前言
大家好!本篇博客我们来学习决策树(ID3/C4.5/CART)及相关的集成模型(RandomForest/GBDT/XGBoost/AdaBoost)。
注意:本人并未读过Sklearn库的源代码,本文所给出的实现都是建立在本人的理解之上的,因此实现可能有很多不规范的地方,但我认为还是有助于理解决策树及相关的集成模型。如果各位读者发现有不正确的地方,欢迎联系我,我会尽快纠正。
本篇博客对应的代码已开源在GitHub上:https://github.com/bufuchangfeng/DecisionTree
本篇博客的亮点在于:
- 不仅有原理讲解,更有代码实现和讲解。
将本文实现的代码与Sklearn库相比较,相同模型准确率的差值不超过5%。 - 使用的数据并非demo数据集,而是真实的MNIST数据集。
这将涉及到决策树如何处理特征值为连续值的情况。
我们可以通过下面这张图对决策树有一个基本的认识。
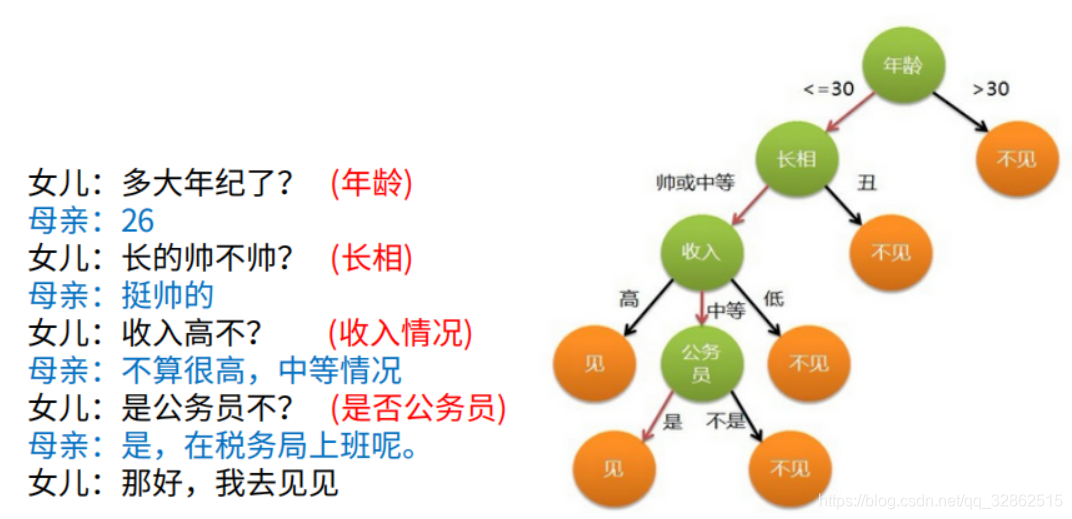
图源:https://www.cnblogs.com/mantch/p/11145186.html
一棵决策树的本质是就是一系列if else。训练的过程就是学习这些if else的过程。一棵决策树的预测过程就是从根节点出发,走到某一叶子节点的过程。每个非叶子的节点都会存储一个feature_index和一个对应的feature_value。对于某个特定的测试样本sample和某个特定的节点node,预测过程可以使用下面的伪代码表示。
actual_feature_value = sample.features[node.feature_index]
if actual_feature_value <= node.feature_value:
node = node->left
else:
node = node->right
决策树有3中基本的模型:ID3、C4.5和CART。
我认为三种基本的模型的本质不同是在选择分裂节点时分裂指标的不同。
因此在实现三种基本决策树模型的时候,可以先定义一个基类,然后继承该基类实现三个子类。不过本文并没有采用这种方法。
此外,ID3和C4.5只能用于分类,CART不仅可以用于分类,也可以用于回归,从它的全称便可以得知——Classification And Regression Tree。
ID3
在某个非叶子的节点处,ID3使用信息增益(information gain)来选择最优的特征(feature_index)及对应的切分点(feature_value)。
当特征为离散值时,给定数据集和某个特征,计算信息增益的算法如下。
图源:《统计学习方法》

不要被公式吓到,通俗点说,其核心思想就是“数数”。
当特征为连续值时该如何处理呢?
