学习 python 文件操作之前,首先要知道我们一般在电脑图形化界面上是如何操作的:
1、根据存放在电脑硬盘上的文件路径找到文件
2、通过系统自带的软件或者第三方软件打开选择的文件
3、进行阅读浏览或者增删改查等等…
4、操作完成后需要关闭文件或者保存关闭文件(不然占用计算机运行内存)
其实在 python 里面操作文件还是挺容易的,还记的当初学 NodeJS 的时候还要引入一个对应的模块才能进行操作,在 python 里面可以直接用对应的操作文件的内置函数就可以了。
open() : open 函数是 python 里面用来操作文件模块的函数,好几个参数和对应值,其实可以把他当作一个 json 对象,和 json 对象不同的是它不是 {} 来开始和结束的。
我现在在桌面创建一个文件夹,就叫做:demo,里面有两个文件,一个是我要编写的 python 代码,叫 app.py ,另一个是文本文件取名为 name.txt , 我现在来获取用 open() 获取 name.txt 的文本内容,文本内容如下
hello word
app.py 文件内容如下:
# 获取文件函数 open()
# 参数1 file="文件路径"
# 参数2 mode="操作文件的方式" r 代表文本只读模式
# 参数3 encoding="文件路径" 设置字符编码,通常都用 utf-8
files = open(file="./name.txt",mode="r",encoding="utf-8")
在这里我设置了一个变量 files 等于操作这个文件的方法,那么在这个文件下面也有好几个方法,先说说获取文件和关闭文件。
.read() : 获取文件内容
.close() : 关闭文件
# 获取文件
files = open(file="./name.txt",mode="r",encoding="utf-8")
# 将获取到的内容赋值给变量 data
data = files.read()
# 将获取的内容打印出来
print(data)
# 查看完成后直接关闭打开的程序
files.close()
>> hello word
上面方法是按照严格意义上来操作的,我个人对学习操作还是比较严谨的,如果你可以确定你打开的文件本身就是 utf-8 的编码文件的话,其实你 encoding="utf-8" 可以不用写,甚至 mode 权限也可以省略掉,如:
files = open(file="./name.txt")
data = files.read()
print(data)
files.close()
>> hello word
当然,还可以更加省略,连 file 都不用写,直接写上路径,如:
files = open("./name.txt")
data = files.read()
print(data)
files.close()
>> hello word
当然如果在你不知道这个文件是什么编码格式的时候你读到的文件只会乱码,所以需要换一种操作模式,你可以换成 二进制 的操作模式,也就是说,系统怎么存储,就以什么格式读取出来,当取到二进制数据的时候 python 会自动转化成 十六进制,拿到的数据就变成了 十六进制 的数据了,具体操作如下:
我将 name.txt 内的数据修改成中文编码 gb2312 ,并且将内容改成中文,如:
中国无敌
然后 python 代码,将 mode 的属性值从 r 后面加一个 b ,b 本身代表了 二进制 ,所以这里是以 二进制 的形式读取:
files = open(file="./name.txt", mode="rb")
data = files.read()
print(data)
files.close()
>> b'\xd6\xd0\xb9\xfa\xce\xde\xb5\xd0'
可以看到拿到的 python 已经拿到了 2进制 数据,因为 python 内置的是 16进制 ,所以 二进制 的数据是以 16进制 的方式显示出来了,这种操作模式一般是网络传输的时候用的,例如前端获取一个下载地址,python 作为后端将它输出,因为当不知道文件的字符编码的时候 python 无法读取到里面真正的内容,只能进行 二进制流 的数据传输,由其他客户端或用户电脑的编码支持进行释放内容。
如上方,如果在我不知道这个编码格式的时候我又要取到这里的文件内容,那么原生 python 是根本无法支持的,那么这个时候又该怎么办呢,其实在 python 中确实不支持,可是 python 也有属于他自己的生态库。例如 NodeJs 的 NPM 生态库,里面有各种各样给 NodeJS 提供的插件,也是我大前端发展至今必不可少功臣。那么 python 的生态库又是怎样的呢?
