前言
在复习早期下载视频知识点时,发现有些关键地方没有理清楚。特此梳理
爬虫实践经验小结
要是不精通动态网页爬虫,那爬虫可用武之地就不大了。
关于爬虫的小故事(可略过)
假设有这样一个桌子和椅子,它们有一套默认的规则,人类坐进椅子,桌子便按照规则提供服务
正常情况是,有一个人类,他坐在了椅子上,说,我想要一支笔,于是桌子表面从下面传上来一支笔。但这个人类先要100支笔,桌子做不到。于是人类把桌子抽屉打开,翻了看到了一百只笔所在的位置,并告诉了它的机器人。
静态网页:人类命令它的机器人仆从按照之前告诉它的地址把笔一支支取出来,人类离开椅子,机器人坐进椅子然后完成任务。
动态网页:人类依然是命令机器人按照告诉它的地址把笔取出来,人类离开椅子,机器人坐进椅子。
此时,为了防止机器人仆从自己从抽屉里拿笔,这个桌子不允许非人类看到抽屉的内部除非得到椅子的认可,
人类为了让机器人帮自己拿笔,告诉它自己的屁股形状,让它假装是自己,于是机器人坐在椅子上,能拉开抽屉看到内部了。
但是机器人找不到笔了
**selenium:**原来,机器人是不需要拉抽屉直接把手探进去拿笔的,而人类是需要拉抽屉,笔的位置才能出现的。于是机器人也模仿人类拉抽屉,看到了笔的位置,完成任务
接口:机器人不想通过模仿人类,它看到了抽屉里原本应该放笔的位置上现在有根绳子,顺着这根绳子他发现了一个保险箱。保险箱里有无数个小精怪,而且他们有它所需要的笔。(小精怪们把无数数据拧成一股绳传到抽屉里)保险箱上有很多个转钮,把它们转到指定的位置相应的笔就会出来。机器人注意到每支笔对应的转钮除了一两个其它都是相同的。
动态网页爬虫的解决方案
如今大部分网页都是动态网页,像经典案例豆瓣250排行榜那样的案例那是打着灯笼都找不着了
解决方案就两个
| 方式 | 优点 | 缺点 | 实践 |
|---|---|---|---|
| 分析接口 | 直接可以请求到数据,不需要做一些解析工作。代码量少,性能高 | 分析接口比较复杂,特别是一些通过js混淆的接口。要有一定的js功底。容易被发现是爬虫 | 有道接口,b站视频接口,天气app接口 |
