什么是多标签分类
学习过机器学习的你,也许对分类问题很熟悉。比如下图:

图片中是否包含房子?你的回答就是有或者没有,这就是一个典型的二分类问题。

同样,是这幅照片,问题变成了,这幅照片是谁拍摄的?备选答案你,你的父亲,你的母亲?这就变成了一个多分类问题。

但今天谈论的多标签是什么呢?
如果我问你上面图包含一座房子吗?选项会是YES或NO。

你会发现图中所示的答案有多个yes,而不同于之前的多分类只有一个yes。
这里思考一下:
一首歌:如果你有四个类别的音乐,分别为:古典音乐、乡村音乐、摇滚乐和爵士乐,那么这些类别之间是互斥的。这首歌属于哪个类别?这是一个什么问题?
一首歌:如果你有四个类别的音乐,分别为:人声音乐、舞曲、影视原声、流行歌曲,那么这些类别之间并不是互斥的。这首歌属于哪个类别?这是一个什么问题?
多标签的问题的损失函数是什么
这里需要先了解一下softmax 与 sigmoid函数

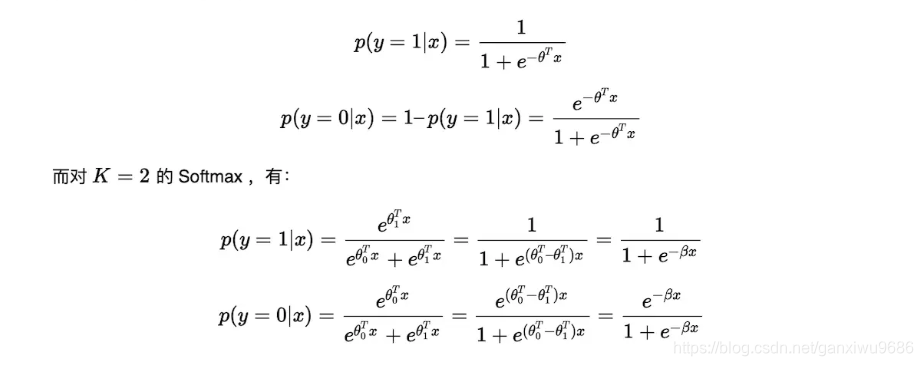
这两个函数最重要的区别,我们观察一下:

