声音的向量表示
原理
- 向量x ∈ R N x\in R^Nx∈RN表示时间区间上的音频信号,x i x_ixi表示t = h i t=h_it=hi时的声压x i = α p ( h i ) , i = 1 , . . . , N x_i=\alpha p(h_i),i=1,...,Nxi=αp(hi),i=1,...,N
- 每个x i x_ixi称为样本
- h(>0)为采样时间
- 1/h为采样率,典型的采样率为1 / h = 44100 / s e c 1/h=44100/sec1/h=44100/sec或48000 / s e c 48000/sec48000/sec
- α \alphaα被称为比率因子
使用python的librosa库可以读取音频信号,并用matplotlib显示波形
y,sr = librosa.load("MUSIC STEM.wav",sr=None) #y为长度等于采样率sr*时间的音频向量
plt.figure()
librosa.display.waveplot(y, sr) #创建波形图
plt.show() #显示波形图
- 1
- 2
- 3
- 4
结果

分析
音频信号每一位分别对应一个采样点,其位数等于“采样率*音频时长(以秒为单位)”,记录了每个样本上音频的振幅信息
缩放音频信号
原理
音频的响度由音频信号每个样本的数值绝对值大小决定,因此对音频信号作代数乘法运算,可以增减音频的响度
numpy数组提供的代数乘法功能可以用于增减音频响度,并利用librosa库将音频向量写回文件
y=2*y #增加一倍振幅
y=0.5*y #减小振幅为原来一半
y=-y #翻转振幅
y=10*y #大幅增加振幅
librosa.output.write_wav(dir,y,sr) #将音频向量写回文件
- 1
- 2
- 3
- 4
- 5
结果
四种操作结果的波形分别如图所示
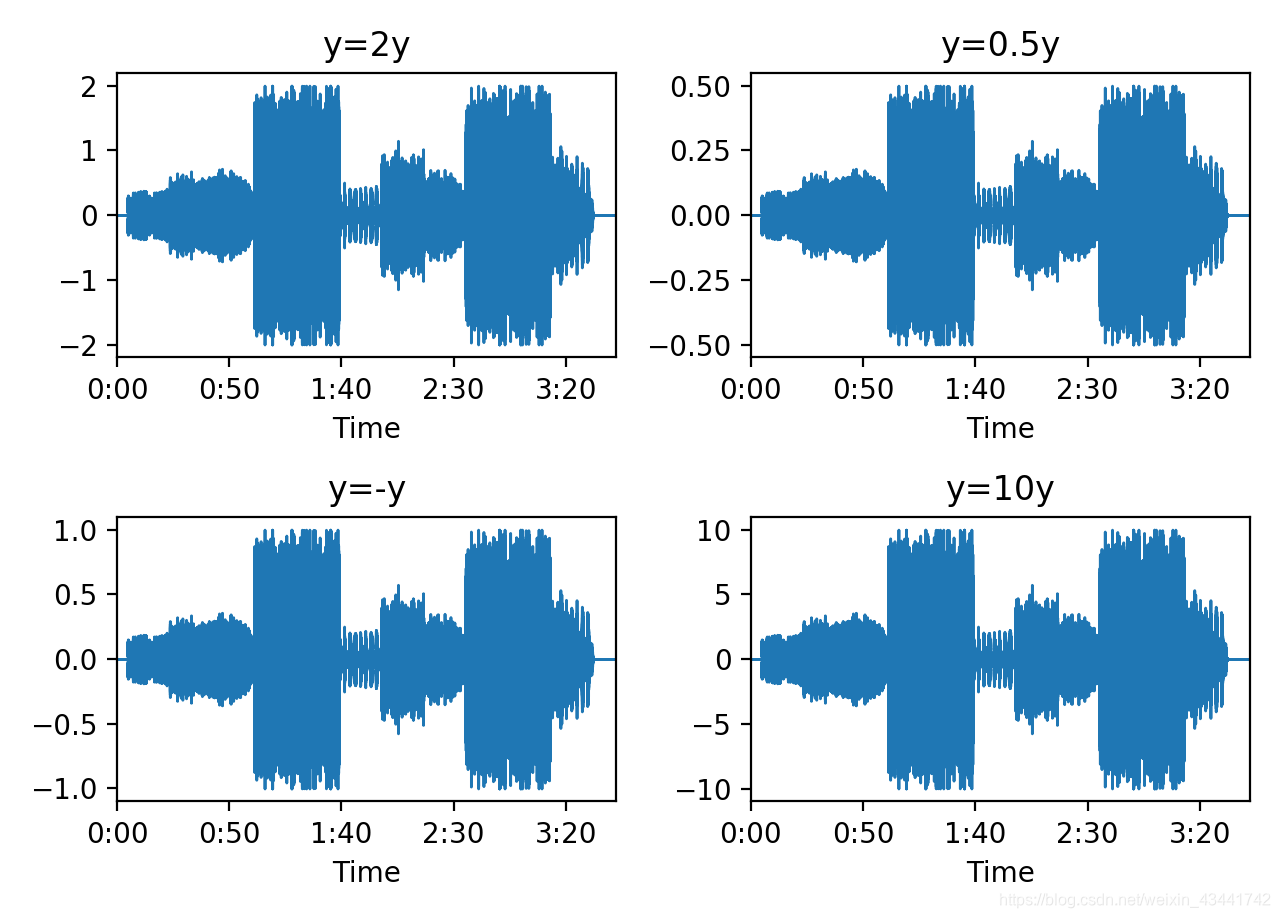
- y=2*y时,得到的音频响度略大于原音频
- y=0.5*y时,得到的音频响度略小于原音频
- y=-y时,得到的音频响度与原音频一致
- y=10*y时,得到的音频响度远大于原来音频
分析
- 音频信号每个样本的数值反应了振动离开平衡点的距离,即振幅,振幅越大,声音具有的能量越大,声音听起来响度就越大
- 对样本数值进行倍增,若倍增系数绝对值大于1则声音响度增加,若倍增系数绝对值小于1则声音响度下降
- 由于振动离开平衡点的距离是一个绝对值,因此倍增系数为负数时效果与倍增系数是其相反数时一致
线性组合和混音
原理
-
对多个音频信号进行线性运算y = a 1 x 1 + a 2 x 2 + . . . + a k x k y=a_1x_1+a_2x_2+...+a_kx_ky=a1x1+a2x2+...+akxk可以实现混音
