文章目录
前言
1、如何打开文件
使用open函数
- 格式:
open('path','mode')
| 模式 | 描述 |
|---|---|
| r | 默认模式:以只读方式打开文件,文件的指针将会放在文件的开头 |
| r+ | 打开一个文件用于读写,文件指针将会放在文件的开头 |
| w | 打开一个文件只用于写入,如果该文件已存在则打开文件,并从开头开始编辑,会覆盖原文件的内容;如果该文件不存在,创建新文件 |
| w+ | 打开一个文件用于读写,如果该文件已存在则打开文件,并从开头开始编辑,会覆盖原文件的内容;如果该文件不存在,创建新文件 |
| a | 打开一个文件用于追加,如果该文件已存在,文件指针将会放在文件的结尾,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入 |
| a+ | 打开一个文件用于读写,如果该文件已存在,文件指针将会放在文件的结尾,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入 |

(1)读取文件内容:r
先编辑一个hello.txt文件
f=open('hello.txt', mode ='r') ## 打开的文件名,模式(mode也可以不写直接写‘r’)
f1=f.read()
print(f1)
输出:
hello python
hello java
hello linux
(2)写入文件内容:w
f=open('hello.txt','w')
f1=f.write('hello world')
print(f1)
输出:11 ##返回写入的总字节数
(3)追加文件内容:a+
f=open('hello.txt','a+')
f1=f.write('hello linux')
print(f1) ## 返回写入的总字节数
2、文件操作方法
(1) read() 方法用来直接读取字节到字符串中, 最多读取给定数目个字节. 如果没有给定 size 参数(默认值为 -1)或者 size值为负, 文件将被读取直至末尾
(2)readline() 方法读取打开文件的一行(读取下个行结束符之前的所有字节). 然后整行,包括行结束符,作为字符串返回
f=open('hello.txt','r')
f1=f.readline()
print(f1) ## hello world
(3)readlines():读取所有(剩余的)行然后把它们作为一个字符串列表返回
f=open('hello.txt','r')
f1=f.readlines()
print(f1)
输出:
['hello world\n', 'hello linux']
(4)f.close() :关闭文件
(5)f.seek() :对文件进行指针偏移操作,有三种模式
seek(0,0) 默认移动到文件开头或简写成seek(0)
seek(x,1) 表示从当前指针位置向后移x(正数)个字节,如果x是负数,则是当前位置向前移动x个字节
seek(x,2) 表示从文件末尾向前后移x(正数)个字节,如果x负数,则是从末尾向前移动x个字节
(6)f.tell():显示当前文件的指针所在位置
- 可以使用with语句打开文件,不需要关闭,可以同时打开多个文件
with open('hello.txt','a+') as f: ## 打开文件
print(f.tell()) ## 当前指针位置 24
f.seek(0,0) ## 指针移动到文件开头
print(f.tell()) ## 0
f.seek(0,1) ## 当前指针位置向后移动0个字节
print(f.tell()) ## 0
f.seek(0,2) ## 指针移动到文件末尾
print(f.tell()) ## 24
3、好用的os模块
Python的os模块提供了执行文件处理操作的方法
3.1 查看系统的信息
import os
print(os.name) ## 获取操作系统类型
print(os.environ) ## 获取系统的环境变量
print(os.getcwd()) ## 查看当前目录
3.2 目录名和文件名拼接
- os.path.dirname获取某个文件对应的目录名
- __file__当前文件
- join拼接, 将目录名和文件名拼接起来
import os
BASE_DIR=os.path.dirname(__file__)
file=os.path.join(BASE_DIR,'test.txt')
print(file) ## E:\pythonProject\运维Python\day4\test.txt
4、json模块的使用
4.1 将python对象编码成json字符串
import json
users = {
'name':'westos', "age":18, 'city':'西安'}
json_str = json.dumps(users)
with open('doc/hello.json', 'w') as f:
# ensure_ascii=False:中文可以成功存储
# indent=4: 缩进为4个空格
json.dump(users, f, ensure_ascii=False, indent=4)
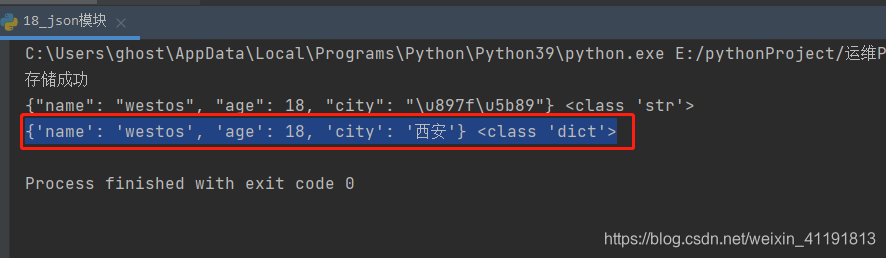
print("存储成功")
print(json_str, type(json_str))


4.2 将json字符串解码成python对象
with open('doc/hello.json') as f:
python_obj = json.load(f)
print(python_obj, type(python_obj))
5、怎么把文件转换成excel文件存储
5.1 安装pandas
默认外网很慢,可以换成国内源,如这个豆瓣的
"""
如何安装pandas?