和 NodeJS 一样,在你安装了 Node 运行环境后会自带一个 NPM ,那么在 python 里面只要你安装了 python ,那么必定会有一个 pip 的工具,我这边苹果电脑自带一个 python2 版本的环境,所以他也必定有一个 pip 的工具,当我安装完 python3 后,我电脑上又多了一个 pip3 ,pip3 是 pip 的升级版,如 py2 和 py3 一样,我在我电脑上分别试一下自带的 pip 和 py3 自带的 pip3,如:
首先来看看我自带的 pip :
当你看到这个界面的时候就代表你电脑上确实安装了 pip ,可以通过 pip 来安装一些扩展应用程序
再来看看,我安装 py3 的时候自带的 pip3 :
接下来就可以去 pip 官网查找一些关于 python 的一些第三方模块包了,pip 官网是:https://pypi.org/
我在官网找到了一个 python 的编码判断工具包,是根据转化出来的 二进制 数据来判断的,几率不是百分之百准确,因为没有百分之百准确的编码判断,但是他可以自动匹配出几率最高的一个编码,这个工具包的名字叫做:chardet 如下:
我点击第一个进去 chardet 3.0.4 这是版本最高的一个,应该是目前编码支持度最好的一个了,进去之后看到了如下界面:
继续往下翻动,可以看到操作流程,包括怎么下载的和怎么使用的一些方法,如:
要想使用必须先安装,这里列出了下载方法,我根据这个方法进行安装:
pip3 install chardet
我是在 python 的 ide 编辑器(pycharm)中安装的,当看到以下界面就代表安装成功了:

在 pip 官网上并没有改插件的操作方法,但是他把文档地址给贴出来了,我们可以去他的文档url地址里面看看:
当进入文档后可以看到他有贴出 基本用法,我们去看看:
进入基本用法的文档后可以看到这个界面:
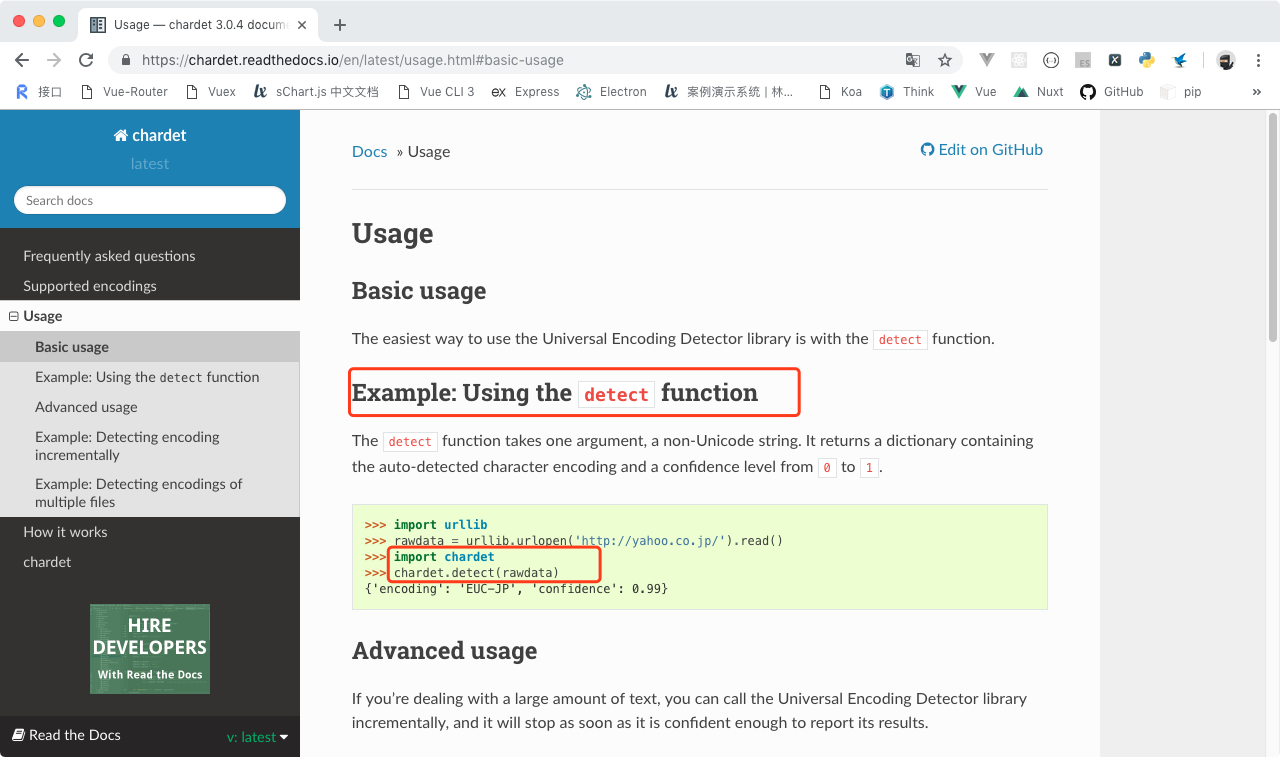
这里介绍了一个函数方法,叫做 detect()
我在程序里面根据他的方法测试一下,如:
# 引入模块包
import chardet
# 文件内容
files = open(file="./name.txt", mode="rb").read()
# chardet 工具包内置的测试 detect函数 转码,打印出来是字典数据类型
data = chardet.detect(files)
print(data)
>> {'encoding': 'IBM855', 'confidence': 0.5119798157077455, 'language': 'Russian'}
#惊呆了,我明明设置的是 GB2312 怎么变成了 IBM855
# 通过字典 get 方法取到 encoding 编码格式
code = data.get('encoding')
# 再通过内置函数进行解码
text = files.decode(code)
print(text)
>> ол╣Щ╬яхл
嗯?惊呆了,我不知道为什么会失败,我努力分析了很久。这个包是根据二进制字节判断的,难道是字节不够长,产生的误差吗?我重新在 name.txt 加入一段 ‘中国无敌’ 现在一共又八个字 中国无敌中国无敌,我重新测试一遍。
# 引入模块包
import chardet
# 文件内容
files = open(file="./name.txt", mode="rb").read()
# chardet 工具包内置的测试 detect函数 转码,打印出来是字典数据类型
data = chardet.detect(files)