根据西瓜书,我们可以采用连续属性离散化技术。
举个例子,假如现在训练集有10个样本,每个样本有5个特征(特征1、特征2、特征3、特征4、特征5),假设这5个特征都是连续的。
假设我们是在根节点,以特征1为例,易知其共有10个值(因为一共有10个样本),将这10个值从小到大排序(从大到小排序也可),然后计算每两个相邻值的均值,10个原始值就会得到9个均值。对于一个特定的均值,都可以将这10个样本划分为两个集合,其中一个集合是特征1取值不大于该均值的样本,另一个集合是特征1取值大于该均值的样本(容易想到,最后学习到的决策树必然是一棵二叉树)。然后就可以计算信息增益了。 这样就把特征1处理完了,再对特征2-5进行相同的操作。最后会得到一个最优的切分点,即得到对应的feature_index和feature_value。
为了验证我们想法的正确性,我们用python来实现ID3算法,并在真实的MNIST数据集上测试,就如本文开始所说的那样。
首先是导入相应的包。
import numpy as np
import matplotlib.pyplot as plt
from scipy.io import loadmat
from scipy.sparse import coo_matrix
from sklearn.utils import shuffle
from sklearn.model_selection import train_test_split
import copy
import pandas as pd
from tqdm import tqdm
from typing import Counter
import math
from sklearn.decomposition import PCA
from sklearn.metrics import f1_score, recall_score, precision_score
import sys
import time
接下来是读取数据,这属于预处理环节,与算法的实现关系不大,不感兴趣的读者可以直接跳过。
def load_data():
data = loadmat("data/mnist_all.mat")
# print(data.keys())
train_data = pd.DataFrame()
test_data = pd.DataFrame()
for i in range(10):
temp_df = pd.DataFrame(data["train" + str(i)])
temp_df['label'] = i
train_data = train_data.append(temp_df)
temp_df = pd.DataFrame(data["test" + str(i)])
temp_df['label'] = i
test_data = test_data.append(temp_df)
train_data = shuffle(train_data)
test_data = shuffle(test_data)
train_labels = np.array(train_data['label'])
test_labels = np.array(test_data['label'])
train_data = train_data.drop('label', axis=1)
test_data = test_data.drop('label', axis=1)
train_data = np.array(train_data) / 255
test_data = np.array(test_data) / 255
pca = PCA(0.95)
pca.fit(train_data)
train_data = pca.transform(train_data)
test_data = pca.transform(test_data)
return train_data, test_data, train_labels, test_labels
X_train, X_test, y_train, y_test = load_data()
X_train, X_valid, y_train, y_valid = train_test_split(
X_train, y_train, test_size=0.2, random_state=0)
# 注意,经过PCA降维后,认为所有的特征都是连续值
X = np.concatenate((X_train, X_valid), axis=0)
y = np.concatenate((y_train, y_valid), axis=0)
查看一下使用PCA降维后数据的shape。
print(X.shape, y.shape)
# (60000, 154) (60000,)
由于我们需要与Sklearn对比效果,因此先测试Sklearn的效果。
注意,这里只选择了测试集中的1k张图片进行测试。
其中criterion='entropy’对应于ID3算法。
from sklearn.tree import DecisionTreeClassifier
tree = DecisionTreeClassifier(criterion='entropy')
tree.fit(X[:1000], y[:1000])
查看Sklearn库在测试集上的效果。这里使用了全部测试集(1w张)。
predict_sklearn = tree.predict(X_test)
print('sklearn test acc: {}'.format((sum(predict_sklearn == np.array(y_test)))/len(X_test)))
# sklearn test acc: 0.6331
可以看到Sklearn在测试集上的准确率是0.6331。
接下来,我们要自己实现ID3算法。这里我先给出完整代码,然后会逐行讲解。
# 在每个节点上,用于分割的特征、阈值、不等关系用一个三元组来表示,
# 即(特征,阈值,不等关系),例子(第1维特征,0.338,'<='),元组可以作为dict的key
# 当划分属性是连续值时,对应于 <= 和 > 两种情况,因此最后得到的决策树必然是一棵二叉树
class ID3_without_pruning:
def __init__(self, epsilon):
self.epsilon = epsilon
def fit(self, X, y):
self.tree = self.build_tree(X, y)
def build_tree(self, X, y):
# 如果所有的X都属于一个y_i
temp_y = list(set(y))
if len(temp_y) == 1:
return temp_y[0]
