前言
随着互联网的发展,推荐系统在各种互联网项目中占据了不可缺少的一部分,商品的推荐,抖音小视频推荐,音乐推荐,交友推荐等等。电影系统相对来说是一种简单的推荐,因此笔者也从电影系统入手,进军推荐系统的学习,请大家参考。
一、电影推荐架构
1.1、系统架构
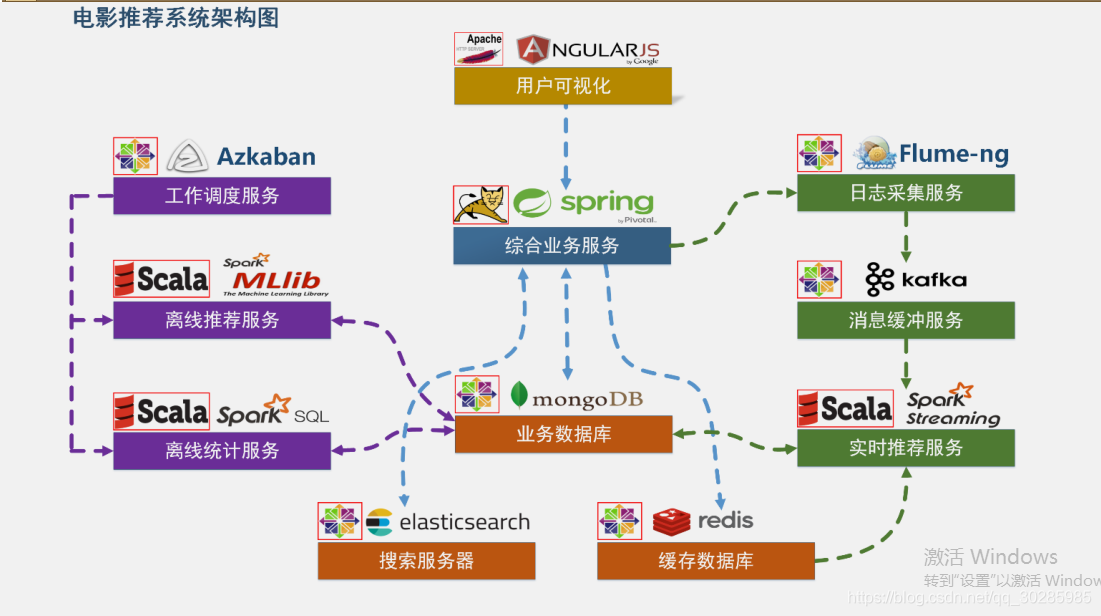
- 用户可视化:主要负责实现和用户的交互以及业务数据的展示,主体采用AngularJS2 进行实现,部署在 Apache 服务上。
- 综合业务服务:主要实现 JavaEE 层面整体的业务逻辑,通过 Spring 进行构建,对接业务需求。部署在 Tomcat 上。
【 数据存储部分】
- 业务数据库:项目采用广泛应用的文档数据库 MongDB 作为主数据库,主要负责平台业务逻辑数据的存储。
- 搜索服务器:项目爱用 ElasticSearch 作为模糊检索服务器,通过利用 ES 强大的匹配查询能力实现基于内容的推荐服务。
- 缓存数据库:项目采用 Redis 作为缓存数据库,主要用来支撑实时推荐系统部分对于数据的高速获取需求。
【离线推荐部分】
- 离线统计服务:批处理统计性业务采用 Spark Core + Spark SQL 进行实现,实现对指标类数据的统计任务。
- 离线推荐服务:离线推荐业务采用 Spark Core + Spark MLlib 进行实现,采用ALS 算法进行实现。
- 工作调度服务 :对于离线推荐部分需要以一定的时间频率对算法进行调度,采用 Azkaban 进行任务的调度。
【实时推荐部分】
- 日志采集服务:通过利用 Flume-ng 对业务平台中用户对于电影的一次评分行为进行采集,实时发送到 Kafka 集群。
- 消息缓冲服务:项目采用 Kafka 作为流式数据的缓存组件,接受来自 Flume 的数据采集请求。并将数据推送到项目的实时推荐系统部分。
- 实时推荐服务:项目采用 Spark Streaming 作为实时推荐系统,通过接收 Kafka中缓存的数据,通过设计的推荐算法实现对实时推荐的数据处理,并将结构合并更新到 MongoDB 数据库。
1.2、项目数据流程
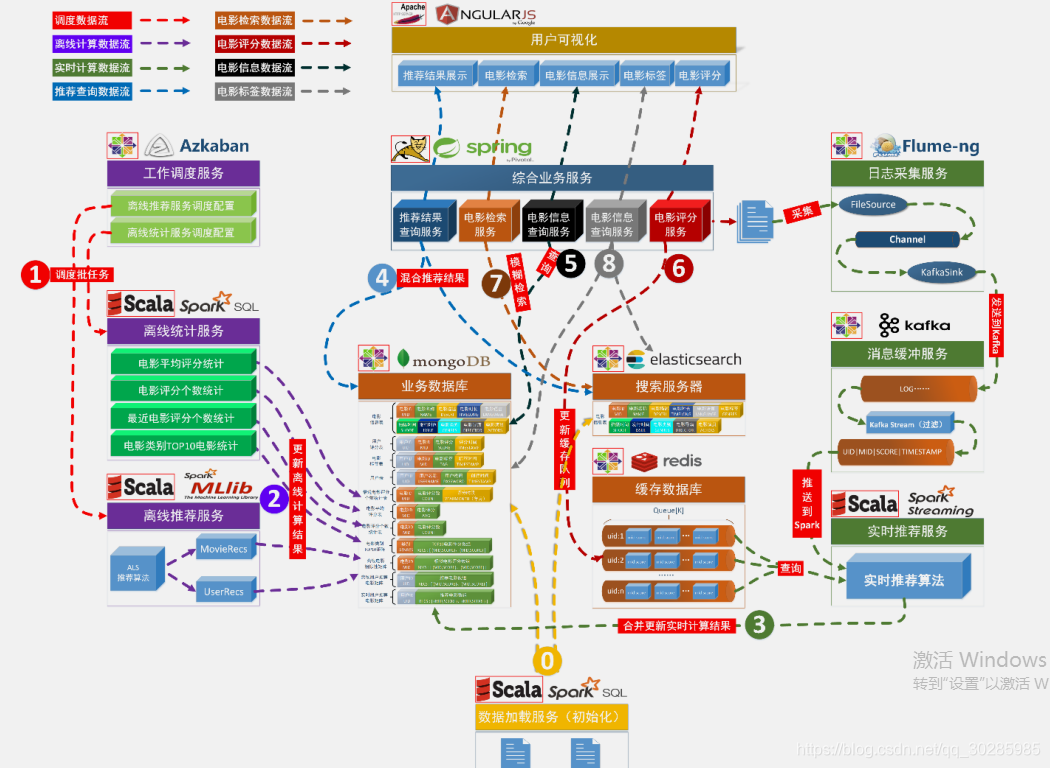
【系统初始化部分】
- 通过 Spark SQL 将系统初始化数据加载到 MongoDB 和 ElasticSearch 中。
【离线推荐部分】
- 通过 Azkaban 实现对于离线统计服务以离线推荐服务的调度,通过设定的运行时间完成对任务的触发执行。
- 离线统计服务从 MongoDB 中加载数据,将【电影平均评分统计】、【电影评分个数统计】、【最近电影评分个数统计】三个统计算法进行运行实现,并将计算结果回写到 MongoDB 中;离线推荐服务从 MongoDB 中加载数据,通过 ALS 算法分别将【用户推荐结果矩阵】、【影片相似度矩阵】回写到 MongoDB 中。
【实时推荐部分】