print(data)
>> {'encoding': 'GB2312', 'confidence': 0.99, 'language': 'Chinese'}
# 通过字典 get 方法取到 encoding 编码格式
code = data.get('encoding')
# 再通过内置函数进行解码
text = files.decode(code)
print(text)
>> 中国无敌中国无敌
果然还是字节太少产生的判断失误,看来也要又一定的量级才能够将判断正确的比例拉大,但是这已经很不错了。虽然有点坑,但是作为一个标准的程序员,本身就要有面对挫折勇于接受并且克服困难的决心,并且要谨记尽量少在一个坑里多掉几次。
其实上面介绍了怎么读文件,可是真正当读取一个文件的时候,当一个文件内容太庞大,如果有好几个 G 的容量,一次性读取出来,那么就需要很久很久了,最简单的例子就是多媒体文件,像什么视频、音乐等文件,那么在这种情况下,该怎么保证性能和速度的前提下去操作呢?
其实可以用循环来读取,可是循环的话,还是需要判断字符编码,在判断字符编码之后才能进行循环,否则判断字符编码,需要一段时间,然后读取又需要一段时间,在加上 python本省是一门高级编程语言,运行速度有限,不像底层的 c 和 c++ 等 ...
所以可以这么操作,读文件的时候首先,你服务器上得有文件,所以一开始必须是用户上传文件,在用户上传文件的时候你不管三七二十一先直接接收了,然后给客户端返回一个 code 等于 200 ,不占用用户的时间,然后上传完文件在用户不知道的情况下,后台重新读取文件,判断字符编码,然后以 utf-8 的编码格式存储起来,然后在用户需要读取的时候,就什么也不用管了直接以 utf-8 的编码格式循环读取,直接返回给客户端,这样一来就不会占用用户的时间,而且这种方式更加友好,但是怎么循环呢?如下操作:
我先在网上随便下载一个小说文件,并且转成 utf-8 的编码格式,然后我就直接以 utf-8 的编码方式使用循环读取,小说名为:all.txt ,我在 pycharm 里面打开,拖到最下面可以看到有七万多行,一共有6.02mb:

现在我直接用以下循环代码去读它:
# 获取文件
files = open(file="./all.txt",mode="r",encoding="utf-8")
# 循环整个文件
for i in files:
# 依次打印
print(i)
#读取完文件关闭文件
files.close()
执行结果如下:
它被依次打印出来了,并且小说里面的换行它里面也会换行,其实用户每一个文件里面的换行,可能用户自己不知道,也看不到,他是有一个换行符的 \n 那么 python 是根据换行符来读取的,一段一段的往外输出,所以就是我现在 python 控制台当中的这个样子。
写文件
现在开始说一说写文件,如上方所说,在用户上传完文件后,我不可能直接将用户的文件转成 utf-8 的编码,我需要在用户上传完毕后,通过第三方扩展包,去读文件,判断文件什么类型,然后再以文件类型去读取,最后在新建一个文件,以 utf-8 的编码格式转换,依次循环写入,当写入完成后,删除用户的原有文件,并且依次命名,但是首先先来看看什么是写文件。
#在这里 mode 的值写成 w 代表的就是写入文件,和 r 一样 也可以以二进制写入 wb
files = open(file="./写入的文件.txt",mode="w")
#write() 方法是 open 下的写入文件的方法,默认编码格式为 utf-8
