https://github.com/wzhe06/SparrowRecSys
文章目录
根据接口进行调试
RecommendationService
在主函数中,RecommendationService是和getrecommendation接口绑定的
context.addServlet(new ServletHolder(new RecommendationService()), "/getrecommendation");
在com.sparrowrecsys.online.service.RecommendationService#doGet打一个断点
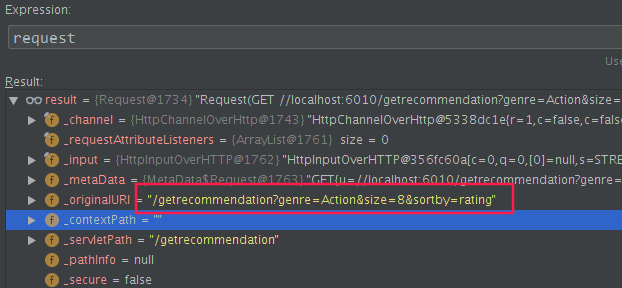
找到webroot/index.html, 最后的js
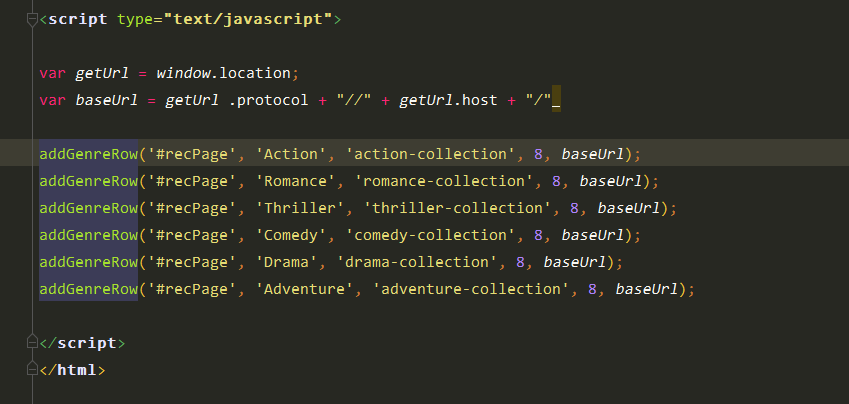
看js代码:webroot/js/recsys.js
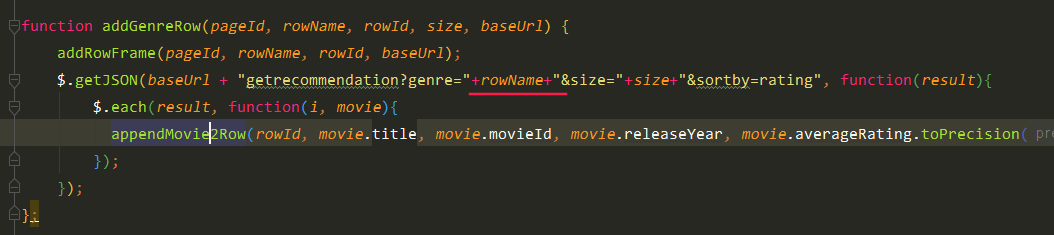
先找genre为Action的电影,size=8
知道了调用源头在哪之后,看Java里面调用了些什么。
com.sparrowrecsys.online.datamanager.DataManager#getMoviesByGenre
从倒排索引中,根据体裁genre找出电影的ID
List<Movie> movies = new ArrayList<>(this.genreReverseIndexMap.get(genre));
MovieService
任意点击一部电影,进入这个断点:
com.sparrowrecsys.online.service.MovieService#doGet
在主函数中,MovieService是和getmovie接口绑定的
context.addServlet(new ServletHolder(new MovieService()), "/getmovie");
前端的请求来源我估计是webroot/js/recsys.js:182的addMovieDetails函数
SimilarMovieService
在主函数中,SimilarMovieService是和getsimilarmovie接口绑定的
context.addServlet(new ServletHolder(new MovieService()), "/getmovie");
调用的是online.recprocess.SimilarMovieProcess类的getRecList的静态方法
具体过程其实分为召回和排序,体现在两个方法中
List<Movie> candidates = candidateGenerator(movie);
List<Movie> rankedList = ranker(movie, candidates, model);
原生的candidateGenerator就是根据体裁做了个单路召回,排序用的是Embedding相似度。emb是Movie类的一个属性,是加载到内存中的!!!!