-
此时每个音频信号x k x_kxk称为音轨
-
混合后的结果y称为混合
-
每个系数a k a_kak是音轨在混合中的权重
numpy数组提供的线性运算功能可以用于实现混音
再尝试人声与伴奏的混合,取一段人声轨和一段伴奏轨,分别赋予权重(0.25,0.75)、(0.5,0.5)、(0.4,0.6)进行线性混合
y=0.25*x1+0.75*x2
y=0.5*x1+0.5*x2
y=0.6*x1+0.4*x2
- 1
- 2
- 3
结果
波形图如下所示: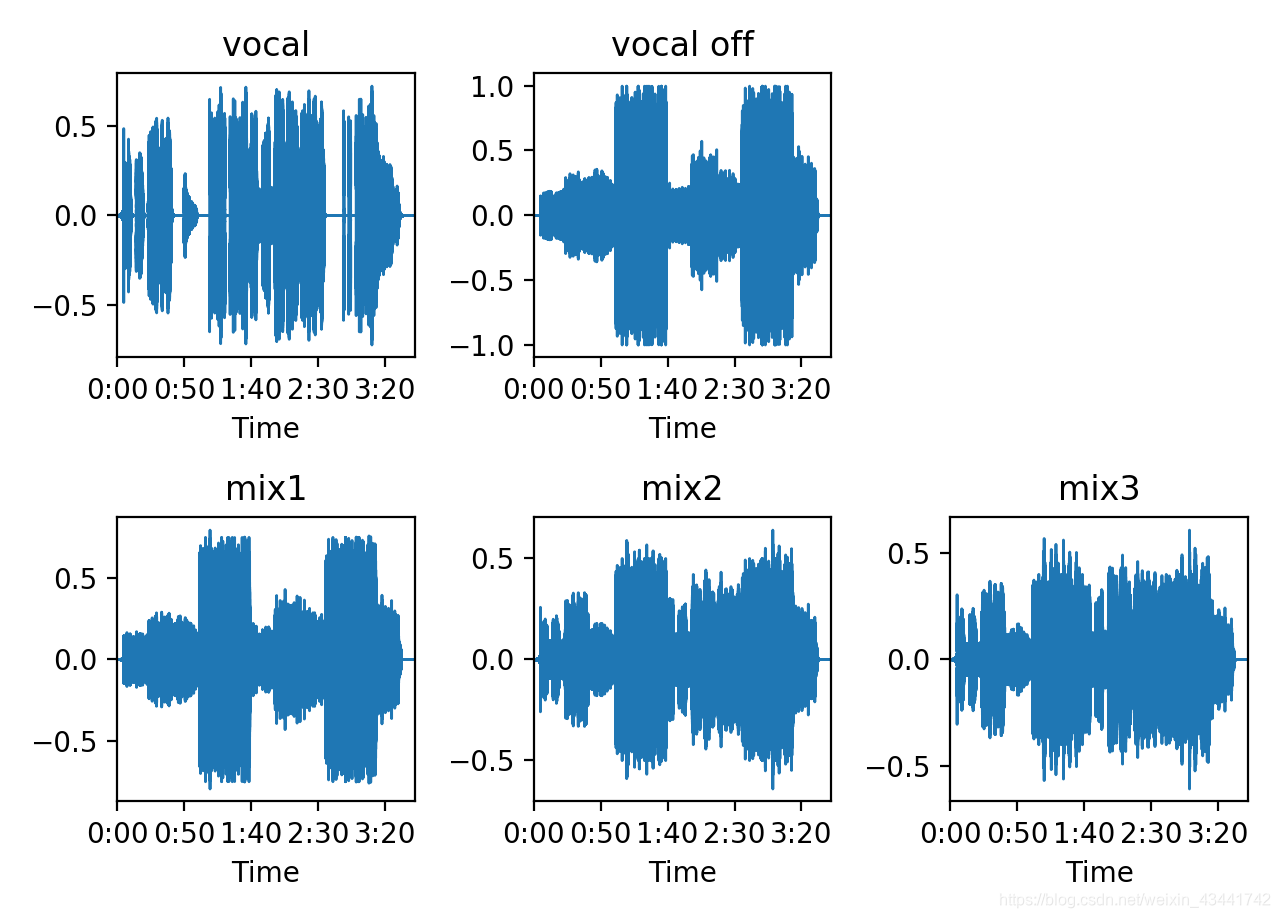
得到的音频为在伴奏上加上人声的效果
分析
-
音频是线性相加,得到的波形图中无法直观分出人声和伴奏,但由于人声和伴奏中各频率谐波分量与伴奏中不同,线性相加在频域被分配到了各频率谐波上,所以可以在频谱图上清晰区分出来
-
为了得到足够清晰的混音音频,需要不断更改每个混音音轨的权重以得到最适合的混合模式
拓展
虽然人声和伴奏中谐波分量基本不同,但相同频率上的相加也容易导致撞频的发生,使得混合的人声和伴奏难以区分,因此对于双声道音频,我们常常采用偏置的方法,为两个声道中人声和伴奏设不同的权重(通常一个声道人声大,一个声道伴奏声大)
形状为(2,n)的numpy数组可以用于容纳双声道音频信号。两个声道分别取权重(0.4,0.6)、(0.6,0.4)进行混合,波形如下: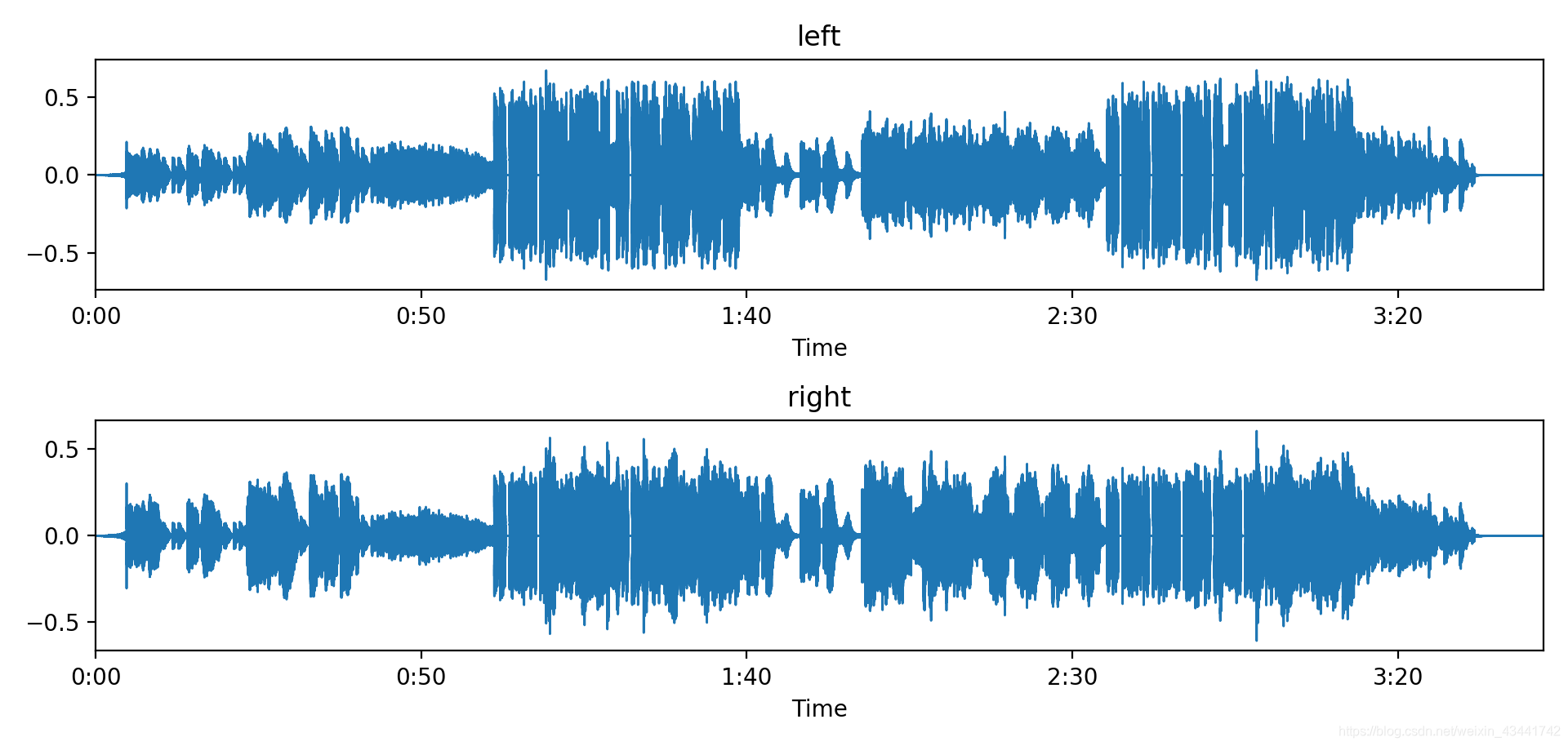