| selenium | 直接模拟浏览器的行为。浏览器能请求到的,使用selenium也能请求到。爬虫更稳定 | 代码量多,性能低 | scrapy+selenium |
通过接口获取数据
第一个例子-----有道词典
第二个例子------b站
第三个例子------百度图片(本文只涉及动态的图片网页)
有道和b站涉及一个重要区别----post请求和get请求的区别
有道的post,浏览器先发送header,然后再发送data,data里面有加密机制,这个机制需要在js文件里面破解,这个js文件是网站向其服务器发送请求时、提交数据包时,通过抓包得来的,是经过美化的需要还原。分析js文件,会找到有关语法指明加密参数的数据来源,可以将这个加密机制复制到代码中,替代js文件的加密
b站的接口----playurl文件在network里找,结果有的视频里有,有的没有
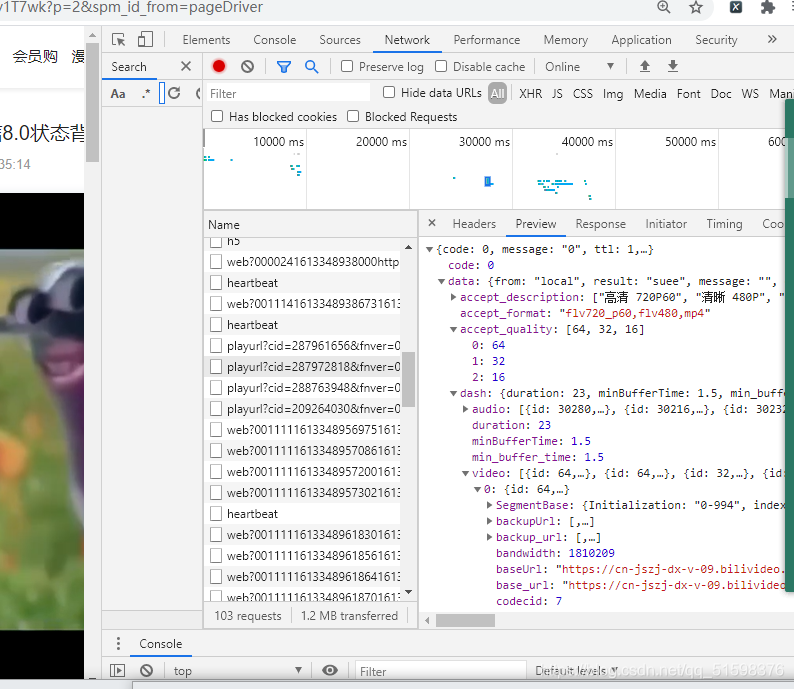
网上搜到接口是这样的
'https://api.bilibili.com/x/player/playurl?' + 'bvid=' + bvid +'&cid=' + str(cid) + '&qn=64&type=&otype=json'
b站不同类型的视频,在network中获取的数据也是有差异的,
抓包技术其实很重要,扩大自己获取数据的能力
有道词典难点它的参数有加密,是post
b站的难点是它不能直接一次获取视频,需要分片下载,似乎没有url的都只能这样下载,由于不是post方式所以不需要参数
第三个例子,见百度图片的获取
首先来到要爬取百度图片的网页,右击检查,点击network,观察有没有包含图片url的接口即数据包
我没有找到,,,,,这就是我经常遇见的情况-------看别人的例子里都通过这种方法找到了对应的js数据包,我自己却找不到。。。。。。
虽然如此,找接口即找包含需求内容的文件是相当重要的(后来我找到了)
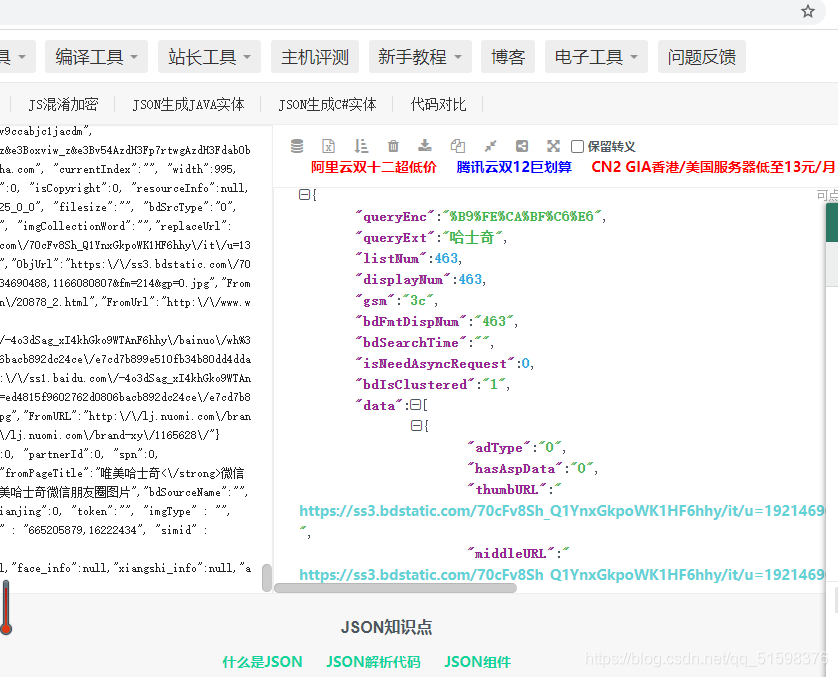
百度图片的接口是
http://image.baidu.com/search/acjson?
