目录
最开始,kaiming提出resblock是为了分类问题,作为cv最基础的问题,无疑其他domain也纷纷借鉴,以resblock为cell的网络结构铺天盖地席卷而来…
1.最开始的resblock

2.resblock 进化
BatchNorm/InstanceNorm/…Norm出现的时候,basic block最常用的就是Conv+BN+Relu+Conv+BN 模式侧边分支的模式,一定要记住的是,侧边分支最后一个一定不能是relu,残差块残差块,有正有负才能修复identity(identity就是下图灰色的箭头中的线)。
·
之后有文章对上面结构做出改进,准确的说是改变了模块顺序。得到修正后的basick block模块如下。
为什么新的结构好那?作者推导了公式(下面有推导),证明这样子在backward的时候梯度可以完全往回传导,所以这样子才是最佳的resblock。
其次,随着BN/IN等在high-level里的活跃,dropout慢慢淡出了人们视野,毕竟都是正则,前者主流,但是仍然有人往里面增加dropout,尤其是生物医学图像数据集(更容易过拟合),所以大家把各种正则手段都拿了出来(个人愚见…)。
2.1为什么新的block可以work?
在kaiming的Identity Mappings in Deep Residual Networks中,有一幅图展示了哪种resblock比较好,下图是在CIFAR-10上使用1001-layer ResNets的结果。可以看到新的unit是的resnet更加容易训练。

2.2 简单的推导
简单解释一下为什么这么做梯度不会消失。定义xLx_LxL是深度L层的单元,loss function是ϵ
根据链式法则,loss function回传到第L层可以拆解成两项:
![]()
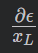 可以保证loss function可以返回第L层。
可以保证loss function可以返回第L层。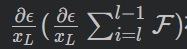 在一个mini-batch中不总是为-1。所以loss function回传到第L层的梯度不会为0。(论文没解释为什么不总是为-1,有点疑惑)
在一个mini-batch中不总是为-1。所以loss function回传到第L层的梯度不会为0。(论文没解释为什么不总是为-1,有点疑惑)
2.3 identify的重要性

还是Identity Mappings in Deep Residual Networks这个论文。kaiming尝试了不同的组合(美观期间没有画出BN)。
这里有个非常重要的结论:identify那条线非常重要,谨慎修改,注意就连上面放一个1x1的conv都会大幅度削减error!(但是放一个1x1的conv情况下resnet34效果却有提升。。所以实验结论是block数目变多后,放一个1x1的conv在identify上效果变差)
Note:上表验证了图中6种组合的性能,实验在CIFAR-10 test set,使用了ResNet-110
2.4 BN/ReLU的顺序?

还是Classification error (%) on the CIFAR-10 test set 。最好的方式是图中e。请大家务必细品上图/表!!!
2.5 常用的特征提取模块
一般常用的有ResNet18,ResNet34,ResNet50,ResNet101,ResNet152,这些结构经常用来进行特征提取,比如deeplabv3+encoder中就使用了ResNet101作为backbone。kaiming这几种特征提取网络,网络越深,效果自然越好。
这是原文中,分类问题的结构与网络FLOPs。一般torch等框架里包含有相应模块。
3 ResNeXt的出现
经历了Res-Net的成功,kaiming在2017cvpr上提出了其改进版ResNeXt(论文名:Aggregated Residual Transformations for Deep Neural Networks)。后面的四个字母是next,表示下一个的意思。
3.1 引入cardinality(基数)

对于resnet中的bottleneck,在channel维度上进行了分组,上图中的cardinality是32,也就是分成32组channel数目更小的统一单元。细心的朋友就会发现,64 不等于 4x32啊,为什么这么分?
因为他们的计算量是近乎相同的。(卷积核如何计算参数量,详见最近整理的一个博文——传送门)
- 左图是256 · 64+ 3 · 3 · 64 · 64+ 64 · 256 ≈ 70k
- 右图是C · (256 · d + 3 · 3 · d · d + d · 256),C = 32 and d = 4刚好差不多70k。
就是这么个意思。右图也是本文的核心。
3.2 bottleneck/basicblock的改进
1.当depth>=3的时候:

如上图,ResNeXt可以从三种角度去看,这三种是等效的。我在图上有一些注释,总之请大家细品三幅图。
2.当depth=2的时候,也就是BasicBlock:
此时,并不等效于分组卷积。因为分组卷积in_channel 和 out_channel 都必须分组,大家看图左,只有一端才分组(对比bottleneck那个图b),所以BasicBlock无法改进。
3.3 改进后的提升

1x64d就是Res-Net的设置,32x4d就是上一章节的bottleneck设置,分成32组。
4.之后的Dense-net
然后就是denseblock了,其实我感觉就是连接更加dense,不同层次特征都连上,效果肯定提高了。但是这玩意显存占用就没法提了(因为有点多)