# 如果没有可以选择的划分属性?
# 不会存在这种情况,因为连续属性可以重复用作划分属性
best_feature_index, threshold, best_H_D_A = self.choose_best_feature_to_split(X, y)
# 计算H(D)
C = [0]*10
for i in range(len(X)):
C[y[i]] += 1
H_D = 0
for i in range(10):
if C[i] != 0:
H_D += (C[i]/len(X))*np.log2(C[i]/len(X))
info_gain = -H_D - best_H_D_A
if info_gain < self.epsilon:
return Counter(y).most_common(1)[0][0]
tree = {
}
x1, y1, x2, y2 = self.split_data(X, y, best_feature_index, threshold)
tree[(best_feature_index, threshold, '<=')] = self.build_tree(x1, y1)
tree[(best_feature_index, threshold, '>')] = self.build_tree(x2, y2)
return tree
def split_data(self, X, y, best_feature_index, threshold):
x1, x2, y1, y2 = [], [], [], []
for i in range(len(X)):
if X[i][best_feature_index] <= threshold:
x1.append(X[i])
y1.append(y[i])
else:
x2.append(X[i])
y2.append(y[i])
return np.array(x1), np.array(y1), np.array(x2), np.array(y2)
def predict(self, x):
tree = self.tree
while type(tree).__name__ == 'dict':
for key in tree.keys():
if key[2] == '<=':
key1 = key
elif key[2] == '>':
key2 = key
feature_index = key1[0]
threshold = key1[1]
if x[feature_index] <= threshold:
tree = tree[key1]
elif x[feature_index] > threshold:
tree = tree[key2]
if type(tree).__name__ == 'int64':
return tree
else:
pass
def calculate_H_D_A(self, feature_index, X, y):
values = []
for i in range(len(X)):
values.append(X[i][feature_index])
values = list(set(values))
values.sort()
best_H_D_A = sys.maxsize
best_threshold = None
for i in range(len(values) - 1):
threshold = (values[i] + values[i + 1])/2
# D1和D2的作用是分别计算 <=threshold 和 >threshold 的X的数量
D1, D2 = 0, 0
# d1和d2的作用是分别计算D1和D2中各类标签(0-9)的数量
d1, d2 = [0]*10, [0]*10
for i in range(len(X)):
if X[i][feature_index] <= threshold:
D1 += 1
d1[y[i]] += 1
elif X[i][feature_index] > threshold:
D2 += 1
d2[y[i]] += 1
# 下面计算H(D|A)
part1 = 0 # <= threshold
part2 = 0 # > threshold
for i in range(10):
if d1[i] != 0:
part1 += (d1[i]/D1)*np.log2(d1[i]/D1)
if d2[i] != 0:
part2 += (d2[i]/D2)*np.log2(d2[i]/D2)
part1 = part1*D1/len(X)
part2 = part2*D2/len(X)
H_D_A = -(part1 + part2)
if H_D_A < best_H_D_A:
best_threshold = threshold
best_H_D_A = H_D_A
if best_threshold is None:
print('error in function calculate_H_D_A')
