正则表达式
**常用的正则表达式:**
\w: 匹配字母数字及下划线
\W:匹配非字母数字及下划线
\s:匹配任意空白字符an
\S:匹配非空白字符
\d:匹配任意数字,等价于0 - 9
\D:匹配任意非数字
\t :匹配一个制表符
\n:匹配一个换行符
^ :匹配字符串开头
$ :匹配字符串结尾
\A:匹配字符串开始
\Z:匹配字符串结束,如果存在换行,只匹配到换行前的字符结束
.:匹配除了换行符以外的任意字符
* :匹配 * 左边的第一个字符为0次或者出现无穷次
? :匹配?左边的第一个字符出现0次或者1次
+ :匹配 + 左边的第一个字符出现1次或者无穷次
{
} :匹配{
}左边的第一个字符出现的次数范围,取值按照范围内的最大值取值
| :匹配 | 左右值的任意出现
[] :匹配[]内的普通字符的任意一种,如果 - 没有被转义的话,应该放大[]的开头或者结尾
[ ^] :[]内加 ^ 代表匹配取相反
( ) :代表分组的意思
\ :用来转义
.* : 贪婪模式
.* ? :非贪婪模式
\d +\.?\d :匹配所有包含小数在内的数字
?: 可以让结果为匹配的全部内容
**正则匹配**
import re
print(re.findall("\w", "hello nana 123__。*")) #匹配字母数字及下划线
print(re.findall("\W", "hello nana 123__。*")) #匹配非字母数字及下划线
print(re.findall("\s", "hello 123 nana\n\t\r\f*-/..")) #匹配任意空白字符,等价于\n\t\r\f
print(re.findall("\S", "hello 123 nana\n \t *-/..")) #匹配任意非空白字符
print(re.findall("\d", "1253..5hello \nnana")) # 匹配任意数字,等价于0-9
print(re.findall("\D", "1253..5hello \nnana")) # 匹配任意非数字
print(re.findall("\t", "/c.txt \t \n nna123*-+")) # 匹配一个制表符
print((re.findall("\n", "sniwhijini\n-.25 \t"))) # 匹配一个换行符
print(re.findall("^alll", "alll.alll.alll leox23all")) #匹配字符串开头
print(re.findall("-sw$", "nans wmd-+*.,/? *-sw")) # 匹配字符串结尾
print(re.findall("\Ahello", "hello 123 nana。。。-/*")) # 匹配字符串开始
print(re.findall("alo123\Z", "hello 123 nana。。。alo123")) # 匹配字符串结束,如果存在换行,只匹配到换行前的字符串结束
print(re.findall("^nana$", '''
nana
ksiw
ksiws
nans
snsns
*-+
nana
''', re.M)) # ^开头加$结尾,末尾加上, re.M可以匹配多行开头加结尾
print(re.findall("\Anana\Z", '''
nana
ksiw
ksiws
nans
snsns
*-+
nana
''', re.M)) # 不可以匹配多行
print(re.findall("a.b", "a1b a2b a b abbbba a\nb")) # . 匹配除了换行符以外的任意字符
print(re.findall("a.b", "a1b a2b a b abbbba a\nb", re.S)) # 匹配包括换行符的任意字符
print(re.findall("a.b", "a1b a2b a b abbbba a\nb", re.DOTALL)) # 意思上面的re.S意思一样
print(re.findall("ab*", "a abbbbbbbbbbb aaa bbb")) # 匹配*左边的一个字符为0次或者出现无穷次
# ['a', 'abbbbbbbbbbb', 'a', 'a', 'a']
print(re.findall("ab?", "abbbb ab a 123 abbb")) # 匹配?左边的一个字符出现0次或者1次
# ['ab', 'ab', 'a', 'ab']
print(re.findall("ab+", "ab2 a abbbbbbb ab..")) # 匹配+左边的一个字符出现1次或者无穷次