#也可以追加一个参数为 encode('utf-8') 如:
#files.write('hello word',encode('utf-8'))
files.write('hello word')
files.close()
在执行上面代码前我的 demo 文件夹里面只有 app.py 、name.txt、 all.txt 这三个文件,并没有 写入的文件.txt ,因为在写入文件的时候 python 会自动判断你的文件里面是否有这个文件,如果该名称文件不存在,会自动创建该名称文件,并且写入对应的数据,当然,如果你已经存在了一个文件并且这个文件里面已经有了一些内容,那么你写入的内容不会追加在你的内容后面,而是相当于你的内容全部清空然后把重新写的内容给覆盖进去,那么如何在已有的文件里面追加内容呢?如下:
#在这里 mode 的值写成 a 代表的就是追加模式,和 r 一样 也可以以二进制写入 wb
files = open(file="./写入的文件.txt",mode="a")
#write() 方法是 open 下的写入文件的方法,默认编码格式为 utf-8
#也可以追加一个参数为 encode('utf-8') 如:
#files.write('hello word',encode('utf-8'))
files.write('hello word')
files.close()
可以看到上方 追加模式 的代码个 写入模式 的代码基本一摸一样,唯一不一样的就是 mode 的 value 值,当 value = r 代表读文件,当 value = w 等于写模式,当 value = a 代表追加模式,再次运行程序后打开 写入的文件.txt 发现 内容变成了 hello wordhello word
上面说了三种操作文件的方法,文件读取,文件写入和文件追加,但是都不能向电脑图形化界面系统一样边读边写,那么如果我现在有一百行代码,我需要一直读取读到第五十行代码的时候把它改掉,然后继续往下读,这样我应该怎么操作呢?
如我现在把 写入的文件.txt 全部手动清空,然后通过循环写入一百行代码如:
files = open(file="./写入的文件.txt",mode="a")
num = 0
while num<100:
num += 1
files.write('第'+str(num)+'行:hello word\n')
files.close()
当执行完后,在我的 pycharm 里面看看是否写入成功了:
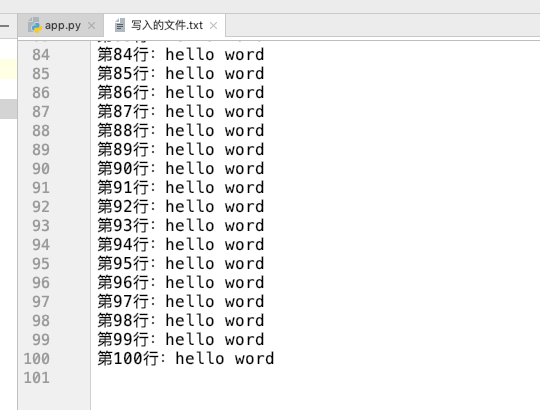
可以看到写入成功了,但是有一个小问题,那就是出现了 101 行,可能是因为我在写入的时候加了一个换行符 \n 的原因,那么我现在再次清空,在循环里面加入一个判断:
files = open(file="./写入的文件.txt",mode="a")
num = 0
while num<100:
num += 1
files.write('第' + str(num) + '行:hello word') if num == 100 else files.write('第'+str(num)+'行:hello word\n')
files.close()
再次打开 写入的文件.txt 文查看:
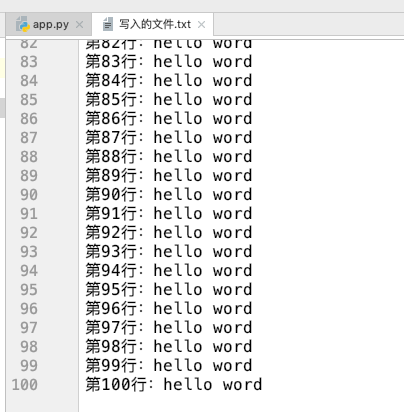
这次就刚好了,一百行,一行不多一行不少,那么现在我想更改第五十行的代码该怎么办呢?如果按照上面介绍的三种方式肯定是不行的,所以接下来要介绍一种 混合模式,什么是 混合模式 呢?