return best_H_D_A, best_threshold
# 根据西瓜书:
# 需注意的是,与离散属性不同,若当前结点划分属性为连续属性,该属性还可作为其后代结点的划分属性
# 因此不需要记录哪些属性(特征)已经使用过了
def choose_best_feature_to_split(self, X, y):
feature_num = X.shape[1]
best_feature_index = -1
best_H_D_A = sys.maxsize
best_feature_threshold = None
# 根据信息增益的定义,对于所有特征,经验熵H(D)是固定的,取信息增益最大,只要经验条件熵H(D/A)最小即可
for feature_index in range(feature_num):
H_D_A, threshold = self.calculate_H_D_A(feature_index, X, y)
if H_D_A < best_H_D_A:
best_H_D_A = H_D_A
best_feature_index = feature_index
best_feature_threshold = threshold
# 不会发生
if best_feature_index == -1:
pass
return best_feature_index, best_feature_threshold, best_H_D_A
第6-7行是类的初始化。其中epsilon是一个超参数,其作用是当最优的fearture_index和feature_value对应的信息增益小于epsilon时,就停止当前节点的分裂。
第9-10行是fit()函数,其中调用了build_tree()函数。build_tree就是建树的过程,这个过程是递归的。
第13-44行是build_tree函数。第15-17行是为了处理当前节点对应的数据都属于同一个类别的情况(虽然这种情况可能比较少),在这种情况下就不需要再分裂当前节点了,把当前节点作为一个叶子节点,其标签就是该节点中所有数据对应的标签。第22行是选择最优的feature_index和feature_value的过程,这一行调用了choose_best_feature_to_split函数,我们会在下面介绍这个函数。第24-32行是计算经验熵H(D)的过程,就是统计一下当前节点对应的数据中各个类别数据的数量,如前面所说,这是数数的过程。第34-37行是为了防止最优的信息增益值仍然小于epsilon,如果发生这种情况,也不对当前节点进行分裂,把当前节点作为叶子节点,其标签是当前节点数据集标签的众数。第39-40行是根据最优的feature_index和feature_value将当前节点的数据集划分为两个集合的过程,其中一个集合是对应特征小于等于feature_value的样本,另一个集合是对应特征大于feature_value样本集合的样本。第41-42行分别是递归的构建左子树和右子树。第44行是返回建好的树。
第47-59行是划分数据集的过程。在某个节点处,根据最优的feature_index和feature_value,将该节点上的数据分为左子树的数据和右子树的数据。这里的代码很容易理解,就不逐行解释了。
第62-86行是预测一个样本的过程。这个过程就是样本从根节点出发走到叶节点的过程。在建树时,每个节点上,用于分割的特征、阈值、不等关系用一个三元组来表示,即(特征,阈值,不等关系),例子,某个节点的左子树可能是(第1维特征,0.338,’<=’),该节点的右子树则是(第1维特征,0.338,’>’)。元组可以作为dict的key。
第89-138行是计算特征A对数据集D的经验条件熵H(D|A)的过程。该函数传入的参数是feature_index和data(X,y)。第91-96行是得到所有样本feature_index对应的特征值,放入一个列表中并排序。这对应于上面提到的连续特征离散化。第101-138行就是对相邻的特征值计算均值,并把均值作为切分点计算H(D|A),最后返回当前feature_index下最优的切分点和最优的H(D|A)。
第144-163行是对所有的feature_index调用calculate_H_D_A()函数,最后得到最优的feature_index、feature_value及对应的H(D|A)。
这里一个需要注意的地方是:根据信息增益的定义,对于所有特征,经验熵H(D)是固定的,取信息增益最大,只要经验条件熵H(D|A)最小即可。既然如此,为什么在第163行还要返回best_H_D_A呢?原因也很简单,因为build_tree函数中下面的剪枝代码需要计算infomation gain,而information gain又依赖于H(D|A)。
info_gain = -H_D - best_H_D_A
if info_gain < self.epsilon:
return Counter(y).most_common(1)[0][0]
上面就是我们自己实现的ID3决策树,没有用到剪枝。
下面是训练代码。
我实现的决策树的一个明显缺点是:速度慢!