RecForYouService
上一个的参数是电影ID,这个的参数是用户ID,是要协同过滤?
从业务上,可以理解为以这个ID登录的用户在主页上看到的信息流?
online.recprocess.RecForYouProcess#getRecList
物料的emb是用graph Embedding算的,用户的emb是用他喜好的物料取平均算的
正常操作应该从redis里面拿特征,而不是一把梭全放内存里面
candidates是800个根据评分(rating)得到的电影,排名第一的是4.3分的辛德勒名单
online.recprocess.RecForYouProcess#ranker
本质上就是个双塔召回
虽然看起来这个代码写得就那么回事,但仔细想想,协同过滤 → \rightarrow →矩阵分解 → \rightarrow →emb,好像也有点道理
Spark离线计算的Scala代码
Scala的语法糖实在太甜了,我已经晕了,受不了
Embedding
processItemSequence
单机伪分布式
val conf = new SparkConf()
.setMaster("local")
.setAppName("ctrModel")
.set("spark.submit.deployMode", "client")
处理出item2vec所需的样本序列:
val samples = processItemSequence(spark, rawSampleDataPath)
ratingSamples是评分与时间戳数据

定义排序UDF
val sortUdf: UserDefinedFunction = udf((rows: Seq[Row]) => {
rows.map {
case Row(movieId: String, timestamp: String) => (movieId, timestamp) }
.sortBy {
case (_, timestamp) => timestamp }
.map {
case (movieId, _) => movieId }
})
感觉搞不定了。。需要交互式编程才能理清楚
scala> ratingSamples
res6: org.apache.spark.sql.DataFrame = [userId: string, movieId: string ... 2 more fields]
scala> ratingSamples.where(col("rating") >= 3.5).groupBy("userId")
res7: org.apache.spark.sql.RelationalGroupedDataset = RelationalGroupedDataset: [grouping expressions: [userId: string], value: [userId: string, movieId: string ... 2 more fields], type: GroupBy]
scala> var tmp = ratingSamples.where(col("rating") >= 3.5).groupBy("userId").agg( collect_list(struct("movieId", "timestamp")) as "tmp" ).take(1)
tmp: Array[org.apache.spark.sql.Row] = Array([10096,WrappedArray([50,954365515], [457,954365571], [593,954365552], [858,954364961])])
scala> tmp
res12: Array[org.apache.spark.sql.Row] = Array([10096,WrappedArray([50,954365515], [457,954365571], [593,954365552], [858,954364961])])
scala> tmp(0)
res13: org.apache.spark.sql.Row = [10096,WrappedArray([50,954365515], [457,954365571], [593,954365552], [858,954364961])]