加上参数
param = 'tn=resultjson_com&ipn=rj&ct=201326592&is=&fp=result&queryWord={}&cl=2&lm=-1&ie=utf-8&oe=utf-8&adpicid=&st=-1&z=&ic=&hd=1&latest=0©right=0&word={}&s=&se=&tab=&width=&height=&face=0&istype=2&qc=&nc=1&fr=&expermode=&force=&cg=star&pn={}&rn=30&gsm=78&1557125391211='.format(
访问这个接口就能获取图片url了

放到js解析网站上好看多了
然后就是下载保存基本操作
另外经常会出现FileNotFoundError: [Errno 2] No such file or directory: ‘D:/base/0.jpg’
可以规范一点操作
cwd = os.getcwd()
file_name = os.path.join(cwd, keyword)
if not os.path.exists(keyword):
os.mkdir(file_name)
for index, url in enumerate(image_url, start=1):
with open(file_name + '\\{}.jpg'.format(index), 'wb') as f:
f.write(content)
if index != 0 and index % 30 == 0:
print('{}第{}页下载完成'.format(keyword, index / 30))
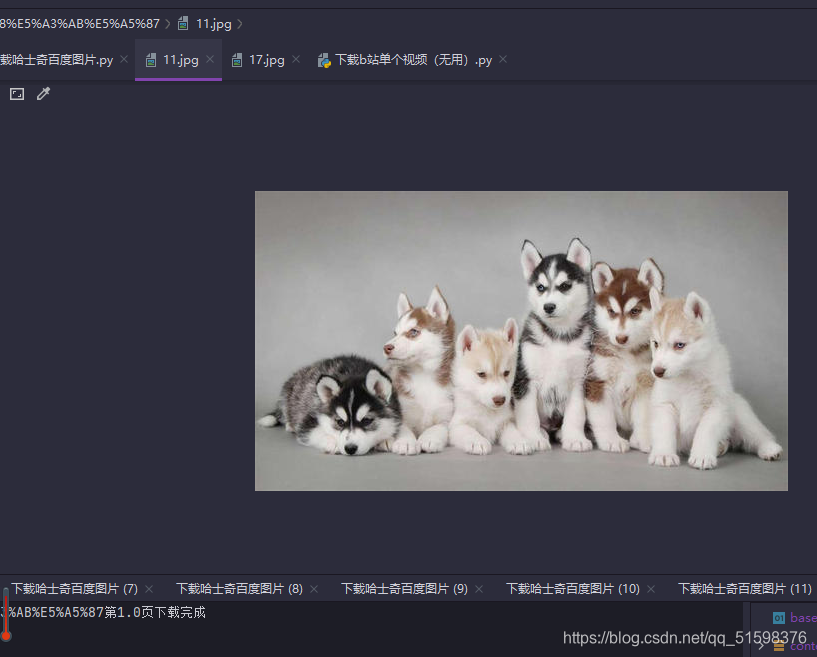
所以以接口下载图片很顺畅
通过selenium获取数据
第一个例子--------腾讯动漫全站漫画
第二个例子--------百度图片(动态版)
第三个例子--------简书点击更多获取文章
腾讯动漫
百度图片
来到网页,观察
滑动鼠标,图片陆续出现但页面没有刷新,所以是动态网页
尝试用xpath普通方法无果后
用selenium
部分代码如下
subjects = driver.find_elements_by_xpath("//div[@class='imgbox']/a/img")
for subject in subjects:
a = subject.get_attribute("data-imgurl")
print(a)
简书
来到这个网页,观察网页源代码,右键检查,用xpath helper试一试
发现这个网页有反爬机制,类名是动态的,上代码xpath即使用相对位置搜索也不一定能获取想要的内容,要确定正确的xpath语法会很麻烦