tree = ID3_without_pruning(epsilon=0.1)
print('start training tree...')
start = time.time()
tree.fit(X[:1000], y[:1000])
end = time.time()
print('finish training... time cost: {}s'.format(end-start))
# start training tree...
# finish training... time cost: 427.9175760746002s
下面就是预测代码了。
result_list = []
for i in range(len(X_test)):
result_list.append(tree.predict(X_test[i]))
print('custom ID3 without pruning test acc: {}'.format((sum(result_list == np.array(y_test)))/len(X_test)))
# custom ID3 without pruning test acc: 0.6468
可以看到,我们的ID3效果甚至还要更好一点。但是我认为效果比较接近就可以了,因为一个算法中不可控的细节太多了。相同算法的两个实现,稍微有一点不一致的地方,都会导致结果的不同。
C4.5
C4.5与ID3不同的一点就是分裂指标从information gain变成了gain ratio。
整体思想没有太大变化。直接上代码。数据预处理的代码都是相同的,就不写了。
# 在每个节点上,用于分割的特征、阈值、不等关系用一个三元组来表示,
# 即(特征,阈值,不等关系),例子(第1维特征,0.338,'<='),元组可以作为dict的key
# 当划分属性是连续值时,对应于 <= 和 > 两种情况,因此最后得到的决策树必然是一棵二叉树
class C4_5_without_pruning:
def __init__(self, epsilon):
self.epsilon = epsilon
def fit(self, X, y):
self.tree = self.build_tree(X, y)
def build_tree(self, X, y):
# 如果所有的X都属于一个y_i
temp_y = list(set(y))
if len(temp_y) == 1:
return temp_y[0]
# 如果没有可以选择的划分属性?
# 不会存在这种情况,因为连续属性可以重复用作划分属性
best_feature_index, threshold, best_gain_ratio = self.choose_best_feature_to_split(X, y)
if best_gain_ratio < self.epsilon:
return Counter(y).most_common(1)[0][0]
tree = {
}
x1, y1, x2, y2 = self.split_data(X, y, best_feature_index, threshold)
tree[(best_feature_index, threshold, '<=')] = self.build_tree(x1, y1)
tree[(best_feature_index, threshold, '>')] = self.build_tree(x2, y2)
return tree
def split_data(self, X, y, best_feature_index, threshold):
x1, x2, y1, y2 = [], [], [], []
for i in range(len(X)):
if X[i][best_feature_index] <= threshold:
x1.append(X[i])
y1.append(y[i])
else:
x2.append(X[i])
y2.append(y[i])
return np.array(x1), np.array(y1), np.array(x2), np.array(y2)
def predict(self, x):
tree = self.tree
while type(tree).__name__ == 'dict':
for key in tree.keys():
if key[2] == '<=':
key1 = key
elif key[2] == '>':
key2 = key
feature_index = key1[0]
threshold = key1[1]
if x[feature_index] <= threshold:
tree = tree[key1]
elif x[feature_index] > threshold:
tree = tree[key2]
if type(tree).__name__ == 'int64':
return tree
else:
pass
def calculate_gain_ratio(self, feature_index, X, y):
values = []
for i in range(len(X)):
values.append(X[i][feature_index])
values = list(set(values))
values.sort()
best_gain_ratio = -sys.maxsize
best_threshold = None
for i in range(len(values) - 1):
threshold = (values[i] + values[i + 1])/2