混合模式就就是既可以读数据,也可以写数据,当然和上面三种方式一样,都是在改变 mode 的 value 值 :
r+ : 读写模式
w+ : 写读模式
如上方,读写模式和写读模式区别在于哪里呢,先来看看读写模式:
files = open(file="./写入的文件.txt",mode="r+")
#已经存在的文件
data = files.read()
print(data)
# 测试分隔符
print('--------------------')
# 新加入的内容
files.write('\n123123')
# 新加完数据之后重新读取
print(files.read())
# 关闭文件
files.close()
我先不去看他的运行结果,按照正常的逻辑来说,运行最后的结果应该是打印了三次,第一次把原有的数据打印出来,第二次打印分隔符,第三次把已有的内容和新增的内容全部加在一起打印出来,可是当我真正运行后看到我的运行结果后,我就蒙蔽了,如:
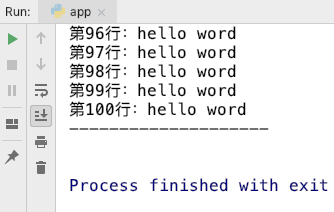
what? 怎么会这样,在分隔符后面啥也没有,不是按照正常的后面应该还有一段 123123 吗?我打开 写入的文件.txt 看了看,发现其实内容是写进去了的,确实,我是先读取了数据,然后在写入了,都成功了,但是为什么写入之后就读取不到了呢?
其实答案很简单,就和我们在电脑上写文字一样,他是有一个光标的,读取文件的时候光标一直往下走,就一次性走到了最后,然后你每次写入一个字符集进入文件,就像你每次打了一个字,光标始终会在最后一个,所以光标后面始终是没有数据的,但是当你第二次执行读文件的时候就会发现,之前添加的文件,其实是可以打印出来的。
上面这种方式就叫做读写模式,那么看看混合模式的第二种,写读模式:
files = open(file="./写入的文件.txt",mode="w+")
#已经存在的文件
data = files.read()
print(data)
# 测试分隔符
print('--------------------')
# 新加入的内容
files.write('\n123123')
# 新加完数据之后重新读取
print(files.read())
# 关闭文件
files.close()
和读写模式一样,我只是把 r+ 换成了 w+ ,我现在运行程序,这个时候发现除去测试分隔符之外什么都没打印出来,我去到文件里面看看,发现整个内容只有两行,第一行什么也没有,第二行是 123123,可能从字面上的意思上来说 读写模式 和 写读模式 并没有什么很大的差异,但是 写读模式 基本上用的很少,可以说用不到,因为 写读模式 是用 写文件的方式 优先清空文件内所有信息,然后再读取,但是文件输入的 光标 在写完了之后还是走到了最后 ,所以它读到的数据是空的。这就是 混合模式,我们如果做内容修改的话,文件的 混合模式 是必学的一个知识点,然后就是如何控制输入的光标,这样我们就可以随意的读取文件任意部分的内容了。
其实文件操作还有很多方法,包括如何操作 光标 之类的,先别急,我一个一个来演示:
flush() : 刷新文件内部缓冲区,直接把内部缓冲区的数据写入文件,而不是被动的等待输出缓冲区写入
readable() : 判断文件是否可读
readline() : 读取整行,包括 ‘\n’ 换行字符在内
next() : 返回文件下一行
tell() : 返回文件内光标的所在位置
seek() : 设置文件内光标的当前位置
seekaable() : 判断文件是否可以进行 seek() 方法操作
writeable() : 判断文件是否可以写入
readlines() : 读取所有行,并返回列表
read() : 读取文件内容
fileno() : 方法返回一个整型的文件描述符(file descriptor FD 整型),可用于底层操作系统的 I/O 操作
isatty() : 如果一个文件连接到终端设备返回 True,否则返回 False
writelines() : 像文件写入一个序列的字符串列表,如果需要换行,则手动加入换行符
truncate() : 截取文件,截取的字节通过参数指定,默认为当前文件位置
flush()
学习关于 flush 方法先来看一个小实例,首先我清空 写入的文件.txt ,然后我在终端操作,如:
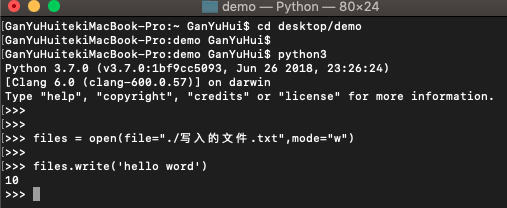
可以看到,我写入了十个字节 ,然后我在 pycharm 里面打开该文件:
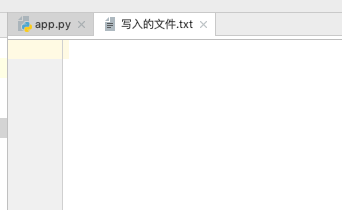
发现这个文件里面什么都没有,并没有写入任何东西,然后我在终端关闭这个文件:
