我们在爬取网站的时候经常会遇到突然访问不了的问题,原因之一是因为你的ip进了该站的黑名单,在某一段时间内不能访问该站的资源。那么该怎么解决这个问题?比较有效的方式是使用代理ip,而如果有一个自己的代理ip池,妈妈再也不用担心我没有ip可用啦。
github传送门0(xici代理ip池)
西刺网(传送门1 国内高匿)是一个免费代理ip资源比较多的站,本文就从西刺网获取ip,制作代理ip池。
打开(传送门1 国内高匿)可见到如下页面
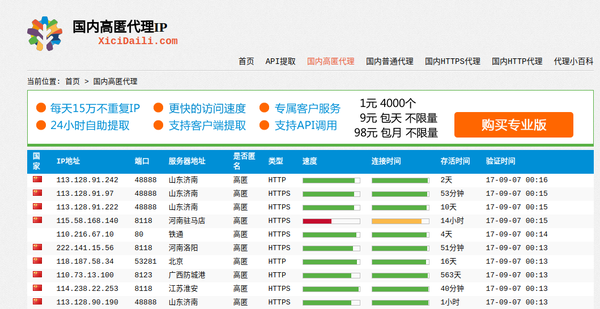
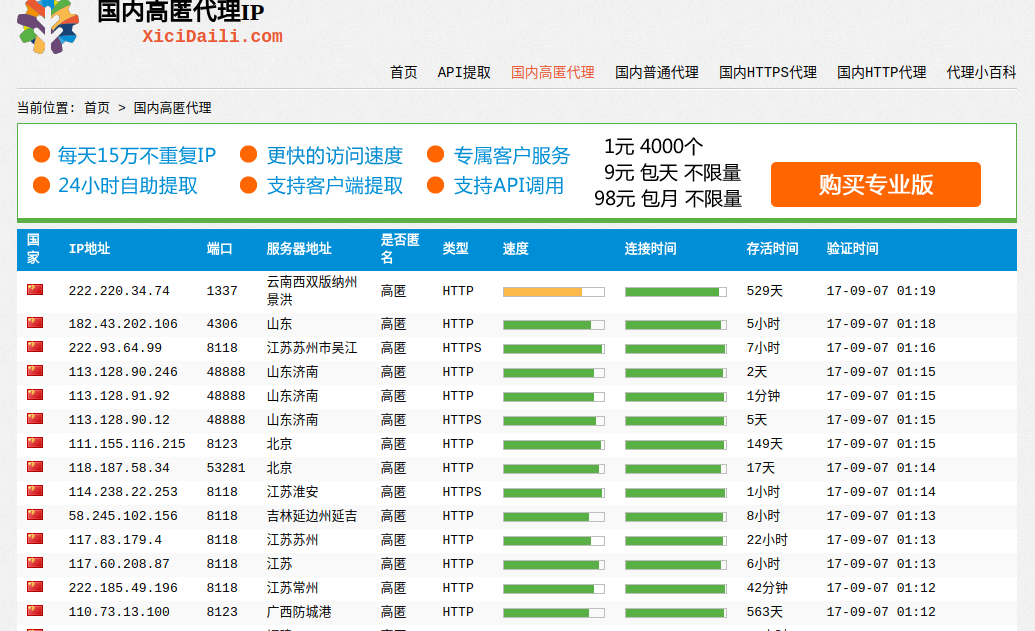
有俩千多页代理ip,,当然这是按时间排序的,我估计越到后面的ip可能就没啥用了.
分析该页面的源码

很简单的发现,所有的代理ip信息都在table下,每一个tr都是一条ip的信息。那这就比较简单了,分分钟来一个漂亮的正则来将需要的信息匹配出来(这里我匹配的有ip地址,端口,类型,服务器地址,是否匿名)
编写xc.py
正则表达式(个人觉得这应该是本程序最精华的部分)的使用如下
pattern=re.compile(u'<tr class=".*?">.*?'
+u'<td class="country"><img.*?/></td>.*?'