# ['ab', 'abbbbbbb', 'ab']
print(re.findall("ab{2,4}", "b abb abbbbbbbb a\nb")) #匹配{
}左边的一个字符出现的次数或者次数范围
# ['abb', 'abbbb']
print(re.findall("ab|bc", "aaa bbb abb bac bcc")) #匹配|左右任意一个出现的,ab或者bc
# ['ab', 'bc']
print(re.findall('a[ 1*a-]b', 'a1b a*b a-b aab a b')) # 匹配[]内的普通字符,如果-没有被转意的话,应该放到[]的开头或结尾
# ['a1b', 'a*b', 'a-b', 'aab', 'a b']
print(re.findall("a[0-9]b", "a1b aab a b"))
# ['a1b']
print(re.findall("a[^0-9]b", "a1b aab a b")) #[]内加^代表匹配取相反
# ['aab', 'a b']
print(re.findall(r'a\\c', 'a\c')) #r代表告诉解释器使用rawstring,即原生字符串,把我们正则内的所有符号都当普通字符处理,不要转义
# ['a\\c']
print(re.findall('a\\\c','a\c')) #对于正则表达式来说,a\\c确实发生了转义,但是python解释器在监测语法的时候会先发生转义,然后再交给re取执行,所以应该加\\\ 或者\\\\都可以
# ['a\\c']
print(re.findall("(ab)+123", "aa123 bb123 ab123")) #()代表分组的意思,匹配到末尾的ab123中的ab
# ['ab']
print(re.findall("a.*b", "abbbbb\t1111 b22\n2b")) # 贪婪模式匹配,匹配换行符之前到最后一个b结束前面的所有字符
# ['abbbbb\t1111 b']
print(re.findall("a.*?b", "a123b123b")) # 非贪婪模式,匹配到第一个b结束
# ['a123b']
print(re.findall("\d+\.?\d", "123aaa11.2a33.2ll")) #匹配所有包含小数在内的数字
# ['123', '11.2', '33.2']
print(re.findall('(?:ab)+123', 'ab abab123')) # findall的结果不是匹配的全部内容,而是组内的内容,?:可以让结果为匹配的全部内容
# ['abab123']
print(re.findall('href="(.*?)"', '<a href="http://www.baidu.com">点击</a>')) #(.*?)括号加非贪婪模式的使用
# ['http://www.baidu.com']
序列化与反序列化:
什么是序列化:
我们把对象(变量)从内存变成可存储或传输的过程称之为序列化
为什么要用序列化:
1.把文件从内存读入文件,可以持久保持状态
2.跨平台数据交互
序列化
dic = {
"name": "nana"}
with open("a.txt", mode="wt", encoding="utf-8")as f:
f.write(str(dic))
反序列化
with open("a.txt", mode="rt", encoding="utf-8")as f:
res = f.read() # 读出来的结果是"{"name": "nana"}"
dic = eval(res) # eval()会把字符串里面的代码拿出来运行
print(dic["name"])
json
优点:python语言转成json格式后,格式通用,跨平台性强
缺点:python能支持转成json格式的类型有限
注意:json格式里面不能有单引号’'
json类型与python类型的转换
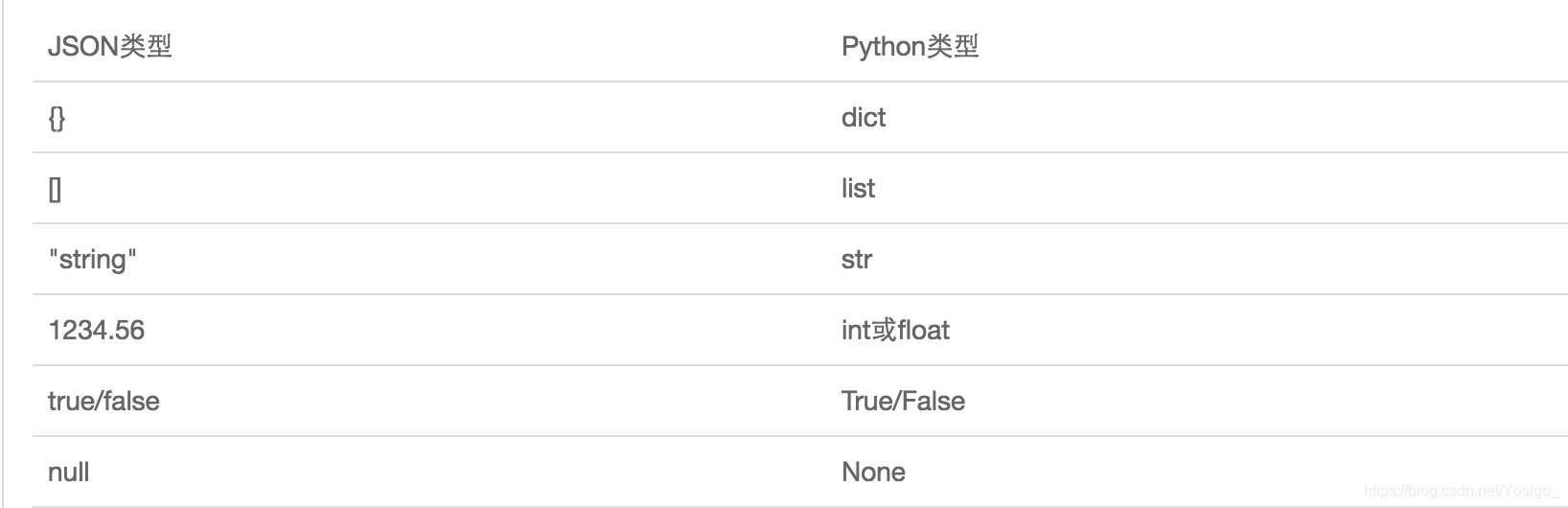
json格式的序列化:
import json
dic = {
"name": "nana", "aaa": True, "bbb": None, }
dic_json = json.dumps(dic) # 调用json.dumps()会直接把python语言转成json格式