scala> tmp(0)(0)
res14: Any = 10096
scala> tmp(0)(1)
res15: Any = WrappedArray([50,954365515], [457,954365571], [593,954365552], [858,954364961])
scala> userSeq.select("userId", "movieIdStr").show(10, truncate = false)
+------+--------------------------------------------------------------------------------------------------------------------------------------------+
|userId|movieIdStr |
+------+--------------------------------------------------------------------------------------------------------------------------------------------+
|10096 |858 50 593 457 |
|10351 |1 25 32 6 608 52 58 26 30 103 582 588 |
本质上就是获取用户看过的所有高评分的电影(用户给出了高评分), 然后按时间戳排序
最后返回RDD[Seq[String]]
userSeq.select("movieIdStr").rdd.map(r => r.getAs[String]("movieIdStr").split(" ").toSeq)
scala> userSeq.select("movieIdStr").rdd.map(r => r.getAs[String]("movieIdStr").split(" ").toSeq).take(2)
res5: Array[Seq[String]] = Array(WrappedArray(858, 50, 593, 457), WrappedArray(1, 25, 32, 6, 608, 52, 58, 26, 30, 103, 582, 588))
item2vec
samples : RDD[Seq[String]]
val word2vec = new Word2Vec()
.setVectorSize(embLength)
.setWindowSize(5)
.setNumIterations(10)
val model = word2vec.fit(samples)
deepwalk
本质上是采样方式不同
generateTransitionMatrix
对于用户log的物料浏览记录,按时序pairs,建立边。
val pairSamples = samples.flatMap[(String, String)]( sample => {
var pairSeq = Seq[(String,String)]()
var previousItem:String = null
sample.foreach((element:String) => {
if(previousItem != null){
pairSeq = pairSeq :+ (previousItem, element)
}
previousItem = element
})
pairSeq
})
计数
注意pairSamples是rdd,countByValue是action操作,pairCountMap是scala.collection.Map数据类型。
val pairCountMap = pairSamples.countByValue()
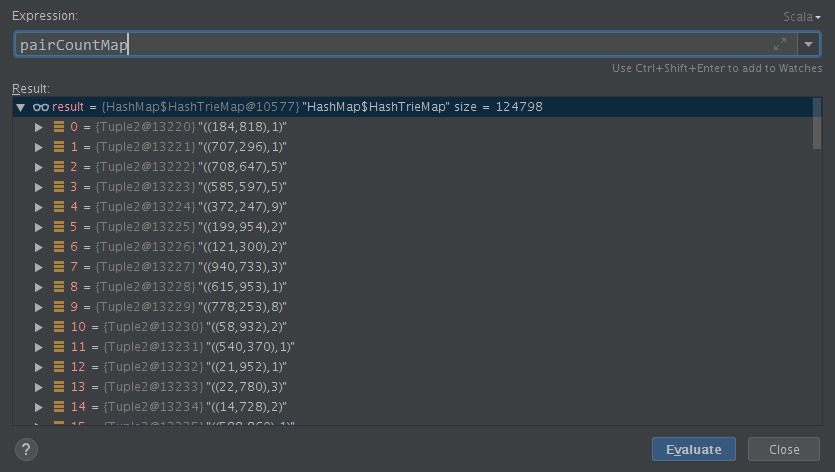
其实就是一个简单的邻接表数据结构:
val transitionCountMatrix = mutable.Map[String, mutable.Map[String, Long]]()
刚看到这行代码我还在想为什么不用边表,仔细一想正解就是邻接表,因为边表没法求某个结点的邻接结点
注意边是单向的。比如用户的浏览记录是ABC, 那么建的图就是 A → B → C A \rightarrow B \rightarrow C A→B→C