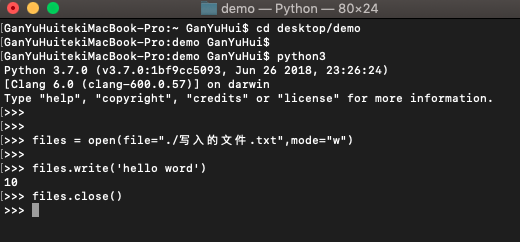
再次打开 pycharm 查看 写入的文件.txt :
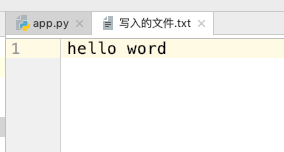
发现其实他已经写入进来了,这个应该不难理解,就好比我们编写一个文件,当我们打开文件后,开始编写,当我们编写完成后,肯定要 command + s 保存,然后关闭,再次打开的时候他其实就已经存在了,如果在你编写该文件的时候没有保存再次在另一个软件里面打开,其实看到的就是空的,那么他编写的内容其实并没有真正存储到硬盘当中,而是在计算机的运行内存当中,只有当你保存了之后才会真正写入到硬盘当中去,至于为什么不写一个就直接保存一个到硬盘当中去那是因为,从运行内存到硬盘内存的写入速度是相当慢的,所以 python 默认不支持这样的操作,但是他支持一个实时更改的内置方法,在业务场景需要的情况下允许这样做,所以 flush() 函数诞生了,如:
files = open(file="./写入的文件.txt",mode="a")
files.write('\nhello')
files.flush()
接下来再看看 写入的文件.txt :
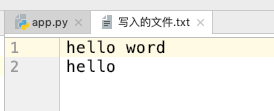
readable()
判断文件是否可读,这个不是很难,据两个例子就明白了:
files = open(file="./写入的文件.txt",mode="r")
print(files.readable())
>> True
files = open(file="./写入的文件.txt",mode="w")
print(files.readable())
>> False
readline()
只读一行,这个很简单,也就是说遇到了换行符就停止了不再往下读取了,如:
#写入的文件.txt
hello word1
hello word2
hello word3
hello word4
#app.py
files = open(file="./写入的文件.txt",mode="r")
print(files.readline())
print(files.readline())
>> hello word1
>
> hello word2
next()
返回文件的下一行,这个其实也不是很难,如:
files = open(file="./写入的文件.txt",mode="r")
#循环三次
for index in range(3):
line = next(files) #next的参数为文件,这样才能读取
print(line) #依次打印变量
# 关闭文件
files.close()
>> hello word1
>> hello word2
>> hello word3
tell()
返回当前文件操作的光标所在位置,他返回的是一个字节的数字,如:
files = open(file="./写入的文件.txt",mode="r")
#每次往下读取一行数据,然后打印依次当前光标行走的位置
files.readline()
print(files.tell())
files.readline()
print(files.tell())
files.readline()
print(files.tell())
files.readline()
print(files.tell())
# 关闭文件
files.close()
>> 12
24
36
47
seek()
设置文件内光标的当前位置,如:每次设置完光标的所在位置之后只读取一行
files = open(file="./写入的文件.txt",mode="r")
#每次只读一行
print(files.readline())
# 将光标设置到第一个
files.seek(0)
#每次只读一行
print(files.readline())
# 关闭文件
files.close()
>> hello word1
hello word1
seekaable()
判断文件是否可以进行 seek() 方法操作,其实这个没什么好演示的,反正就是如果能够进行 seek() 方法操作就会返回 True,否则返回的就是 False ,可能会有朋友问,还有不能操作的文件?当然有,在 Linux 上一切皆文件,一个驱动都是文件,一个运行程序也是文件,当然这一类的文件返回的肯定是 False
writeable()
判断文件是否可以写入,其实这个也没什么好示范的,其实只要把 mode 改成 r 就不可以写入了,其实的和上面这个 seekaable() 方法一样的
readlines()
