1. 大数据
“大数据”术语自1990年底初就已提出。
大数据描述了实施采集、累积和分析大量异构数据(文本、音频、视频、图像、元数据等)的活动。
随着互联网的发展,可用数据呈指数级增长。
大数据的来源主要有:
- 互联网搜索
- 社交网络
- 应用程序
- 语音助手
- 智能手机
- 物理传感器及所有其它物联网。
大数据现象是21世纪经济、社会和政治的主要驱动力之一,推动了人工智能等大数据分析技术的发展。
1.1 大数据垄断
谷歌和脸书共享最大的份额,剩下的只有面包屑。
超过92%的网络搜索通过Google进行,而Google每秒处理40,000多个请求-每年超过345亿。其余市场分为Bing,Yahoo,百度,YANDEX和DuckDuckGo。
仅Facebook和Google就能控制全球(不包括中国)超过84%的广告活动(定向广告)。Facebook收入的98.5%来自定向广告。
这种垄断扭曲了曾经的集体梦想,即创造一种机器,利用每天由数十亿人创建的数据来丰富极少的人,并为他们的使用和消费塑造现实。所有这些,大多数人都不知道。
大数据现像催生了所谓的监督资本主义:
监督资本主义是一种新的经济秩序,它声称人类的经验是产生可出售产品和服务并塑造未来人类行为的预测的原材料。
这个概念非常简单:任何人类行为或经验都会产生原始数据。可以实时获取和处理这些数据以获得有用的信息,以预测我们未来的行动,思想和感受。
该人既是原料又是消费者,在这个新的生产工艺,创造产品从自己的数据开始的人,在一个怪诞的无限循环。
监视资本主义和大数据仅仅是概念。新经济的真正引擎是基于大数据的算法和数学模型。
1.2 大数据分析算法的问题
凯茜·奥尼尔(Cathy O’Neil)在她的《数学毁灭性武器》一书中将算法描述为一种观点,并整合到数学模型中。我们人类通常称之为刻板印象。这些数学刻板印象通常隐藏在“个性化”或“优化”服务的后面。
现在,每个人类领域都充满着算法的自动决策,这些算法每天都会影响数百万人的现实:从网络上可用的信息,求职,政治,教育,正义和金融。
这些自动化的决策过程会给社区和个人带来负面影响(负面外部影响)。采纳它们的组织,无论是公共的还是私人的,都没有任何反馈,除了获利。增加利润的算法是有效的算法。
- 剑桥Analytica丑闻以及2016年美国大选和英国脱欧公投的严重影响向世界展示了大数据的阴暗面和心理分析的力量。
- 2020年8月,许多英语学生受到政府采用的一种算法进行歧视,该算法基于与学生的实际技能无关的数据来决定他们的高中成绩。
- 甚至在最近,一位意大利法官还判处Deliveroo采用了一种算法,该算法会根据骑手的缺席情况将其降级,而不论其原因如何。
2. 隐私
2014年,欧洲数据保护委员会“第29工作组”发布了有关大数据影响的一些声明。
该委员会对大数据寄予厚望,并期望找到一种创新的方法在保护个人数据的同时,带来许多集体和个人利益。
欧盟议会于2016年4月14日通过的《通用数据保护条例(General Data Protection Regulations)》(“GDPR”)将于2018年5月25日在欧盟成员国内正式生效实施。该条例的适用范围极为广泛,任何收集、传输、保留或处理涉及到欧盟所有成员国内的个人信息的机构组织均受该条例的约束。
迄今为止,Google仍然声称不出售个人数据。的确,他们的业务不是出售产品,而是处理个人数据以获得(和出售)情报。个人数据是Google制造铁匠铺的理想之选。
在信息过载和令人难以置信的复杂的个人数据处理操作的已经销毁的透明度所有的希望。人们大部分时间都不了解正在发生的事情,甚至都不问。
缺乏了解是导致人们对隐私失去兴趣的原因。
3. 人工智能算法 AI
人工智能是一种在某些严重威胁人权的活动中越来越多地使用的技术,例如:
- 边境管制和移民
- 生物特征质量监测
- 社会得分和预测警察
欧洲联盟有机会进行干预,向世界展示,在尊重人们基本权利的同时进行技术创新是可能的。
3.1 联邦学习
联邦机器学习又名联邦学习,联合学习,联盟学习。联邦机器学习是一个机器学习框架,能有效帮助多个机构在满足用户隐私保护、数据安全和政府法规的要求下,进行数据使用和机器学习建模。