边表的建立,本质是对hashMap的foreach操作:
pairCountMap.foreach( pair => {
val pairItems = pair._1
val count = pair._2
if(!transitionCountMatrix.contains(pairItems._1)){
transitionCountMatrix(pairItems._1) = mutable.Map[String, Long]()
}
transitionCountMatrix(pairItems._1)(pairItems._2) = count
itemCountMap(pairItems._1) = itemCountMap.getOrElse[Long](pairItems._1, 0) + count
pairTotalCount = pairTotalCount + count
})
这波循环会形成两个关键的数据结构用于后续的计算中:
transitionCountMatrix计数转移矩阵itemCountMap每个物料的计数pairTotalCount边的计数
最后会建议物料与物料的概率转移矩阵+物料的单变量多项分布
generateTransitionMatrix方法的返回值也是这两个东西:
(mutable.Map[String, mutable.Map[String, Double]], mutable.Map[String, Double])
打印size=956
oneRandomWalk
- 随机选一个初始顶点
- 随机转移,知道序列长度满足条件
代码我看着挺疑惑的,需要与其他的实现对比确认。
最后转成RDD,丢到trainItem2vec的锅里炖了。
generateUserEmb
虽然我知道只是一个超简单的取平均,但这么骚的代码成功征服了我,
看不懂。
FeatureEngineering
oneHotEncoderExample
+-------+--------------------+--------------------+
|movieId| title| genres|
+-------+--------------------+--------------------+
| 1| Toy Story (1995)|Adventure|Animati...|
| 2| Jumanji (1995)|Adventure|Childre...|
| 3|Grumpier Old Men ...| Comedy|Romance|
将movieId从string转为integer
val samplesWithIdNumber = samples.withColumn("movieIdNumber", col("movieId").cast(sql.types.IntegerType))
如果.setDropLast(true),就是dummy encoding
val oneHotEncoder = new OneHotEncoderEstimator()
.setInputCols(Array("movieIdNumber"))
.setOutputCols(Array("movieIdVector"))
.setDropLast(false)
这波操作问题不大。
multiHotEncoderExample
val samplesWithGenre = samples.select(col("movieId"), col("title"),explode(split(col("genres"), "\\|").cast("array<string>")).as("genre"))

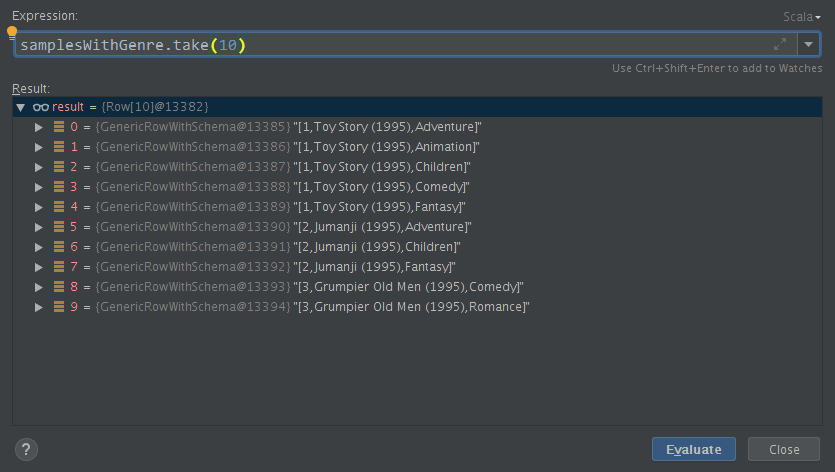
对genres进行多热编码
对分割、explode出来的电影体裁进行有序编码
val genreIndexer = new StringIndexer().setInputCol("genre").setOutputCol("genreIndex")
val stringIndexerModel : StringIndexerModel = genreIndexer.fit(samplesWithGenre)
