存储引擎
日常生活中,文件格式有很多种,并且针对不同的文件格式会有不同的存储方式和处理机制(txt,pdf,word,mp4。。。)
针对不同的数据应该有对应的不同的处理机制来存储
存储引擎就是不同的处理机制
mysql主要存储引擎
1.innodb
三大特点:事务,行级锁,外键
是mysql5.5版本之后默认的存储引擎
存储数据更加安全
2.myisam
是mysql5.5版本之前默认的存储引擎
速度要比innodb更快 但是我们更加注重数据的安全
3.memory
内存引擎(数据全部存放在内存中)断电数据丢失
4.blackhole
无论存什么都立刻消失(黑洞)
查看所有的存储引擎:show engines;
4种不同的存储引擎代码验证
不同的存储引擎在存储表的时候 异同点
用4种不同的存储引擎去建4张表
create table t1(id int) engine=innodb;
create table t2(id int) engine=myisam;
create table t3(id int) engine=memory;
create table t4(id int) engine=blackhole;
打开对应的文件目录:
innodb:t1.frm (表结构)
t1.ibd (表数据)
myisam:t2.frm (表结构)
t2.MYD (表数据)
t2.MYI (索引(index),基于索引查找数据,速度更快)
menory:t3.frm (表结构(数据在内存,无需文件存储))
blackhole:t4.frm (表结构(黑洞,不需要帮忙存数据)
存数据:
insert into t1 values(1);
insert into t2 values(2);
insert into t3 values(3);
insert into t4 values(4);
查数据:
select * from t1;
select * from t2;
select * from t3;
select * from t4;
创建表的完整语法
语法
creat table 表名(
字段名1 类型(宽度)约束条件,
字段名2 类型(宽度)约束条件,
字段名3 类型(宽度)约束条件,
)
注意:
1.在同一张表中字段名不能重复
2.宽度和约束条件是可选的(可写可不写),而字段名和字段类型是必须的
约束条件写的话 也支持写多个
字段名1 类型(宽度)约束条件1 约束条件2...
create table t5(id); 报错
3.最后一行不能有逗号
create table t6(
id int,
name char,
); 报错
宽度
一般情况下指的是对存储数据的限制
create table t7(name char); 默认宽度是1
insert into t7 values("nana"); 只存成功了一个字符,
insert into t7 values("null"); 关键字null(空)
针对不同的版本会出现不同的效果
如果没有开启严格模式,规定只能存一个字符你给了多个字符,那么我会自动帮你截取一个字符存储
如果开启了严格模式,那么规定只能存几个,就不能超,一旦超出范围就会立刻报错 Data too long for ...
严格模式到底要不要开?
mysql5.7之后的版本多是默认开启严格模式的
使用数据库的准则:
能尽量少让数据库干活就尽量少让数据库干活,不用给数据库增加额外的压力
约束条件null not null 不能插入null
create table t8(id int,name char not null);
宽度和约束条件到底是什么关系??
宽度是用来限制数据的存储
约束条件是在宽度的基础之上增加额外的约束
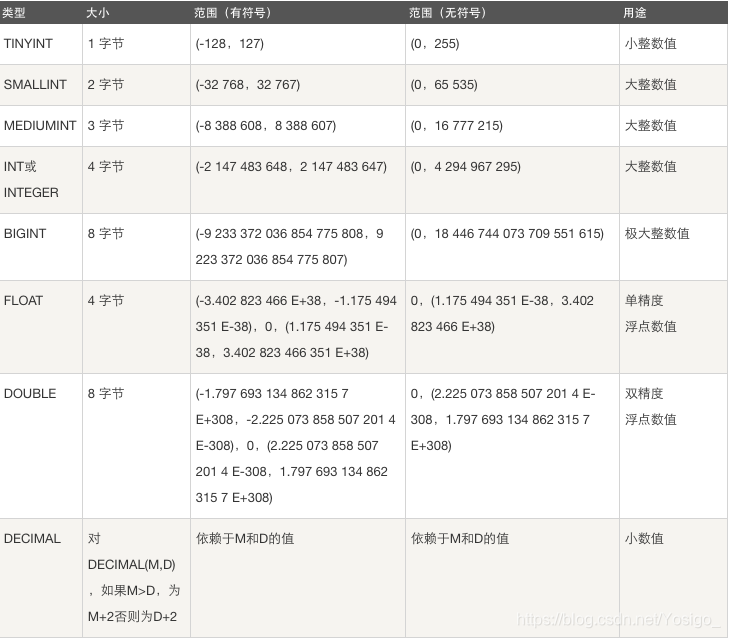
基本数据类型
整型类型
int的存储宽度是4个Bytes,即32个bit,即2**32
无符号最大值为:4294967296-1
有符号最大值:2147483648-1
有符号和无符号的最大数字需要的显示宽度均为10,而针对有符号的最小值则需要11位才能显示完全,所以int类型默认的显示宽度为11是非常合理的
最后:整形类型,其实没有必要指定显示宽度,使用默认的就ok
整型
分类
TINYINT SAMLLINT MEDUIMINT INT BIGINT
作用
存储年龄,等级,id,号码等等
以TINYINT为例:
是否有符号
默认情况下是带符号的
超出会如何
超出限制只存最大可接受值
命令验证
create table t9(id tinyint);
insert into t9 values(-129),(256);
select * from t9; (显示结果为(-128,127))
约束条件值unsigned 无符号,
命令验证
create table t10(id tinyint unsigned);
insert into t10 values(-1),(256);
select * from t10; (显示结果为(0,255))
验证int类型
create table t11(id int); (不写宽度,默认是11)
insert into t11 values(-1),(256);
select * from t11; (显示结果为(-1,256))
int默认也是带符号的
整型默认的情况下都是带有符号的
针对整型,括号内的宽度到底是干嘛的
create table t12 (id int(8));
insert into t12 values(123456789);
select * from t12; (显示结果为(123456789))
特例:只有整型括号里面的数字不是表示限制位数而是显示长度
id int(8);
如果数字没有超过8位,那么默认用空格填充至8位
如果数字超出了8位,那么有几位就存几位(但是还是要遵守最大范围)
命令验证:
create table t13(id int(8) unsigned zerofill); 无符号,默认用0填充
insert into t13 values(1); (数字不超过8位,用默认的0填充至8位)
insert into t13 values(112233445566778899);
select * from t13; (显示结果为(00000001)(4294967295))
总结:
针对整型字段 括号内无需指定宽度 因为它默认的宽度已经足够显示所有的数据了
严格模式