> pip install pandas -i https://pypi.douban.com/simple
如何安装对excel操作的模块?
> pip install openpyxl -i https://pypi.douban.com/simple
"""
5.2 生成excel文件
import pandas
hosts = [
{
'host':'1.1.1.1', 'hostname':'test1', 'idc':'ali'},
{
'host':'1.1.1.2', 'hostname':'test2', 'idc':'ali'},
{
'host':'1.1.1.3', 'hostname':'test3', 'idc':'huawei'},
{
'host':'1.1.1.4', 'hostname':'test4', 'idc':'ali'}
]
# 1. 转换数据类型
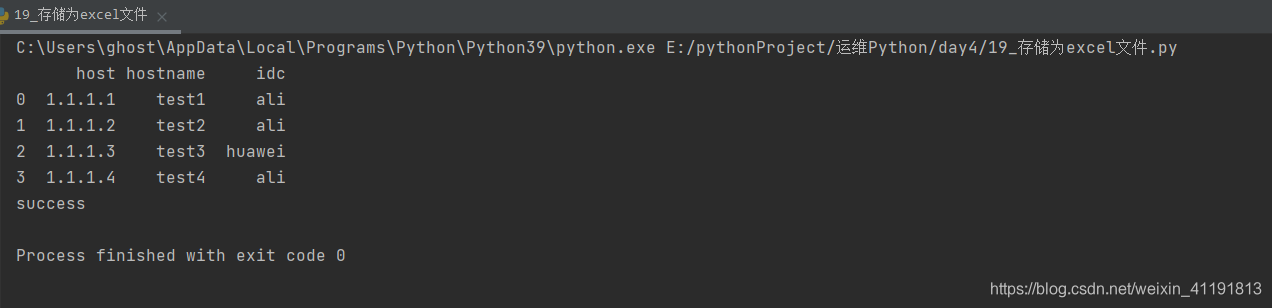
df = pandas.DataFrame(hosts)
# print(df)
# 2. 存储到excel文件中
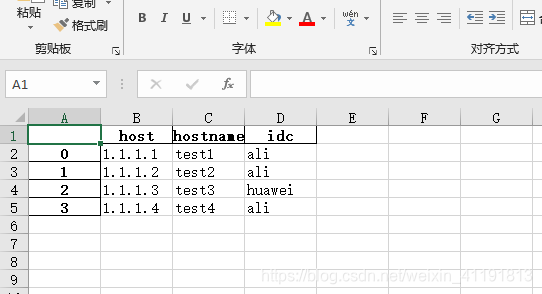
df.to_excel('doc/hosts.xlsx')
print('success')
6、练习题-词频统计
- 读取文件,统计每个单词出现的次数
(1)方法一
with open('hello.txt') as f:
words = f.read().split()
dick1 = {
}
for word in words:
if word in dick1:
dick1[word] += 1
else:
dick1[word] = 1
print(dick1)
输出:
{
'hello': 5, 'world': 2, 'linux': 2, 'k8s': 1, 'os': 1, 'windows': 1}
(2)方法二
from collections import Counter
with open('hello.txt') as f:
words = f.read().split()
Count = Counter(words)
print(Count)
输出:
Counter({
'hello': 5, 'world': 2, 'linux': 2, 'k8s': 1, 'os': 1, 'windows': 1})