最简单的保存和恢复模型的方法是使用
tf.train.Saver()对象,它给graph中的所有变量,或是定义在列表里的变量,添加save和restore ops。tf.train.Saver()对象提供了方法来运行这些ops,并指定了检查点文件的读写路径。
一、tf.train.Saver() 类解析
tf.train.Saver(
var_list=None,
reshape=False,
sharded=False,
max_to_keep=5,
keep_checkpoint_every_n_hours=10000.0,
name=None,
restore_sequentially=False,
saver_def=None,
builder=None,
defer_build=False,
allow_empty=False,
write_version=tf.train.SaverDef.V2,
pad_step_number=False,
save_relative_paths=False,
filename=None
)1、初始化参数解析
- var_list
- specifies the variables that will be saved and restored. If None, defaults to the list of all saveable objects. It can be passed as a dict or a list:
- A dict of names to variables: The keys are the names that will be used to save or restore the variables in the checkpoint files.
- A list of variables: The variables will be keyed with their op name in the checkpoint files.
- For example:
v1 = tf.Variable(..., name='v1')
v2 = tf.Variable(..., name='v2')
# Pass the variables as a dict:
saver = tf.train.Saver({'v1': v1, 'v2': v2})
# Or pass them as a list.
saver = tf.train.Saver([v1, v2])
# Passing a list is equivalent to passing a dict with the variable op names
# as keys:
saver = tf.train.Saver({v.op.name: v for v in [v1, v2]})- max_to_keep
- indicates the maximum number of recent checkpoint files to keep.
- As new files are created, older files are deleted.
- If None or 0, all checkpoint files are kept.
Defaults to 5(that is, the 5 most recent checkpoint files are kept.) - 设置
max_to_keep=1则只保存最新的model,或者在使用save()方法保存模型时,保持global_step=None也可以达到只保存最新model的效果。
2、常用方法解析
# Returns a string, path at which the variables were saved.
save(
sess,
save_path,
global_step=None,
latest_filename=None,
meta_graph_suffix='meta',
write_meta_graph=True,
write_state=True
)
# The variables to restore do not have to have been initialized, as restoring is itself a way to initialize variables.
restore(
sess,
save_path
)二、参数的保存与恢复
1、检查点文件介绍
- 变量存储在二进制文件里,主要包含从
variable names to tensor values的映射关系- 当你创建一个
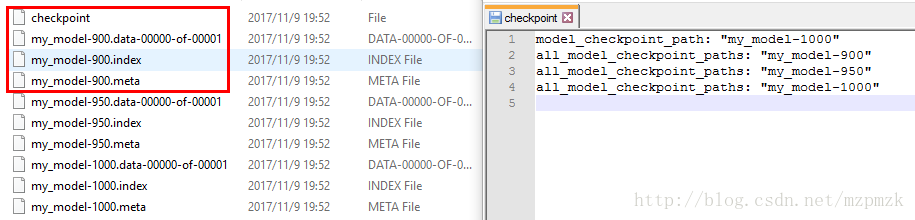
Saver对象时,你可以选择性地为检查点文件中的变量挑选变量名。默认情况下,将使用每个变量tf.Variable.name 属性的值。(这才是模型的参数,和变量名没有半毛钱关系)saver = tf.train.Saver(max_to_keep=3)时 checkpoint 保存的文件详情如下:
- 第一个文件保存了一个目录下所有
模型文件路径的列表- 第二个文件保存了我们的模型(variable names to tensor values)
- 第三个文件为索引
- 第四个文件为计算图的结构
2、保存变量&恢复变量
- 可以用一个
bool型变量is_train来控制训练和验证两个阶段,True表示训练,False表示测试tf.train.Saver()类支持在恢复变量时给变量重命名(改写原来变量中的name参数)
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
import tensorflow as tf
# Create some variables.
w = tf.get_variable("weight", shape=[2], initializer=tf.zeros_initializer())
b = tf.get_variable("bias", shape=[3], initializer=tf.zeros_initializer())
inc_w = w.assign(w + 1)
dec_b = b.assign(b - 1)
# Add an op to initialize the variables.
init_op = tf.global_variables_initializer()
# Add ops to save and restore all the variables.
saver = tf.train.Saver(max_to_keep=3)
isTrain = False # True 表示训练,False 表示测试
train_steps = 1000
checkpoint_steps = 50
checkpoint_dir = 'checkpoint/save&restore/'
model_name = 'my_model'
# Later, launch the model, initialize the variables, do some work, and save the
# variables to disk.
with tf.Session() as sess:
sess.run(init_op)
if isTrain:
