时程序实际占用内存就是1M,剩下1023M你用到再给你,所以已提交大于使用中量,甚至说已提交的量可以大于整个OS内存大小如已提交1T(物理内存一共才64G)。
已缓冲:对应linux中buffer/cache即对文件的缓冲,已缓冲29.4G等于可用的29.4G,可用的内存全用来缓冲磁盘的文件了。

3.内存相关的系统调用(程序):缺页错误
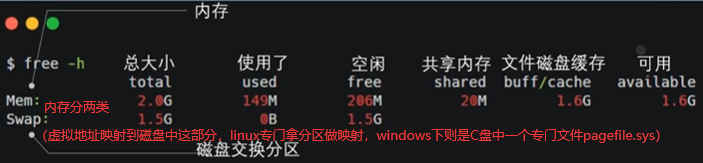
用户无法操作硬件如内存条,必须交给内核帮我们操作完了再把结果给我们,malloc是C库函数当小于128k调用brk,大于128k调用mmap。C语言中有sbrk库函数是对brk的一个封装,如下brk申请内存,内存是连续的,并不是说在堆空间随便找内存就把空间给你,换句话说:brk是提高了堆Heap上界 。
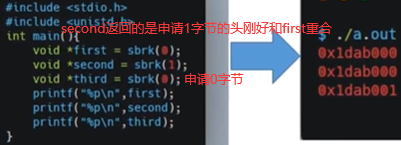
如下(first+1) 前面的星号是对(first+1) 赋值,赋一个int值,也就是说当前我们是对第5,6,7,8四个字节赋int值123。只有第一个字节通brk申请出,却给第5-8字节赋值,这样会不会报错呢?
不会,主要原因是在上节讲到的操系内存的分页管理所导致的,也就是说brk申请内存申请最小单位为1页,一般系统中页大小4k,所以brk看似申请1字节其实申请了一页(4096个字节),所以第5-8字节也属于4096字节里,也是当前进程所能支配的内存,所以不报错。
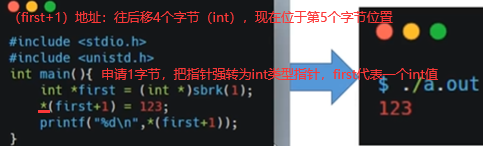
下面是mmap系统调用,注意缺页缺的是内存还是磁盘。
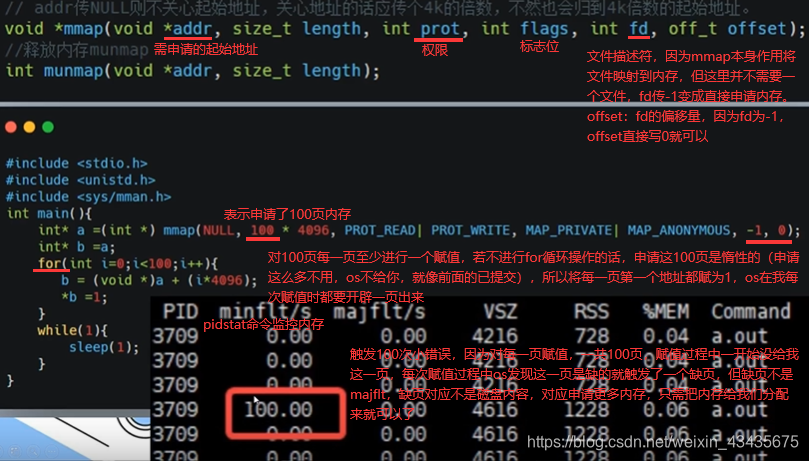
如下触发大错误因为对文件的映射,将文件映射到内存,但也是惰性的,这文件没有直接读到内存里,而是当真正需读文件里内容时才会映射到内存里。
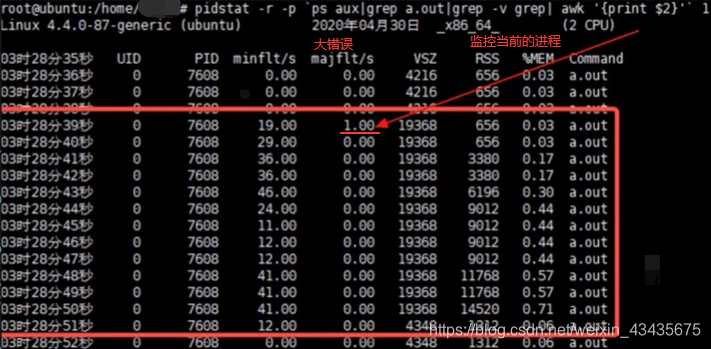
上面for循环里打印文件内容时,这时它会取到内存中读,发现这一页在查页表时对应是磁盘就触发一个缺页错误,并且对应是磁盘,触发majflt,将磁盘内容加载到内存中,之后就是一些小错误了(大错误后文件全部加载到了物理内存,后面小错误是要把虚拟内存对应到物理内存上)。
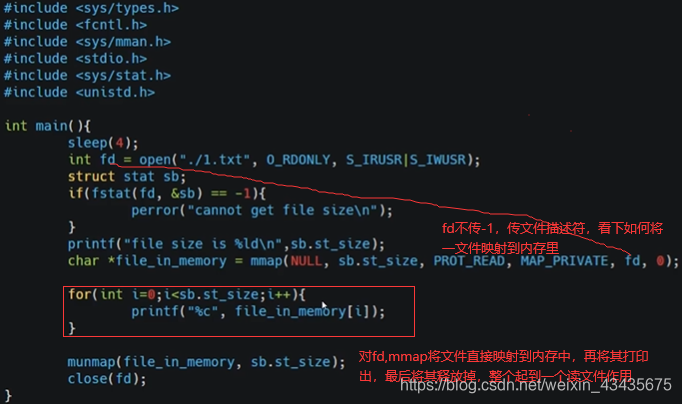
mmap和普通的fread(库函数)或read(系统调用)读文件有什么区别呢?read过程:调用read系统调用进入内核态,内核态将文件内容加载到内核空间(kernel space),内核空间给它复制到用户空间,再从内核态切换到用户态,然后用户的程序就可读到文件的内容了,有个文件-内核空间-用户空间周转过程。
mmap直接将文件进行了映射,一开始在页表中填充的是磁盘,一开始mmap是惰性的直接对应磁盘文件,真正读取时触发缺页将文件加载到内存。这里的共享是简单的共享,只是说内核空间对应页表中的k对应value和用户空间k对应value是同一个值且都映射文件所对应的物理内存,看似达到共享效果但跟进程间共享内存不是一个东西。
这过程好处:在缺页异常触发完成后,就可看到文件内容直接映射到用户空间一分区中,虽然也是堆和栈间区域但不是lib区(lib区应该是专门放动态链接库)。用户空间并不需要通过内核空间周转可直接对文件操作,省去了内核空间到用户空间拷贝过程,所以mmap也是实现0拷贝技术一种方式(sendfile系统调用也是)。
mmap这么牛干嘛还用read函数?mmap虽减少了内核空间到用户空间拷贝,但mmap没法利用前面讲的buffer/cache对文件缓冲这么一块空间,而且mmap第一次触发的缺页异常不是很稳定,并没有一个绝对性能比read好。
B站/知乎/微信公众号:码农编程录