+u'<td>(\d+\.\d+\.\d+\.\d+)</td>.*?'
+u'<td>(\d+)</td>.*?'
+u'<td>.*?'
+u'<a href=".*?">(.*?)</a>.*?'
+u'</td>.*?'
+u'<td class="country">(.*?)</td>.*?'
+u'<td>([A-Z]+)</td>.*?'
+'</tr>'
,re.S)
l=re.findall(pattern,text)\d匹配数字,\d+匹配多个数字 (\d+) 这里匹配端口号
[A-Z]匹配大写字母,[A-Z]+匹配多个大写字母 这里匹配的是类型
.匹配单个任意字符,*匹配前面字符0到多次,?匹配前面0到一次,(.*?)匹配任意字符
如果你对正则表达式不是很熟悉,你可以在这里(传送门2 菜鸟教程)进行这方面的学习。
下面编写请求头
self.headers={
'Accept-Encoding':'gzip, deflate, br',
'Accept-Language':'zh-CN,zh;q=0.8',
'Referer':'http://www.xicidaili.com/nn/',
'User-Agent':'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 '
'(KHTML, like Gecko) Ubuntu Chromium/60.0.3112.113 Chrome/60.0.3112.113 Safari/537.36',
}
self.proxyHeaders={
'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 '
'(KHTML, like Gecko) Ubuntu Chromium/60.0.3112.113 Chrome/60.0.3112.113 Safari/537.36',
}第一个self.headers是下载页面的请求头,self.proxyHeaders是后面验证ip是否可用的请求头。
下面是下载页面和正则匹配的函数
def getPage(self,url):
page=self.req.get(url,headers=self.headers).text
# print(page)
return page
def Page(self,text):
time.sleep(2)
pattern=re.compile(u'<tr class=".*?">.*?'
+u'<td class="country"><img.*?/></td>.*?'
+u'<td>(\d+\.\d+\.\d+\.\d+)</td>.*?'
+u'<td>(\d+)</td>.*?'
+u'<td>.*?'
+u'<a href=".*?">(.*?)</a>.*?'
+u'</td>.*?'
+u'<td class="country">(.*?)</td>.*?'
+u'<td>([A-Z]+)</td>.*?'
+'</tr>'
,re.S)
l=re.findall(pattern,text)
return l根据上面的代码,就可以将代理ip从西刺站拿下来,接下来检验是否有效。
requests是一个非常有用的库,这里也将使用它进行校验
self.req.get("http://www.baidu.com",proxies={"{}".format(i[2]):"{}://{}:{}".format(i[2],i[0],i[1])},timeout=5)
i 是 ('110.73.48.247', '8123', 'HTTP') 类数据
为了保证校验的可靠性,我把每次校验设置超时5s。
如此就能拿到新鲜免费的代理ip了,为了使得ip能多次使用,我将其存入mysql数据库中。
写入代码如下
def insert(self,l):
print("插入{}条".format(len(l)))
self.cur.executemany("insert into xc values(%s,%s,%s,%s,%s)",l)
self.con.commit()读取代码如下
def select(self):
a=self.cur.execute("select ip,port,xieyi from xc")
info=self.cur.fetchall()
return info
最后来看下使用效果:
编写demo.py 再导入xc.py 中的xiciSpider类
from xi import xiciSpider
p=xiciSpider()
#第一次先运行这个方法,现要将ip存入mysql
p.getNewipToMysql()
#获取可用代理ip,默认获取1个,可指定size大小
ip=p.getAccessIP()
print(ip)
#输出如下
“”“
/usr/bin/python3.5 /home/cb/桌面/xici/demo.py
[('36.251.248.76', '80', 'HTTPS')]
Process finished with exit code 0
”“”首先你需要从西刺网将ip爬取到自己数据库中,然后再从数据库中提取有用的ip
第二次可直接使用getAccessIP方法来获取可用ip.
最后奉上完整代码 github传送门0(xici代理ip池),觉得有用的不妨点个star
也欢迎关注本人的专栏 Python数据分析https://zhuanlan.zhihu.com/c_99646580