乐音
- 对于声音信号p(t),若满足p ( t + T ) ≈ p ( t ) p(t+T)\approx p(t)p(t+T)≈p(t),其中周期T取值在0.0005秒到0.01秒之间,则p被视为乐音
- 周期长短(决定频率并)决定音高
- 每个周期内波形的特点决定了音色
- 乐音的能量决定了响度,即声压
音高
- f = 440 H z f=440Hzf=440Hz是中央A
- 一个八度在频率上翻了一倍
- 十二平均律中,每个半音在频率上翻了2 1 / 12 2^{1/12}21/12倍
- 每个半音的距离就是黑白键上两个键之间的距离,从do到升do,各白键之间的差音为全全半全全全半,而每个全音中的半音被分到了黑键上
- 任意两个音之间的距离称为音程,音程的单位是度,相同单音之间音程为1度,之后每差一个音级增加1度
实验步骤:
- 设置基频f为440Hz,用numpy以440Hz生成正弦函数
- 每隔1/44100s设置一个采样点,每间隔1s生成1s的440Hz正弦波
- 在这基础上,第n次生成时再生成1s频率为440 ⋅ 2 ( n − 1 ) / 12 H z 440·2^{(n-1)/12}Hz440⋅2(n−1)/12Hz的正弦波,与原正弦波线性相加进行和弦,从而模拟小二度到纯八度的所有音程