而在大多数行业中,由于行业竞争、隐私安全、行政手续复杂等问题,数据常常是以孤岛的形式存在的。甚至即使是在同一个公司的不同部门之间实现数据集中整合也面临着重重阻力。在现实中想要将分散在各地、各个机构的数据进行整合几乎是不可能的,或者说所需的成本是巨大的。
针对数据孤岛和数据隐私的两难问题,多家机构和学者提出解决办法。针对手机终端和多方机构数据的隐私问题,谷歌公司和微众银行分别提出了不同的“联邦学习”(Federated Learning)算法框架。谷歌公司提出了基于个人终端设备的“联邦学习”(Federated Learning)算法框架,而AAAI Fellow 杨强教授与微众银行随后提出了基于“联邦学习”(Federated Learning)的系统性的通用解决方案,可以解决个人(2C)和公司间(2B)联合建模的问题。在满足数据隐私、安全和监管要求的前提下,设计一个机器学习框架,让人工智能系统能够更加高效、准确的共同使用各自的数据。
举例来说,假设有两个不同的企业 A 和 B,它们拥有不同数据。比如,企业 A 有用户特征数据;企业 B 有产品特征数据和标注数据。这两个企业按照上述 GDPR 准则是不能粗暴地把双方数据加以合并的,因为数据的原始提供者,即他们各自的用户可能不同意这样做。假设双方各自建立一个任务模型,每个任务可以是分类或预测,而这些任务也已经在获得数据时有各自用户的认可,那问题是如何在 A 和 B 各端建立高质量的模型。由于数据不完整(例如企业 A 缺少标签数据,企业 B 缺少用户特征数据),或者数据不充分 (数据量不足以建立好的模型),那么,在各端的模型有可能无法建立或效果并不理想。联邦学习是要解决这个问题:它希望做到各个企业的自有数据不出本地,而后联邦系统可以通过加密机制下的参数交换方式,即在不违反数据隐私法规情况下,建立一个虚拟的共有模型。这个虚拟模型就好像大家把数据聚合在一起建立的最优模型一样。但是在建立虚拟模型的时候,数据本身不移动,也不泄露隐私和影响数据合规。这样,建好的模型在各自的区域仅为本地的目标服务。在这样一个联邦机制下,各个参与者的身份和地位相同,而联邦系统帮助大家建立了“共同富裕”的策略。
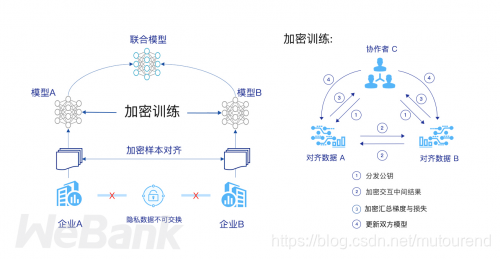
根据孤岛数据的分布特点将联邦学习分为三类:
-
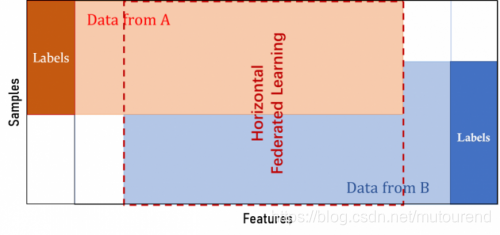
两个数据集的数据特征(X1,X2,…)重叠部分较大,而用户(U1, U2…)重叠部分较小; 【横向联邦学习】
-
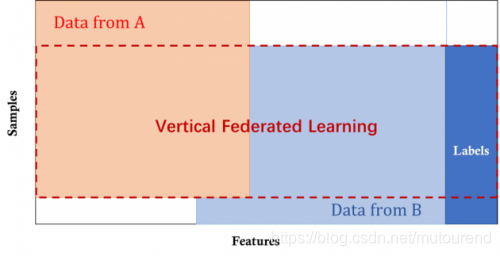
两个数据集的用户(U1, U2…)重叠部分较大,而数据特征(X1,X2,…)重叠部分较小; 【纵向联邦学习】
-
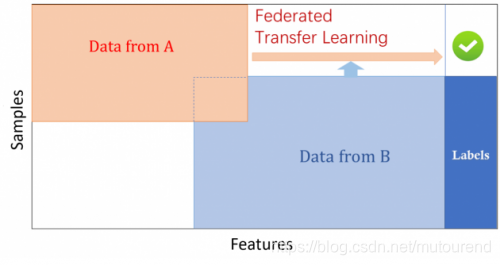
两个数据集的用户(U1, U2…)与数据特征重叠(X1,X2,…)部分都比较小。【联邦迁移学习】
参考资料
[1] https://privacy-network.it/un-sogno-chiamato-big-data/
[2] 《My Data Is Mine》
[3] https://baike.baidu.com/item/%E8%81%94%E9%82%A6%E6%9C%BA%E5%99%A8%E5%AD%A6%E4%B9%A0/23618046?fr=aladdin
[4] https://baike.baidu.com/item/%E9%80%9A%E7%94%A8%E6%95%B0%E6%8D%AE%E4%BF%9D%E6%8A%A4%E6%9D%A1%E4%BE%8B/22616576?fr=aladdin
[5] https://privacy-network.it/iniziative/contro-intelligenza-artificiale-che-viola-i-diritti-umani/