# Do some work with the model.
for step in range(train_steps):
inc_w.op.run()
dec_b.op.run()
if (step + 1) % checkpoint_steps == 0:
# Append the step number to the checkpoint name:
saved_path = saver.save(
sess,
checkpoint_dir + model_name,
global_step=step + 1 # 设为 None 时,只保存最新结果
)
else:
print('Before restore:')
print(sess.run(w))
print(sess.run(b))
ckpt = tf.train.get_checkpoint_state(checkpoint_dir)
# 获取最新的 model_file
if ckpt and ckpt.model_checkpoint_path:
print("Success to load %s." % ckpt.model_checkpoint_path)
saver.restore(sess, ckpt.model_checkpoint_path)
else:
pass
print('After restore:')
print(sess.run(w))
print(sess.run(b))
# 测试结果
Before restore:
[ 0. 0.]
[ 0. 0. 0.]
Success to load checkpoint/save&restore/my_model-1000.
After restore:
[ 1000. 1000.]
[-1000. -1000. -1000.]
# 结论:restore 其实就相当于重新初始化所有的变量
# 结论分析
虽然官方文档说:restore 时不用使用 init_op 去初始化所有的变量了,但这里为了验证下(restore 其实就相当于重新初始化所有的变量),还是把 sess.run(init_op) 放在了if isTrain: 语句的上面(同时作用于训练和测试阶段), 从测试结果中可以验证结论。
# 其实可以把 sess.run(init_op) 放在 if isTrain: 语句的里面(只作用于训练阶段)3、取得可训练参数的值&提取某一层的特征
sess = tf.Session()
# Returns all variables created with trainable=True in a var_list
var_list = tf.trainable_variables()
print("Trainable variables:------------------------")
# 取出所有可训练参数的索引、形状和名称
for idx, v in enumerate(var_list):
print("param {:3}: {:15} {}".format(idx, str(v.get_shape()), v.name))
# 某网络输出示例
Trainable variables:------------------------
param 0: (5, 5, 3, 32) conv2d/kernel:0
param 1: (32,) conv2d/bias:0
param 2: (5, 5, 32, 64) conv2d_1/kernel:0
param 3: (64,) conv2d_1/bias:0
param 4: (3, 3, 64, 128) conv2d_2/kernel:0
param 5: (128,) conv2d_2/bias:0
param 6: (3, 3, 128, 128) conv2d_3/kernel:0
param 7: (128,) conv2d_3/bias:0
param 8: (4608, 1024) dense/kernel:0
param 9: (1024,) dense/bias:0
param 10: (1024, 512) dense_1/kernel:0 --->dense2 层的参数
param 11: (512,) dense_1/bias:0
param 12: (512, 5) dense_2/kernel:0
param 13: (5,) dense_2/bias:0
# 提取最后一个全连接层的参数 W 和 b
W = sess.run(var_list[12])
b = sess.run(var_list[13])
# 提取第二个全连接层的输出值作为特征
feature = sess.run(dense2, feed_dict={x:img})三、继续训练&Fine-tune 某一层
1、继续训练(所有参数)
# 定义一个全局对象来获取参数的值,在程序中使用(eg:FLAGS.iteration)来引用参数
FLAGS = tf.app.flags.FLAGS
# 定义命令行参数,第一个是:参数名称,第二个是:参数默认值,第三个是:参数描述
tf.app.flags.DEFINE_string(
"checkpoint_dir",
"/path/to/checkpoint_save_dir/",
"Directory name to save the checkpoints [checkpoint]"
)
tf.app.flags.DEFINE_boolean(
"continue_train",
False,
"True for continue training.[False]"
)
saver = tf.train.Saver()
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
if FLAGS.continue_train:
# 自动取得最新的 model_file
model_file = tf.train.latest_checkpoint(checkpoint_dir)
saver.restore(sess, model_file)
print("Success to load %s." % model_file)2、Fine-tune 某一层
- 更改网络中权重和偏置的参数,把需要固定不进行训练的变量的
trainable参数设置为False- 然后再使用上面的代码进行继续训练即可
eg:my_non_trainable = tf.get_variable("my_non_trainable", shape=(3, 3), trainable=False)- Restore a meta checkpoint(待总结?????)
- use the TF helper
tf.train.import_meta_graph()
四、参考资料
1、https://www.tensorflow.org/api_docs/python/tf/train/Saver
2、tensorflow 学习:模型的保存与恢复(Saver)
3、Tensorflow系列——Saver的用法
4、tensorflow 1.0 学习:参数和特征的提取
5、https://www.tensorflow.org/api_guides/python/meta_graph
6、https://blog.metaflow.fr/tensorflow-saving-restoring-and-mixing-multiple-models-c4c94d5d7125