如何查看严格模式命令 show variables like "%mode";
sql_mode(严格模式)
模糊匹配/查询
关键字 like
%:匹配任意多个字符
_:匹配任意单个字符
修改严格模式
set session 只在当前窗口有效(临时修改)
set global 全局有效
修改成严格模式完整命令:
set global sql_mode="STRICT_TRANS_TABLES";
修改完之后 重新进入服务端即可
修改完严格模式,如果是字符或者整型超出范围会直接报错,而不会让数据库去自动截取数据。
浮点型
分类
float,double,decimal
作用
身高,体重,薪资
存储限制
float(255,30) 总共255位 小数部分占30位
double(255,30) 总共255位 小数部分占30位
decimal(65,30) 总共65位 小数部分占30位
精确度验证
create table t15(id float(255,30));
create table t16(id double(255,30));
create table t17(id decimal(65,30));
insert into t15 values(1.111111111111111111111111111111);
insert into t16 values(1.111111111111111111111111111111);
insert into t17 values(1.111111111111111111111111111111);
select * from t15; 显示结果( 1.111111164093017600000000000000)
select * from t16; 显示结果( 1.111111164093017600000000000000)
select * from t17; 显示结果( 1.111111111111111111111111111111)
精确度 :float<double<decimal
字符类型
char
定长
char(4) 数据超过四个字符直接报错 不够四个字符空格补全
varchar
变长
varchar(4) 数据超过四个字符直接报错 不够有几个存几个
定长与变长的差别代码验证
create table t18(name char(4));
create table t19(name varchar(4));
insert into t18 values("a");
insert into t19 values("a");
select * from t18;
select * from t19;
介绍一个小方法 char_length统计字段长度
select char_length(name) from t18; (长度显示为1)
select char_length(name) from t19; (长度显示为1)
首先可以肯定的是char硬盘上存的绝对真正的数据,带有空格的
但是在显示的时候mysql会自动将多余的空格操作剔除
修改sql_mode 让mysql不要自动剔除操作
set global sql_mode=
"STRICT_TRANS_TABLES,PAD_CHAR_TO_FULL_LENGTH"; (全局添加替换操作,不是添加PAD_CHAR_TO_FULL_LENGTH)
重新统计字段长度
select char_length(name) from t18; (长度显示4)
select char_length(name) from t19; (长度显示1)
char与varchar对比
char
缺点:浪费空间
优点:存取都很简单
直接按照固定的字符存取数据即可
jason nana marker
存按照五个字符存 取也按照五个字符取
varchar
优点:节省空间
缺点:存取较为麻烦
1bytes+jason 1bytes+nana 1bytes+marker
存的时候需要制作报头
取的时候也需要先读取报头 之后才能读取真实数据
以前基本数都是用的char 现在用varchar的也挺多的(存取使用char,或者varchar都可以)
补充:
进了公司之后完全不需要考虑字段类型和字段名
因为产品经理会给你发的邮件上已经全部指明了
时间类型
分类
date:年月日 2021-2-7
datetime:年月日时分秒 2021-2-7 11:11:11
time:时分秒11:11:11
year:2021
时间类型代码演示
create table student(
id int,
name varchar(16),
born_year year,
birth date,
study_time time,
reg_time datetime # 注意最后一个数据结束不需要加逗号
);
insert into student values(1,"nana","2000","2000-11-11","11:11:11","2021-11-11 11:11:11");
desc student
select * from student
枚举与集合类型
分类
枚举(enum)多选一 enumerate
集合(set)多选多
枚举的具体使用代码演示
create table user(
id int,
name char(16),
gender enum("male","female","other")
);
insert into user values(1,"nana","male"); 正常
insert into user values(2,"dudu","xxxooo"); 报错
desc user
select * from user
枚举字段 后期在存数据的时候只能从枚举里面选择一个存储
集合的具体使用代码演示
create table teacher(
id int,
name char(16),
gender enum("male","female","other"),
hobby set("read","run","basketball")
);
insert into teacher values(1,"nana","female","read"); 正常
insert into teacher values(2,"dudu","male","basketball,run"); 正常
insert into teacher values(3,"dada","other","干饭"); 报错
集合可以只写一个 但是不能写没有列举的