首先需要明确查询性能低下的基础原因:访问数据过多。
还有一种可能性:筛选大量数据,但是并不常见。
通常情况下性能低下的查询都可以通过减少访问数据量的方式进行优化。
分析慢查询
两种分析方法:
- 应用程序是否在检索大量超过需要的数据。
- 确认MySQL服务器是否在分析大量超过需要的数据行。
一、是否向数据库请求了不需要的数据
描述:一个查询请求了超过实际需要的数据,但是多余的部分并没有什么用处而被丢掉。
影响:这会给MySql服务器带来额外的负担,增加网络开销,消耗应用服务器的CPU和内存资源
典型案例:
-
查询不需要的记录:如分页查询中每次都全部查询,但是只显示一部分。
-
多表关联时返回全部列:
比如典型的”图书分类-图书“模式,该模式包含三个数据表:图书、图书分类、图书-图书分类
我们想查询A分类中所有的图书
一种错误的写法是:
SELECT * FROM 图书 INNER JOIN 图书-图书分类 ON xxxx INNER JOIN 图书分类 ON xxxx WHERE 图书分类.name="A"上面的写法返回了整个关联表的内容
我们应该只获取所需,正确的写法如下
SELECT 图书.* FROM .... -
总是取出全部列:每次使用SELECT *的时候都应该小心,取出所有的列、会导致优化器无法完成索引覆盖扫描这类优化,同时带来额外的I/O、内存和CPU的消耗。在阿里巴巴的规范中,就明确禁止了使用*进行查询

-
重复查询相同的数据:对于不会修改的较为持久的信息,如用户头像,反复查询将浪费资源,缓存为更好的选择。
二、是否在扫描额外的记录
确定了查询只返回了需要的数据后,接下来优化是否扫描过多的数据。
这里有衡量查询开销的三个最简单的指标
- 响应时间
- 扫描的行数
- 返回的行数
没有哪个指标可以完美衡量查询的开销,但是大致反映了MySQL在内部执行查询时需要访问多少数据,并可以大概推算出查询运行的时间。这三个指标会记录着MySQL的慢日志中
检查慢日志是找出扫描行数过多的查询的好办法
参考这片文章https://juejin.cn/post/6844903473079648264
首先我们给出几个理想的状态
理想的查询:
- 响应时间快
- 扫描的行数与返回的行数相同
- 使用尽可能快的访问类型
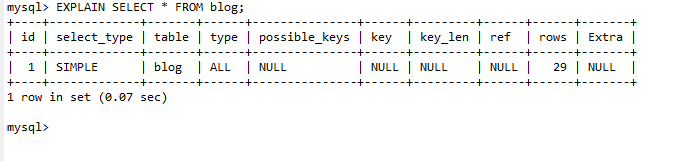
使用EXPLAIN可以分析查询执行的方式,举例如下
EXPLAIN SELECT * FROM xxx;
访问类型有很多种分别有
全表扫描、索引扫描、范围扫描、唯一索引查询、常数引用等。

一般情况下,MySQL使用如下三种方式应用WHERE,从好到坏依次为:
-
在索引中使用WHERE条件过滤(在存储引擎层完成,即WHERE为索引)
-
使用索引覆盖扫描来返回记录,直接从索引中过滤不需要的记录并返回命中结果。(MySQL服务器层完成,Extra列为Using Index)

-
从数据表中返回数据,然后过滤不满足条件的记录(Extra列中出现Using Where)。

若存在扫描大量数据但只返回少数的行
- 使用索引覆盖扫描,把需要的列放置在索引中,这样存储引擎无须回表获取对应行(聚簇索引)。
- 改变库表结构。例如使用单独的汇总表
- 重写这个复杂的查询,让MySQL优化器能以更优化的方式执行这个查询。