val genreIndexSamples = stringIndexerModel.transform(samplesWithGenre)
.withColumn("genreIndexInt", col("genreIndex").cast(sql.types.IntegerType))
indexSize值为19,表示某电影能拥有的最大体裁数
val indexSize = genreIndexSamples.agg(max(col("genreIndexInt"))).head().getAs[Int](0) + 1
mapreduce过程太长,拆开看:
portion 1
genreIndexSamples
.groupBy(col("movieId")).agg(collect_list("genreIndexInt").as("genreIndexes"))
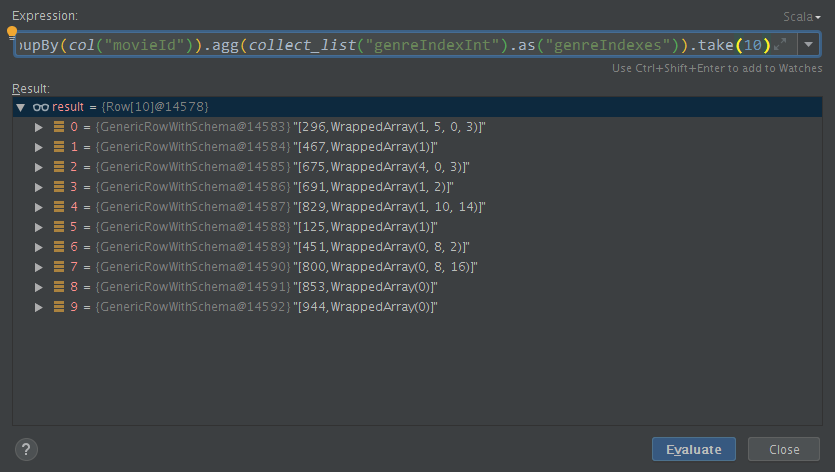
portion 2
indexSize =19, 创建一个常量列
val processedSamples = genreIndexSamples
.groupBy(col("movieId")).agg(collect_list("genreIndexInt").as("genreIndexes"))
.withColumn("indexSize", typedLit(indexSize))
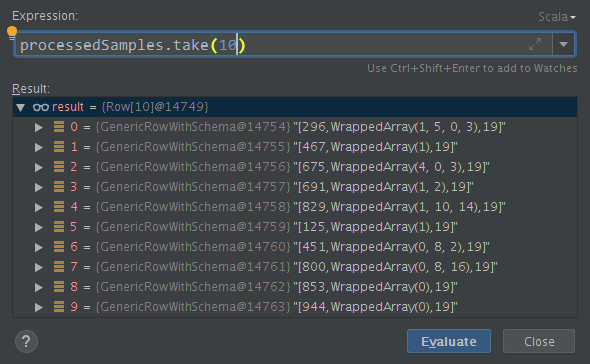
最后用一个叫的UDF根据形成多热编码
- UDF
val array2vec: UserDefinedFunction = udf {
(a: Seq[Int], length: Int) => Vectors.sparse(
length, a.sortWith(_ < _).toArray, Array.fill[Double](a.length)(1.0)
)
}
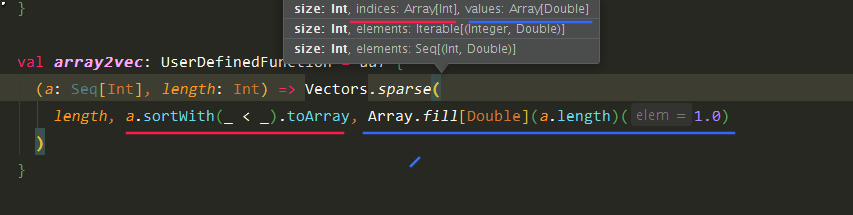
- DataFrame transform
val finalSample = processedSamples.withColumn("vector", array2vec(col("genreIndexes"), col("indexSize")))
ratingFeatures
val movieFeatures = samples.groupBy(col("movieId"))
.agg(count(lit(1)).as("ratingCount"), //注意,lit(1)
avg(col("rating")).as("avgRating"),
variance(col("rating")).as("ratingVar"))
.withColumn("avgRatingVec", double2vec(col("avgRating")))
计数、均值、方差
用一个UDF造一个向量出来,如 x → [ x ] x\rightarrow [x] x→[x]
为什么标量转向量?为了喂给MinMaxScaler
val double2vec: UserDefinedFunction = udf {
(value: Double) => Vectors.dense(value)
}
特征工程器1:分箱
//bucketing
val ratingCountDiscretizer = new QuantileDiscretizer()
.setInputCol("ratingCount")
.setOutputCol("ratingCountBucket")
.setNumBuckets(100)
特征工程器2:归一化
//Normalization
val ratingScaler = new MinMaxScaler()
.setInputCol("avgRatingVec")
.setOutputCol("scaleAvgRating")
管道
val pipelineStage: Array[PipelineStage] = Array(ratingCountDiscretizer, ratingScaler)
val featurePipeline = new Pipeline().setStages(pipelineStage)