读取所有行,并返回列表,以每一行的换行符为一个结尾计算,如:
files = open(file="./写入的文件.txt",mode="r")
print(files.readlines())
# 关闭文件
files.close()
>> ['hello word1\n', 'hello word2\n', 'hello word3\n', 'hello word4']
read()
其实这个方法,在一开始的时候已经演示过了很多次,但都是直接使用的,并没有在里面传参数,现在我在里面传递一个参数看看
files = open(file="./写入的文件.txt",mode="r")
print(files.read(1))
# 关闭文件
files.close()
>> h
fileno()
方法返回一个整型的文件描述符(file descriptor FD 整型),可用于底层操作系统的 I/O 操作
files = open(file="./写入的文件.txt",mode="r")
print(files.fileno())
# 关闭文件
files.close()
>> 3
isatty()
如果连接到一个终端设备返回 True,否则返回 False,我这里并没有连接到终端设备,所以一定返回的是 False
files = open(file="./写入的文件.txt",mode="r")
print(files.isatty())
# 关闭文件
files.close()
>> False
writelines()
像文件写入一个序列的字符串列表,如果需要换行,则手动加入换行符:
#以文件的写方式操作
files = open(file="./写入的文件.txt",mode="w")
data = [
'hello\n',
'word'
]
files.writelines(data)
# 关闭文件
files.close()
当我再次打开这个文件后发现只有以下内容:
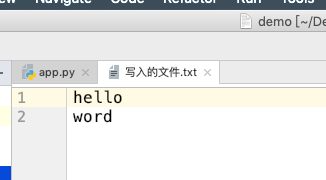
truncate()
截取文件,截取的字节通过参数指定,默认为当前文件位置,如:
files = open(file="./写入的文件.txt",mode="r+")
files.truncate(4)
files.close()
当运行完成后我打开 写入的文件.txt ,里面的内容变成了这样子:
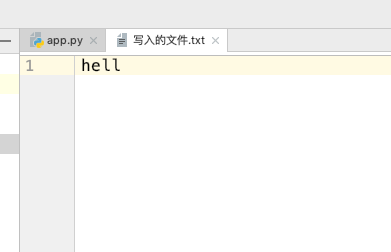
发现只留下来了四个字符,也就是说不管文件内有多少个字符,我可以根据指定的参数,只截取一部分内容长度的字节出来。
这里的文件操作有一个关于字符编码的问题,在中国我们一般用的字符编码,都是 utf-8 和 gbk 的编码,在 gbk 里面一个字占据 2 个字节,在 utf-8 里面一个字占据三个字节,所以进行一些操作的时候千万要记住,不要因为字符编码的问题搞出乱码的问题,这里我来做一个示范:
我把 写入的文件.txt 内容改成:中国万岁,如:
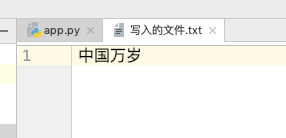
这里的 写入的文件.txt 我用的是 utf-8 的字符集,现在我来用 truncate() 方法截取字符:
files = open(file="./写入的文件.txt",mode="r+")
files.truncate(9)
files.close()
当我运行完成之后,打开 写入的文件.txt ,内容是这样的:
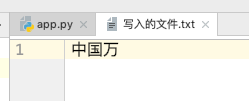
我现在把 9 个字节改成 8 以下,如:
files = open(file="./写入的文件.txt",mode="r+")
files.truncate(8)
files.close()
再次打开 写入的文件.txt 内容是这样的:
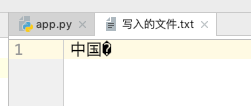
可以看到已经乱码了,所以一定要切记,utf-8 的字符集一个中文占据 3 个字节,gbk 一个中文占据 2 个字节,所以千万不能犯这种低级的错误。
在以上介绍的方法中,操作文件的方法,read() 方法是按一个字符来操作,truncate()、tell() 、seek() 这几种都是用来操作字节的。
言归正传,回到之前那个问题,我现在介绍了这么多方法,其实能用得到的方法基本上全部介绍了个遍,所以现在我来进行文件修改,可能有朋友会问了,上面的方法都不能进行文件修改,你还没介绍文件修改的方法呢,其实说句真心话,python 还真没有这个方法,我能想到的思路就是,通过循环,依次读取文件的每一行,然后创建新的文件加进去,把要修改的通过字符串的 replace() 方法替换了,如:
