介绍
本文介绍三篇文章的大致内容:
- Lexically Constrained Decoding for Sequence Generation Using Grid Beam Search
提出了grid beam search (GBS) - Fast Lexically Constrained Decoding with Dynamic Beam Allocation for Neural Machine Translation
改进GBS, 在每一步搜索的时候, 对不同类型的beam分布不同的容量 - Speeding Up Neural Machine Translation Decoding by Cube Pruning
在搜索的时候, 加上减枝策略, 减少计算量
Grid Beam Search
beam search的过程可以用下图表示
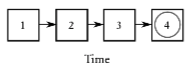
在每个时刻, 有大小为k的beam, 包含k个长度为t的部分序列.
不同时刻beam的更新关系: 对第t-1时刻的beam中的每个序列, 产生n个候选, 将得到的k*n个候选排序, 得到的top-k候选作为t时刻的beam.
最后一个时刻beam中的序列是完成的序列, 可以作为最终的输出序列.
GBS的目标: 在beam search的过程中, 添加约束, 要某个词必须出现在最终输出序列中.
GBS的应用: 机器翻译中, 已知某个术语的翻译, 要求翻译的结果要包含该术语翻译, 可以使用.
GBS的search图示如下:

约束的表示: 为了简单起见, 就表示成某个词, 要求这个词出现在搜索的结果中.
上面beam扩展到grid的形式, 和beam search相比, 多了约束的维度.
grid(t,c) 表示时刻t, 有c个约束对应的beam.
可以看出beam之间的更新关系为: 将grid(t-1, c)中的每个候选扩展一个词, 和grid(t-1, c-1)中的候选扩展一个约束词和并起来, 选取top-n的候选, 作为grid(t, c)中的候选.
最终得到的输出序列为包含了所有约束的beam(最上面一行).
分析:
- 不同约束数目的beam之间不能一起比较, 比如有一个约束的beam 和没有约束的beam相比, 由于约束的存在, 有约束的beam内的候选概率会减小, 如果一起比较, 有约束的beam里的候选的概率一般较小, 一起比较会被没有约束的beam的候选筛掉.
- 不同时刻beam之间不能一起比较, 因为时刻越长的beam概率也会越小
所以, grid的形式也是有必要的.
Dynamic Beam Allocation
第二篇文章改进了GBS.
GBS的主要缺点是在搜索的时候, beam的数目要扩大C倍, C为约束的数目.
DBA出发点是限制beam中总的候选数目为k, 在不同的beam中分配不同的候选数目.
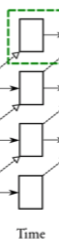
如上图所示, 将t时刻的所有的beam合并起来, 还是按照GBS的方式扩展下一个时刻, 得到可能的所有候选.
在分配的时候, 每个约束对应的beam分配k/C的容量, 如果某个数目的约束中没有候选, 将容量分配给其他beam.
Cube Pruning
Beam Search的一个缺点: 在计算的过程中, beam中每个候选的扩展都需要进行计算, 这在beam较大和每次计算比较复杂的时候代价大.
出发点: 将beam中的不同候选根据状态进行合并, 状态相同的候选公用一个计算. 文中使用的状态相同的定义是: 每个候选序列最后一个时刻的token相同.
具体的操作流程见原文.