区别还是很明显的。
综上,我们可以得出以下结论:
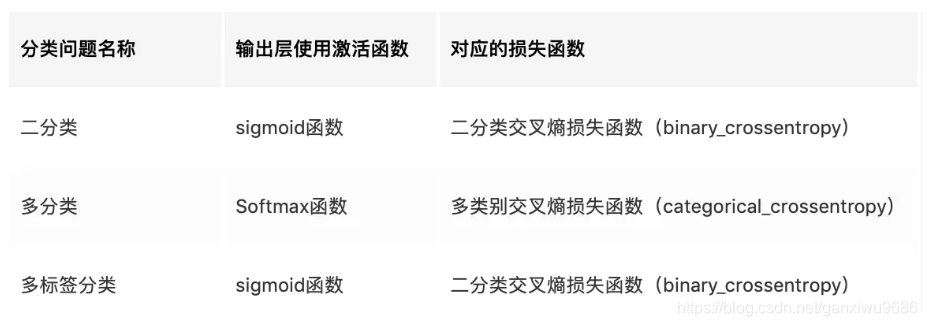
pytorch中的实现
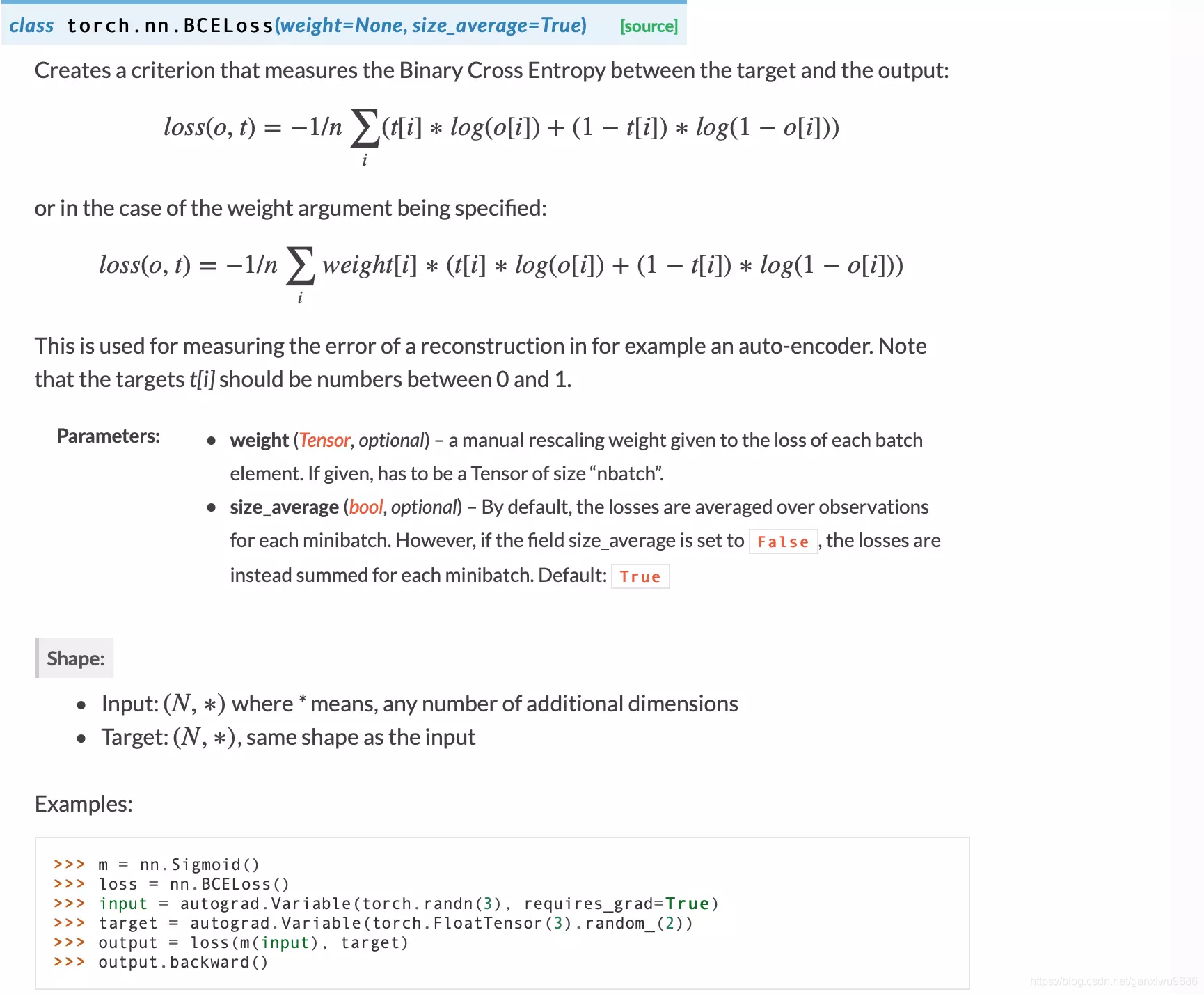
PyTorch提供了两个类来计算二分类交叉熵(Binary Cross Entropy),分别是BCELoss() 和BCEWithLogitsLoss()
看一下源码,参考帮助,我们来看一下
from torch import autograd
input = autograd.Variable(torch.randn(3,3), requires_grad=True)
print(input)
tensor([[ 1.9072, 1.1079, 1.4906],
[-0.6584, -0.0512, 0.7608],
[-0.0614, 0.6583, 0.1095]], requires_grad=True)
因为Note that the targets t[i] should be numbers between 0 and 1.
所以需要先sigmoid:
from torch import nn
m = nn.Sigmoid()
print(m(input))
tensor([[0.8707, 0.7517, 0.8162],
[0.3411, 0.4872, 0.6815],
[0.4847, 0.6589, 0.5273]], grad_fn=<SigmoidBackward>)
假设你的target如下:
target = torch.FloatTensor([[0, 1, 1], [1, 1, 1], [0, 0, 0]])
print(target)
tensor([[0., 1., 1.],
[1., 1., 1.],
[0., 0., 0.]])
我们先根据源码中公式,计算下:
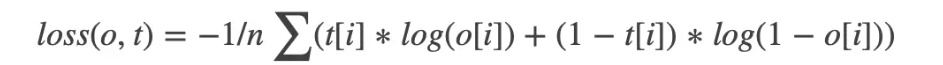
import math
r11 = 0 * math.log(0.8707) + (1-0) * math.log((1 - 0.8707))
r12 = 1 * math.log(0.7517) + (1-1) * math.log((1 - 0.7517))
r13 = 1 * math.log(0.8162) + (1-1) * math.log((1 - 0.8162))
r21 = 1 * math.log(0.3411) + (1-1) * math.log((1 - 0.3411))
r22 = 1 * math.log(0.4872) + (1-1) * math.log((1 - 0.4872))
r23 = 1 * math.log(0.6815) + (1-1) * math.log((1 - 0.6815))
r31 = 0 * math.log(0.4847) + (1-0) * math.log((1 - 0.4847))
r32 = 0 * math.log(0.6589) + (1-0) * math.log((1 - 0.6589))
r33 = 0 * math.log(0.5273) + (1-0) * math.log((1 - 0.5273))
r1 = -(r11 + r12 + r13) / 3
#0.8447112733378236
r2 = -(r21 + r22 + r23) / 3
#0.7260397266631787
r3 = -(r31 + r32 + r33) / 3
#0.8292933181294807
bceloss = (r1 + r2 + r3) / 3
print(bceloss)
0.8000147727101611
核心解读
就是把每一个标签的预测值(sigmoid计算之后)交给cross_entropy函数来进行分类计算。比如样本1是一张图片(r1),r11代表某一个标签(有房子),r12代表某一个标签(有树), r13代表某一个标签(有小狗),最后r1就是样本1的预测值与真实值之间的loss。
我们再对比一下使用torch内置的loss函数:
loss = nn.BCELoss()
print(loss(m(input), target))
tensor(0.8000, grad_fn=<BinaryCrossEntropyBackward>)
和我们自己算的误差非常小,可以忽略。
我们也可以把sigmoid和bce的过程放到一起,使用内建的BCEWithLogitsLoss函数
loss = nn.BCEWithLogitsLoss()
print(loss(input, target))
tensor(0.8000, grad_fn=<BinaryCrossEntropyWithLogitsBackward>)