# D1和D2的作用是分别计算 <=threshold 和 >threshold 的X的数量
D1, D2 = 0, 0
# d1和d2的作用是分别计算D1和D2中各类标签(0-9)的数量
d1, d2 = [0]*10, [0]*10
for i in range(len(X)):
if X[i][feature_index] <= threshold:
D1 += 1
d1[y[i]] += 1
elif X[i][feature_index] > threshold:
D2 += 1
d2[y[i]] += 1
# 下面计算H(D|A)
part1 = 0 # <= threshold
part2 = 0 # > threshold
for i in range(10):
if d1[i] != 0:
part1 += (d1[i]/D1)*np.log2(d1[i]/D1)
if d2[i] != 0:
part2 += (d2[i]/D2)*np.log2(d2[i]/D2)
part1 = part1*D1/len(X)
part2 = part2*D2/len(X)
H_D_A = -(part1 + part2)
# 计算H(D)
C = [0]*10
for i in range(len(X)):
C[y[i]] += 1
H_D = 0
for i in range(10):
if C[i] != 0:
H_D += (C[i]/len(X))*np.log2(C[i]/len(X))
info_gain = -H_D - H_D_A
H_A_D = 0
if D1 != 0:
H_A_D += D1/len(X)*np.log2(D1/len(X))
if D2 != 0:
H_A_D += D2/len(X)*np.log2(D2/len(X))
H_A_D = -H_A_D
gain_ratio = info_gain / H_A_D
if gain_ratio > best_gain_ratio:
best_threshold = threshold
best_gain_ratio = gain_ratio
if best_threshold is None:
print('error in function calculate_gain_ratio')
return best_gain_ratio, best_threshold
# 根据西瓜书:
# 需注意的是,与离散属性不同,若当前结点划分属性为连续属性,该属性还可作为其后代结点的划分属性
# 因此不需要记录哪些属性(特征)已经使用过了
def choose_best_feature_to_split(self, X, y):
feature_num = X.shape[1]
best_feature_index = -1
best_gain_ratio = -sys.maxsize
best_feature_threshold = None
for feature_index in range(feature_num):
gain_ratio, threshold = self.calculate_gain_ratio(feature_index, X, y)
if gain_ratio > best_gain_ratio:
best_gain_ratio = gain_ratio
best_feature_index = feature_index
best_feature_threshold = threshold
# 不会发生
if best_feature_index == -1:
pass
return best_feature_index, best_feature_threshold, best_gain_ratio
下面是训练代码。
tree = C4_5_without_pruning(epsilon=0.1)
print('start training tree...')
start = time.time()
tree.fit(X[:1000], y[:1000])
end = time.time()
print('finish training... time cost: {}s'.format(end-start))
# start training tree...
# finish training... time cost: 3440.8802881240845s
下面是测试代码。
result_list = []
for i in range(len(X_test)):
result_list.append(tree.predict(X_test[i]))
print('custom C4.5 without pruning test acc: {}'.format((sum(result_list == np.array(y_test)))/len(X_test)))
# custom C4.5 without pruning test acc: 0.6173
CART
这里的CART主要是用于分类。代码同样没有脱离上面的ID3和C4.5的框架。唯一不同是分裂指标变成了gini index。
gini index的公式可以看《统计学习方法》。
直接上代码。
class CART_without_pruning:
def __init__(self, epsilon):
self.epsilon = epsilon
def fit(self, X, y):
self.tree = self.build_tree(X, y)
def build_tree(self, X, y):
# 如果所有的X都属于一个y_i
temp_y = list(set(y))
if len(temp_y) == 1:
return temp_y[0]