# print(dic_json, type(dic_json))
with open("a.json", mode="wt", encoding="utf-8")as f:
f.write(dic_json)
json序列化存入文件的快捷用法
json.dump(dic, open("a.json", mode="wt", encoding="utf-8"))
json格式的反序列化:
with open("a.json", mode="rt", encoding="utf-8")as f:
res = f.read()
dic = json.loads(res) # 调用json.loads()会直接把json格式的文件反解成python语言
print(dic)
json反解序列化存入文件的快捷用法
res = json.load(open("a.json", mode="rt", encoding="utf-8"))
print(res)
dic = json.loads('{"k":true}') #{
'k': True}
print(dic)
pickle
优点:所有python的类型的可以转成pickle格式
缺点:无法跨平台
import pickle
pickle序列化
pickle.dump({
1, 2, 3, 4, 5, 6, 7}, open("b.pkl", mode="wb"))
pickle反序列化
pickle.load({
1, 2, 3, 4, 5, 6, 7}, open("b.pkl", mode="rb"))
猴子补丁
导入一个import模块,利用函数名称空间与作用域的关系,将函数内部的文件名覆盖原文件名
imoprt json
imoprt ujson
def mokey_patch_json():
json.dump = ujson.dump
json.dumps = ujson.dumps
json.load = ujson.load
json.load = ujson.loads
mokey_patch_json()
时间模块
import time
时间分为三种格式
print(time.time()) #主要用来参与时间运算的
格式化的字符串
print(time.strftime("%Y-%M-%D %H:%M:%S")) #主要用来记录时间,给人看的
结构化的时间
print(time.localtime())
res = time.localtime() #中国东八区时间
res2 = time.gmtime() #世界标准时间
案例:
计算三天后的时间
import datetime
print(datetime.datetime.now()) #格式是 2021-01-06 21:54:44.352055
print(datetime.datetime.now() + datetime.timedelta(days=3))
random模块
使用random模块随机生成数字或者字母
import random
print(random.random()) # 随机生成0-1之间的小数
print(random.randint(1, 3)) # 随机生成大于等于1且小于等于3之间的整数
print(random.randrange(0, 9)) # 随机生成大于等于0且小于9的整数
print(random.choice([1, "23", [4, 5]])) # 随机生成1,23或者[4,5]
print(random.sample([1, "23", [4, 5]], 2)) # 随机生成任意两个组合
print(random.uniform(1, 3)) # 随机生成大于1小于3的小数
item = [1, 3, 5, 7, 9]
random.shuffle(item) # 打乱item的顺序,相当于"洗牌"
print(item)
print(ord("A")) # ord会参照ACSII编码表把字母转成数字
print(chr(65)) # chr会参照ACSII编码表把数字转成字母
使用random编写一个随机生成验证码的小程序
import random
def make(n):
res = ""
for i in range(n):
s1 = chr(random.randint(65, 90)) # 65-90代表26个英文字母的ACSII编码表数字
s2 = str(random.randint(0, 9))
res += random.choice([s1, s2])
return res
print(make(4))