- Flume 从综合业务服务的运行日志中读取日志更新,并将更新的日志实时推送到Kafka 中;Kafka 在收到这些日志之后,通过 kafkaStream 程序对获取的日志信息进行过滤处理,获取用户评分数据流【UID|MID|SCORE|TIMESTAMP】,并发送到另外一
个 Kafka 队列;Spark Streaming 监听 Kafka 队列,实时获取 Kafka 过滤出来的用户评分数据流,融合存储在 Redis 中的用户最近评分队列数据,提交给实时推荐算法,完成对用户新的推荐结果计算;计算完成之后,将新的推荐结构和 MongDB 数据库中的推荐结果进行合并。
【业务系统部分】
- 推荐结果展示部分,从 MongoDB、ElasticSearch 中将离线推荐结果、实时推荐结果、内容推荐结果进行混合,综合给出相对应的数据。
- 电影信息查询服务通过对接 MongoDB 实现对电影信息的查询操作。
- 电影评分部分,获取用户通过 UI 给出的评分动作,后台服务进行数据库记录后,一方面将数据推动到 Redis 群中,另一方面,通过预设的日志框架输出到 Tomcat 中的日志中。
- 项目通过 ElasticSearch 实现对电影的模糊检索。
- 电影标签部分,项目提供用户对电影打标签服务。
二、电影推荐思路
首先电影推荐相对于其它推荐来说比较简单。相对于短视频推荐来说,电影推荐不会每天更新大量的新数据,电影可能每个月就几个新电影的上映。相对于新闻推荐来说,实时性可能就没那么重要,很多老的电影也会有很多用户喜欢观看。因此电影推荐或者音乐推荐最适合新手入门。
2.1、特征提取
用户电影特征提取时,必须要有对应的数据,电影表,用户表,用户评价表。通过als算法对评价表进行计算,计算出电影的特征矩阵。通过电影特征的矩阵计算得出每个电影最相似的几个电影,并且保存。保存数据如下:
{
"_id":"600a2decbf19ae00fc6e2f18",
"mid":1669,
"recs":[
{
"mid":2776,
"score":0.9999999999999994
},
{
"mid":2820,
"score":0.9996844527170483
}
]
}
MongoDB 是一个面向文档存储的数据库,操作起来比较简单和容易。对这种数据结构有良好的支持,所以在此选择MongoDB。
详细到:ALS进行离线推荐
2.2、实时推荐
在此实时推荐采用一个比较简单的思路,便于理解。
当用户 u 对电影 p 进行了评分,将触发一次对 用户u 的推荐结果的更新。由于用
户 u 对电影 p 评分,对于用户 u 来说,他与 电影p 最相似的电影们之间的推荐强度将
发生变化,所以选取与电影 p 最相似的 K 个电影作为候选电影。
详细到:实时推荐
2.3、电影内容推荐
总结
此为最简单的电影推荐实现思路,当然还有很多需要完善的地方。而且在实际场景中也要根据实际情况去灵活的运用。
参考地址:
ALS算法详解
尚硅谷电影推荐实战