# 如果没有可以选择的划分属性?
# 不会存在这种情况,因为连续属性可以重复用作划分属性
best_feature_index, threshold, best_gini_index = self.choose_best_feature_to_split(X, y)
if best_gini_index < self.epsilon:
return Counter(y).most_common(1)[0][0]
tree = {
}
x1, y1, x2, y2 = self.split_data(X, y, best_feature_index, threshold)
tree[(best_feature_index, threshold, '<=')] = self.build_tree(x1, y1)
tree[(best_feature_index, threshold, '>')] = self.build_tree(x2, y2)
return tree
def split_data(self, X, y, best_feature_index, threshold):
x1, x2, y1, y2 = [], [], [], []
for i in range(len(X)):
if X[i][best_feature_index] <= threshold:
x1.append(X[i])
y1.append(y[i])
else:
x2.append(X[i])
y2.append(y[i])
return np.array(x1), np.array(y1), np.array(x2), np.array(y2)
def predict(self, x):
tree = self.tree
while type(tree).__name__ == 'dict':
for key in tree.keys():
if key[2] == '<=':
key1 = key
elif key[2] == '>':
key2 = key
feature_index = key1[0]
threshold = key1[1]
if x[feature_index] <= threshold:
tree = tree[key1]
elif x[feature_index] > threshold:
tree = tree[key2]
if type(tree).__name__ == 'int64':
return tree
else:
pass
def calculate_gini_index(self, feature_index, X, y):
values = []
for i in range(len(X)):
values.append(X[i][feature_index])
values = list(set(values))
values.sort()
best_gini_index = sys.maxsize
best_threshold = None
for i in range(len(values) - 1):
threshold = (values[i] + values[i + 1])/2
# D1和D2的作用是分别计算 <=threshold 和 >threshold 的X的数量
D1, D2 = 0, 0
# d1和d2的作用是分别计算D1和D2中各类标签(0-9)的数量
d1, d2 = [0]*10, [0]*10
for i in range(len(X)):
if X[i][feature_index] <= threshold:
D1 += 1
d1[y[i]] += 1
elif X[i][feature_index] > threshold:
D2 += 1
d2[y[i]] += 1
# 下面计算gini index
gini_D1 = 0
gini_D2 = 0
for i in range(10):
gini_D1 += math.pow(d1[i]/D1, 2)
gini_D2 += math.pow(d2[i]/D2, 2)
gini_D1 = 1 - gini_D1
gini_D2 = 1 - gini_D2
gini_index = gini_D1*D1/len(X) + gini_D2*D2/len(X)
if gini_index < best_gini_index:
best_gini_index = gini_index
best_threshold = threshold
return best_gini_index, best_threshold
# 根据西瓜书:
# 需注意的是,与离散属性不同,若当前结点划分属性为连续属性,该属性还可作为其后代结点的划分属性
# 因此不需要记录哪些属性(特征)已经使用过了
def choose_best_feature_to_split(self, X, y):
feature_num = X.shape[1]
best_feature_index = -1
best_gini_index = sys.maxsize
best_feature_threshold = None
for feature_index in range(feature_num):
gini_index, threshold = self.calculate_gini_index(feature_index, X, y)
if gini_index < best_gini_index:
best_gini_index = gini_index
best_feature_index = feature_index
best_feature_threshold = threshold
# 不会发生
if best_feature_index == -1:
pass
return best_feature_index, best_feature_threshold, best_gini_index
下面是训练代码。
tree = CART_without_pruning(epsilon=0.1)
print('start training tree...')
start = time.time()
tree.fit(X[:1000], y[:1000])
end = time.time()
print('finish training... time cost: {}s'.format(end-start))
# start training tree...
# finish training... time cost: 407.7887773513794s
下面是测试代码。
result_list = []
for i in range(len(X_test)):
result_list.append(tree.predict(X_test[i]))
print('custom CART without pruning test acc: {}'.format((sum(result_list == np.array(y_test)))/len(X_test)))
# custom CART without pruning test acc: 0.6721
用相同的数据在Sklearn上测试。
from sklearn.tree import DecisionTreeClassifier
tree = DecisionTreeClassifier(criterion='gini')
tree.fit(X[:1000], y[:1000])
predict_sklearn = tree.predict(X_test)
print('sklearn test acc: {}'.format((sum(predict_sklearn == np.array(y_test)))/len(X_test)))
# sklearn test acc: 0.6486
RandomForest
随机森林是基于bagging的思想。本文主要介绍用于分类的随机森林。
随机森林可以理解为决策树的集合。
一个随机森林在训练时。
一个随机森林在测试时。