现在要爬取,专题收入对应的链接或文字
用代码试试
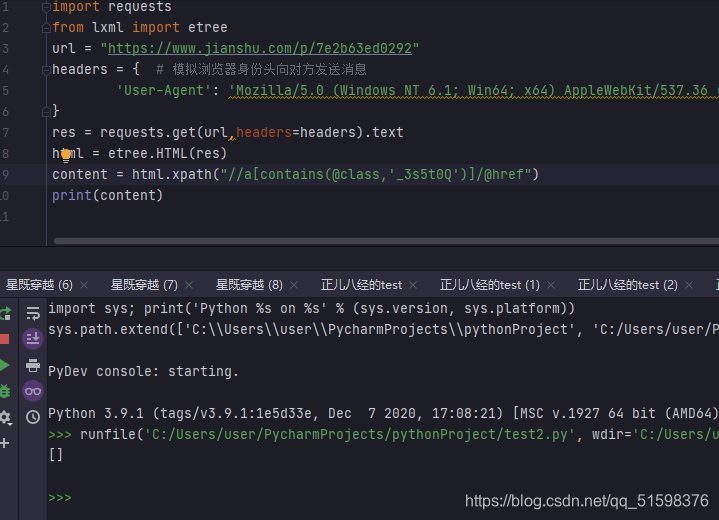
果然返回为空,无法获取指定的内容
并且原网页需要用户点击更多,所以为了解决这两个特定的问题,使用selenium
看代码
from selenium import webdriver
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
driver = webdriver.Chrome(executable_path=r"D:\ProgramApp\chromedriver\chromedriver.exe")
url = "https://www.jianshu.com/p/7e2b63ed0292"
driver.get(url)
WebDriverWait(driver,5).until(
EC.element_to_be_clickable((By.XPATH,"//section[position()=2]/div/div"))
)
while True:
try:
next_btn = driver.find_element_by_xpath("//section[position()=2]/div/div")
driver.execute_script("arguments[0].click();",next_btn)
except Exception as e:
break
subjects = driver.find_elements_by_xpath("//section[position()=2]/div[position()=1]/a")
for subject in subjects:
print(subject.text)
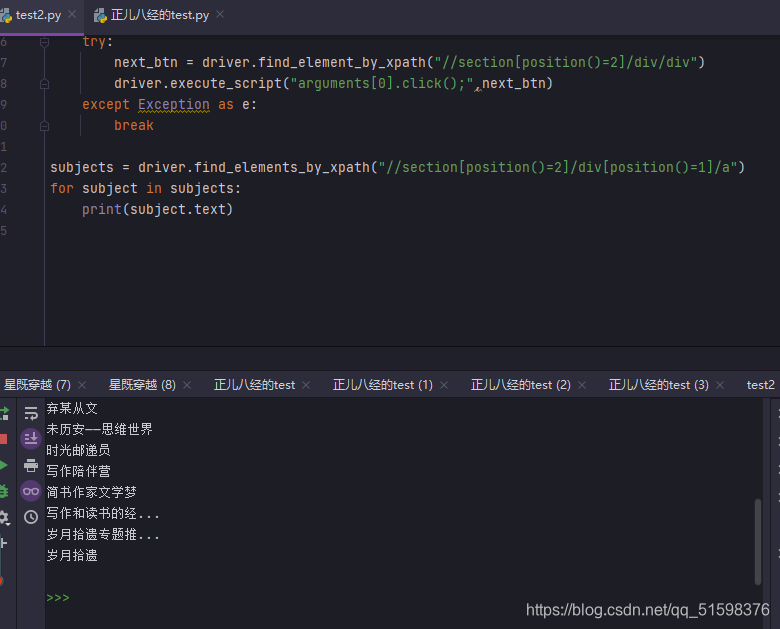
结果达到目的
小结:
现状一:用普通方法爬取得到某些东西,爬取不到某些东西
爬取得到的东西在源代码里有,爬取不到的在源代码里没有
推测一:源代码里隐藏的都爬取不到,源码里有的普通方法都能爬取
注:源代码不包括一个很长很长的复杂字符串
现状二:简书网页里,专题名称源代码里没有,但抓包能获取
推测二:源代码里没有的都能抓包获取
意外收获:抓包能获得所有评论,头像,ID等信息
现状三:简书网页,用xpath普通方法爬取不到专题名,用接口可以,用selenium也可以
推测三:源代码隐藏的只能用接口或者selenium方式爬取
实践结论:用selenium即能轻松定位,动态属性是针对普通方法的反爬;
selenium是先获取元素再获取属性值