x=np.empty((0,)) #生成空数组
for i in range(0,13):
x1=np.linspace(0,1, num=44100, endpoint=True, dtype=float) #生成采样点
x1=5*np.sin(2*np.pi*440*np.power(2,i/12)*x1)+5*np.sin(2*np.pi*440*x1) #生成波形与和弦
x2=np.zeros((44100,)) #留空部分
x=np.concatenate((x,x1,x2),axis=0) #连接数组
- 1
- 2
- 3
- 4
- 5
- 6
生成的26s音频中有13段不同音程的和弦,有的和弦听起来和谐,有的和弦听起来不和谐
- 小二度音程(相差一个半音)、大七度音程(相差五个全音一个半音)是极不协和音程
- 大二度音程(相差一个全音)、小七度音程(相差五个全音)、三全音(三个全音)是不协和音程
- 小三度音程(相差一个全音一个半音)、大三度音程(相差两个全音)、小六度音程(相差四个全音)、大六度音程(相差四个全音一个半音)是不完全协和音程
- 纯四度音程(相差两个全音一个半音)、纯五度音程(相差三个全音一个半音)是完全协和音程
- 纯八度音程(相差六个全音)是极完全协和音程
音色
-
对于周期性信号p ( t ) = ∑ k = 1 K ( a k c o s ( 2 π f k t ) + b k s i n ( 2 π f k t ) ) p(t)=\displaystyle \sum_{k=1}^K (a_kcos(2\pi fkt)+b_ksin(2\pi fkt))p(t)=k=1∑K(akcos(2πfkt)+bksin(2πfkt)),每个分解信号为谐波或泛音
-
f为频率
-
a与b为谐波系数
-
在K足够大时,任意周期性信号都可以通过积分变换为这种形式
-
谐波振幅的配比决定了音色,对于每个频率由k决定的谐波,其谐波振幅为c k = a k 2 + b k 2 c_k=\sqrt{a_k^2+b_k^2}ck=ak2+bk2,因此谐波振幅可以组成一个长度为k的向量c = ( 0.3 , 0.4 , . . . ) c=(0.3,0.4,...)c=(0.3,0.4,...),足够多的谐波以不同振幅数值混合可以组成不同音色
在220-11000Hz之间分别生成1、5、10、20、50个频段的正弦、余弦信号,随机生成谐波系数
结果
五种情况下混合波形图如下所示:
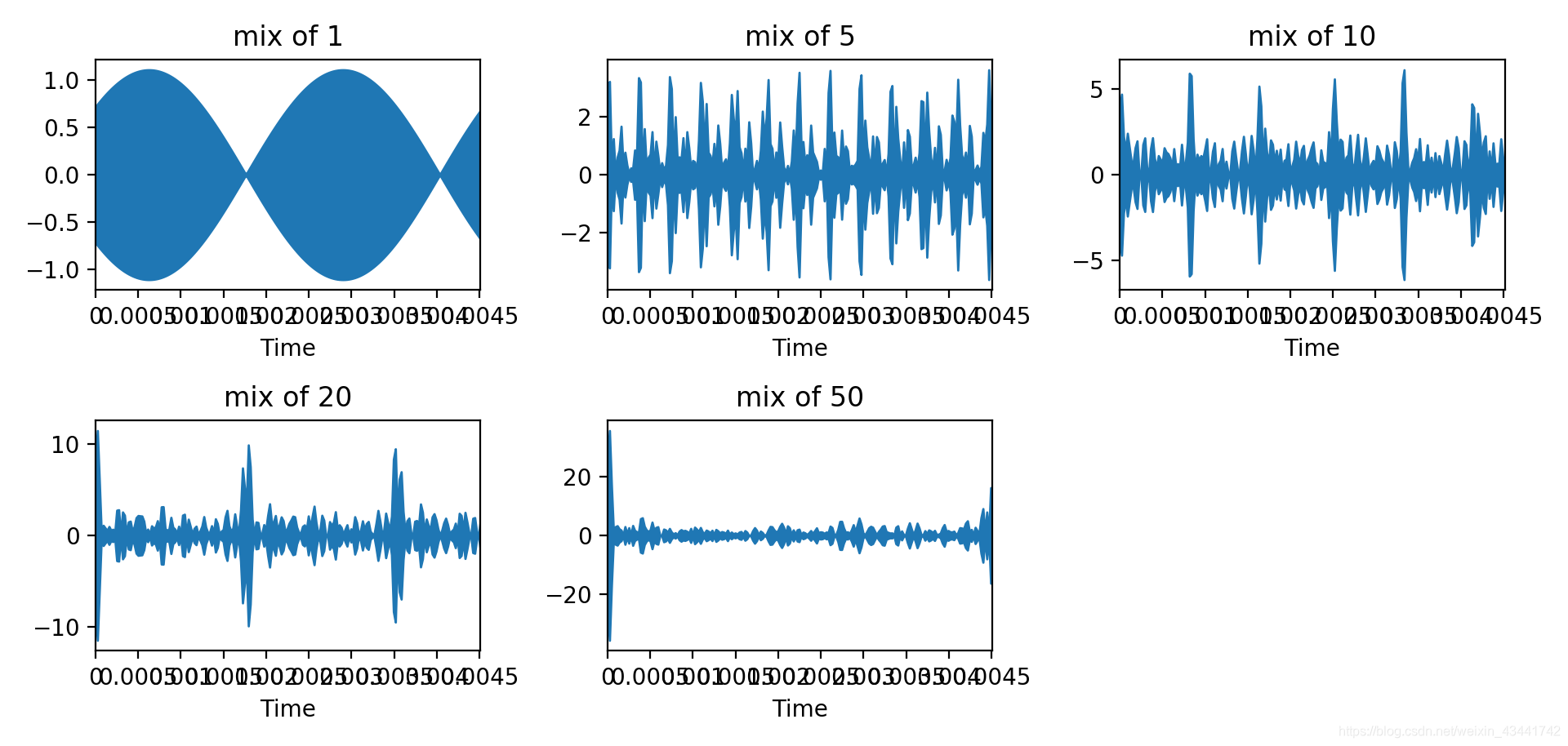
得到一段每隔1s播放1s不同音色音频的音频文件
分析
- 使用不同足够多的谐波以不同谐波系数混合可以组成不同音色音频
- 现实中已知乐器也可以利用频谱分析提取音色特征,供计算机再现
- 利用谐波原理可以制作各种各样的电子合成器,供作曲家使用