摘要
在这项研究中,我们提出了一种集束搜索方法,以在源句和目标句中的大多数字符是重叠的这种局部序列转换任务中获得多样化的输出,例如在语法错误校正(GEC)中。在GEC中,最理想的是仅重写必须重写的局部序列,同时保持正确的序列不变。但是,现有的获取各种输出的方法着重于修改句子的所有字符。因此,现有方法可能会迫使整个句子被更改而生成非语法语句,或者通过削弱约束以避免生成非语法语句而生成非多样化的语句。考虑到这些问题,我们提出了一种方法,该方法不重写文本中的所有字符,而仅重写需要进行各种纠正的那些部分。我们的集束搜索方法根据从源句子复制预测的概率来调整集束中的搜索字符。实验结果表明,我们提出的方法可以比现有方法产生更多的校正,而不会降低GEC任务的准确性。
1.介绍
语法错误纠正(GEC)是一项纠正输入文本中语法错误的任务。根据给定的输入,有多种方法可以纠正此类文本。例如,对于同一篇语法错误文本,10个注释者可以产生10个不同的有效纠正结果。如果GEC模型显示了多个候选纠正对象,则它可以帮助用户决定是否使用纠正结果,以便用户可以从候选对象中选择喜欢的正确表达。
但是,当前现有的GEC模型不考虑生成多个纠正候选。通常,在GEC中,用于获得多个校正的方法包括使用普通集束搜索来生成top-n个最佳候选。然而,已经表明,普通集束搜索无法提供足够好的候选对象,并且无法生成几乎相同的序列列表。因此,在没有多样性控制的情况下,通过集束搜索生成的 n n n个最佳候选不会提供有用的附加信息。考虑到这个问题,已经提出了几种集束搜索方法来生成不同的候选对象。这些不同的集束搜索方法通过全局重写句子中的所有字符来鼓励多样性。我们将这些方法称为各种全局集束搜索方法。相反,考虑到GEC中的局部序列转换任务,其中源句子和目标句子中的大多数字符是重叠的,则不建议对输入句子进行过多的纠正,因为不必要的重写会损坏输入句子的语法正确部分。但是,鼓励进行不必要多的纠正又会降低GEC本身的性能。因此,我们假设普通集束搜索和多样化的全局集束搜索方法可能都不适合GEC任务,并且GEC模型必须以多种方式纠正输入句子的语法错误,同时保留句子的正确部分。
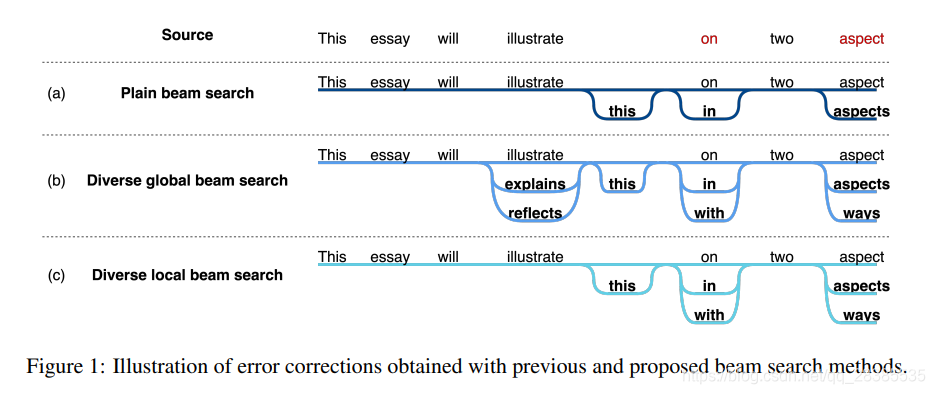
在这项研究中,我们提出了一种多样化局部集束搜索方法,以在集束搜索过程中考虑是否纠正字符,而获得多样化的输出。请注意,我们的方法可用于任何局部序列转换任务。图1显示了现有方法和提出方法的比较。
提出的集束搜索方法考虑了以下因素:
(a)在普通集束搜索中,纠正集中在特定路径上。因此,此方法生成具有相似字符组合和少量单词类型的句子。
(b)多样的全局集束搜索方法探索了许多不同的路径。因此,与普通集束搜索不同,此方法生成具有各种字符组合和大量单词类型的句子。但是,它还会为不需要纠正的字符生成候选校正。
(c)提出的多样化局部集束搜索仅针对需要纠正的字符扩展了不同的路径。因此,我们的多样化局部集束搜索生成的语句比普通集束搜索生成的字符在需要修改的位置具有更多多样化的组合。
应该注意的是,上述所有方法都具有相同的 n n n条路径,但是路径内容不同。实验结果表明,与现有方法相比,我们多样化局部集束搜索可以生成更加多样化和准确的top-n候选,且在GEC任务中评估数据集的性能几乎没有下降。