写入的文件.txt 内容如下:
每天学习一点
让自己更加强大一些
即便满身疲惫
也装出一副轻松的模样
我现在把第二行的 自己 改成一个 我 字
# 修改的文件名称
name1 = '写入的文件'
# 用字符串的方法copy一个新的文件加上编号命名
name2 = '%s(1).txt'%name1
# 需要修改的内容
original = '自己'
# 修改成什么内容
change = '我'
# 需要修改的文件
files = open(file=name1+'.txt',mode='r',encoding='utf-8')
# 新增并写入的文件
files2 = open(file=name2,mode='w',encoding='utf-8')
# 循环需要修改的文件,将每一行的内容以字符串的形式赋值给变量 i
for i in files:
# 逐行判断是否有需要修改的内容
if original in i:
# 判断成立用字符串方法替换内容并且赋值给当前循环次数的变量i
i = i.replace(original,change)
# 每一行结束后 i 都代替了当前这一行的数据,然后将这一行给添加进新的文件
files2.write(i)
# 执行结束后关闭两个文件
files.close()
files2.close()
当程序运行结束后,我可以看到我当前目录下多了一个叫做 写入的文件(1).txt 的文件,我将该文件的内容打开,然后看到的结果如下:
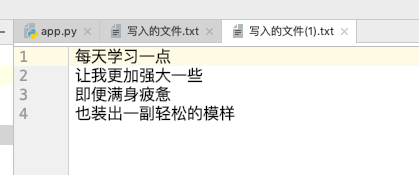
可以看到执行成功了 自己 变成了 我,然而这并没有完成,因为我要做的是修改文件,但是这并不属于修改文件,而是新增了一个文件,所以这个时候我的思路一变,有两个方案出现了:
1、清空原有文件的内容,然后将新增的文件内容读取过来赋值给原有的文件,最后删除新增的文件
2、将新增的文件重命名覆盖原有的文件
这样一来不管这两个怎么着,都实现了修改文件的这个功能,可是上面又没有介绍删除文件的方法,也没有介绍文件重命名的方法,于是我就找资料看书和前辈们的整理出来的资料,毕竟现在学技术已经是站在了巨人的肩膀上了,我们的前辈已经给出了太多的方案,具体如下:
在 python 里面有一个内置的模块,叫做 os ,和之前的深度copy是一样的,都需要引入改模块,在 os 模块里面我找到了两个方法:
rename() : 文件重命名
remove() : 删除文件
因为删除方法太麻烦来,要写两边,不过稍后我会演示如何删除文件,但是就不在这个例子上演示了,我先用重命名的方法来实现功能这个功能例子:
import os
# 修改的文件名称
name1 = '写入的文件'
# 用字符串的方法copy一个新的文件加上编号命名
name2 = '%s(1).txt'%name1
# 需要修改的内容
original = '自己'
# 修改成什么内容
change = '我'
# 需要修改的文件
files = open(file=name1+'.txt',mode='r',encoding='utf-8')
# 新增并写入的文件
files2 = open(file=name2,mode='w',encoding='utf-8')
# 循环需要修改的文件,将每一行的内容以字符串的形式赋值给变量 i
for i in files:
# 逐行判断是否有需要修改的内容
if original in i:
# 判断成立用字符串方法替换内容并且赋值给当前循环次数的变量i
i = i.replace(original,change)
# 每一行结束后 i 都代替了当前这一行的数据,然后将这一行给添加进新的文件
files2.write(i)
# 执行结束后关闭两个文件
files.close()
files2.close()
os.rename(name2,name1+'.txt')
当程序执行完成之后之前的会发现,之前的文件已经因为新加的文件重命名给替换了,然后新的文件取而代之了原有的文件:
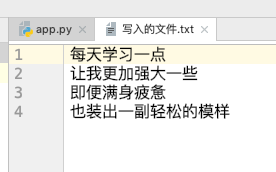
好了,文件重命名方法已经完成了,现在来看看删除方法的使用我现在删除这个文件如:
import os
os.remove('写入的文件.txt')
当我运行完成之后在我的 pycharm 里面已经看不到这个文件了:
关于文件的操作就基本上全部学完了,当然了,如果你觉得真的就这么多的话,你应该去翻阅翻阅相关的书籍了,我只是把常用的方法列出来了而已,每一门程序语言都够学的了,不过当你学完上面这些操作方法,再看看那些偏门的方法其实会觉得已经很容易了。