2.相关工作
最近有一些研究提出使用集束搜索获得不同的输出。Li et al. (2016) 修改了标准集束搜索,以惩罚具有相同父节点的搜索得分。他们的算法仅推荐来自不同父结点的那些假设。Vijayakumar et al. (2018) 提出了一种将集束分成几组并为每个组执行集束搜索的方法。此外,他们添加了一个约束,使在同一时刻中很难选择其他组选择的字符。Kulikov et al. (2019) 提出了一种迭代波束搜索,该搜索在神经对话建模中产生了一组更加多样化的候选响应。但是,这些研究没有区分不需要重写的部分和需要进行更正的部分。
3.多样化局部集束搜索
多样化的局部集束搜索鼓励候选者对输入句子必须纠正的部分进行各种纠正,并阻止候选者对输入句子中已经正确的部分进行纠正。因此,它运行较少部分的计算以生成各种候选对象。为了此目的,在每个时刻 t t t将惩罚分数 s b , t s_{b,t} sb,t分配给每个集束 b b b,指示是否应该进行校正。尽管可以使用不同的方法来计算惩罚分数,但在本研究中,我们使用copy-augmented模型中的复制概率作为惩罚分数 s b , t s_{b,t} sb,t。我们将在4.1节中详细解释copy-augmented模型。使用惩罚分数,我们对集束搜索分数 k k k进行了如下惩罚:
k b , t = ( λ s b , t + β ) l o g p b t (1) k_{b,t}=(\lambda s_{b,t}+\beta)log~p_{b_t}\tag{1} kb,t=(λsb,t+β)log pbt(1)
其中 p p p是GEC模型的输出分布。 β β β和 λ λ λ是超参数,其中 β β β防止惩罚降为零,而 λ λ λ确定惩罚的强度。
4.实验
4.1 模型
我们使用copy-augmented模型作为GEC模型。该模型通过平衡因子 α c o p y α^{copy} αcopy控制复制分布 p c o p y p^{copy} pcopy和生成分布 p g e n p^{gen} pgen之间的平衡。 p c o p y p^{copy} pcopy是要从源语句复制的字符概率分布,而 p g e n p^{gen} pgen是预测输出字符的生成概率分布。最后的输出分布 p b , t p_{b,t} pb,t计算如下:
p b , t = ( 1 − α b , t c o p y ) p b , t g e n + α b , t c o p y p b , t c o p y (2) p_{b,t}=(1-\alpha^{copy}_{b,t})p^{gen}_{b,t}+\alpha^{copy}_{b,t}p^{copy}_{b,t}\tag{2} pb,t=(1−αb,tcopy)pb,tgen+αb,tcopypb,tcopy(2)
从源语句复制或生成字符可以视为在更正与否之间的选择。因此,我们在公式1中将 α b , t c o p y α^{copy}_{b,t} αb,tcopy用作惩罚分数 s b , t s_{b,t} sb,t。对于多样化局部集束搜索,我们设置 β = 1.0 β=1.0 β=1.0和 λ = 4.0 λ=4.0 λ=4.0。