版本:
- Zeppelin :Apache Zeppelin0.9.0
- OS:CentOs 7
- 大数据组件:CDH 6.2.0对应版本
- JAVA:1.8
一、Apache Zeppelin简介
Apache Zeppelin是一个Web交互式的开发系统,支持数据处理、数据可视化。
二、安装步骤
1.下载Apache Zeppelin0.9.0
wget https://mirror.bit.edu.cn/apache/zeppelin/zeppelin-0.9.0-preview1/zeppelin-0.9.0-preview1-bin-all.tgz
2.解压
tar -xvf zeppelin-0.9.0-preview1-bin-all.tgz
3.修改配置文件
cd $ZEPPELIN_HOME/conf
vim zeppelin-env.sh
export HADOOP_CONF_DIR=/etc/hadoop/conf
export SPARK_HOME=/opt/cloudera/parcels/CDH/lib/spark
export FLINK_HOME=/opt/software/flink
export HIVE_HOME=/opt/cloudera/parcels/CDH/lib/hive
export HIVE_CONF_DIR=/etc/hive/conf
export ZEPPELIN_ADDR=ip
export ZEPPELIN_PORT=port
注意:host就是要安装的服务器ip,port要用一个不常用的,避免端口占用问题
4.启动
cd $ZEPPELIN_HOME/bin
sh zeppelin-daemon.sh start
5.打开浏览器,输入url
http://ip:port
看到如下界面说明已经安装成功了
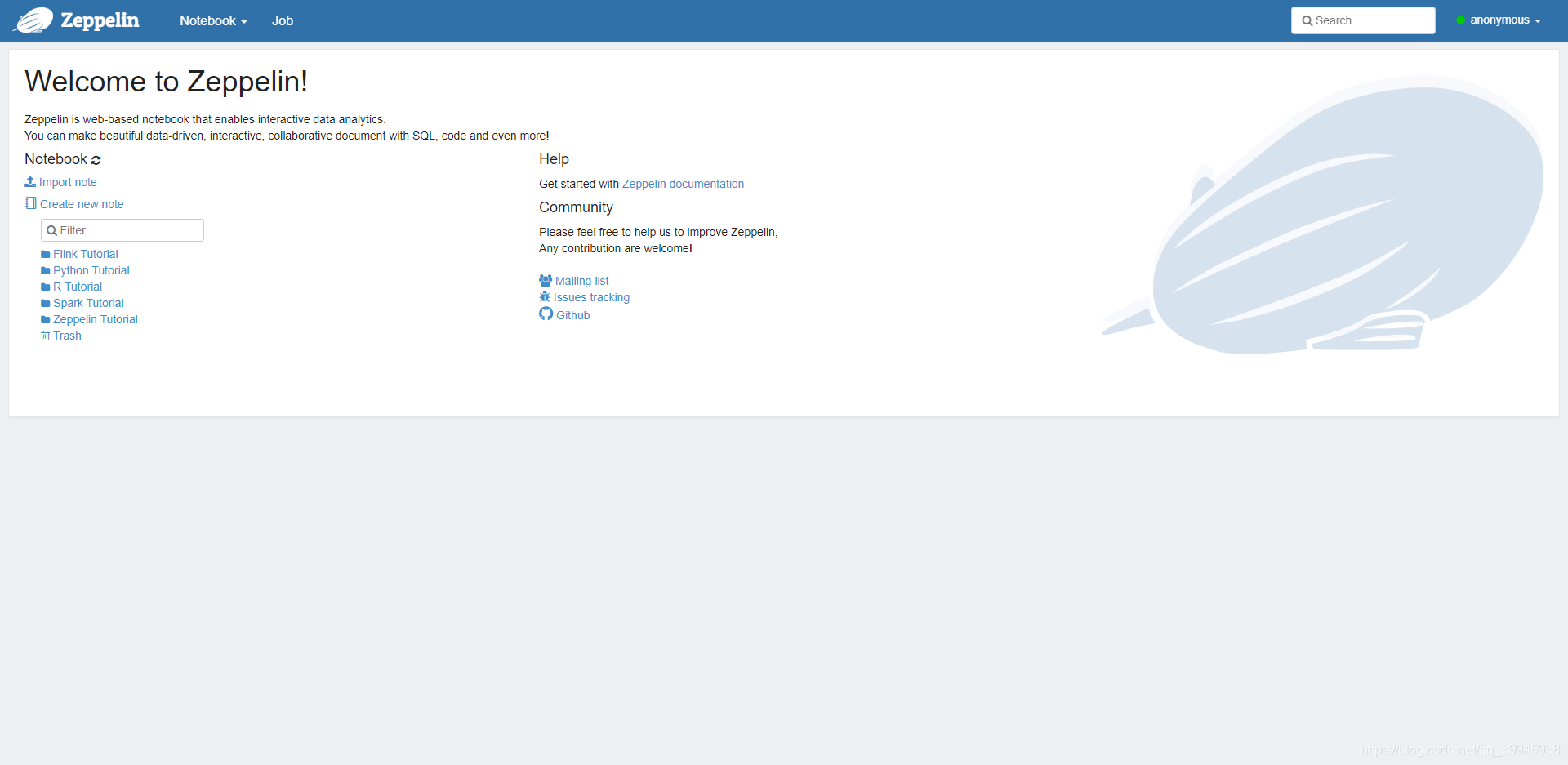
6.运行spark官方示例
1.点击Spak Tutorial
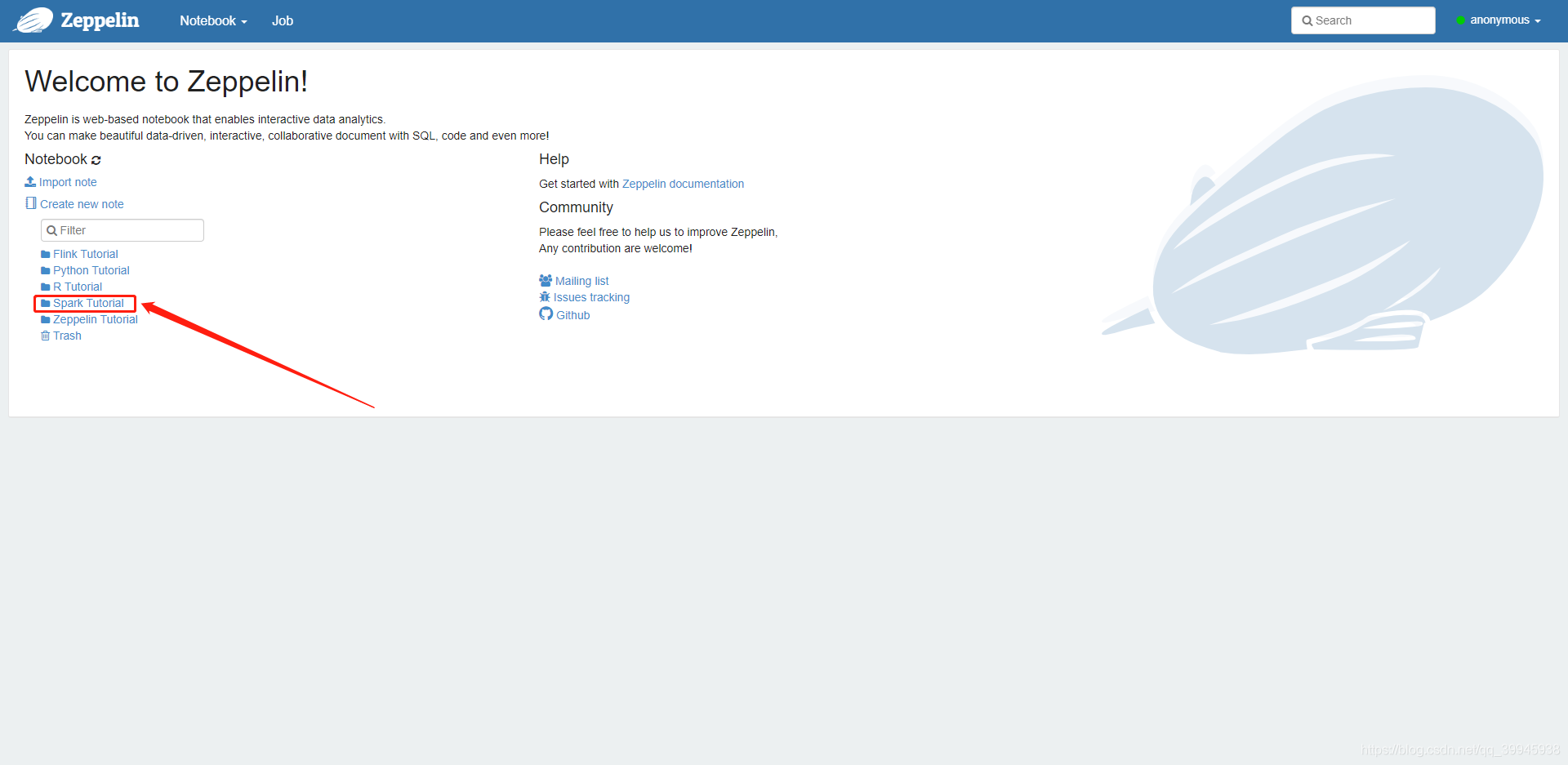
2.点击Spark Basic Features
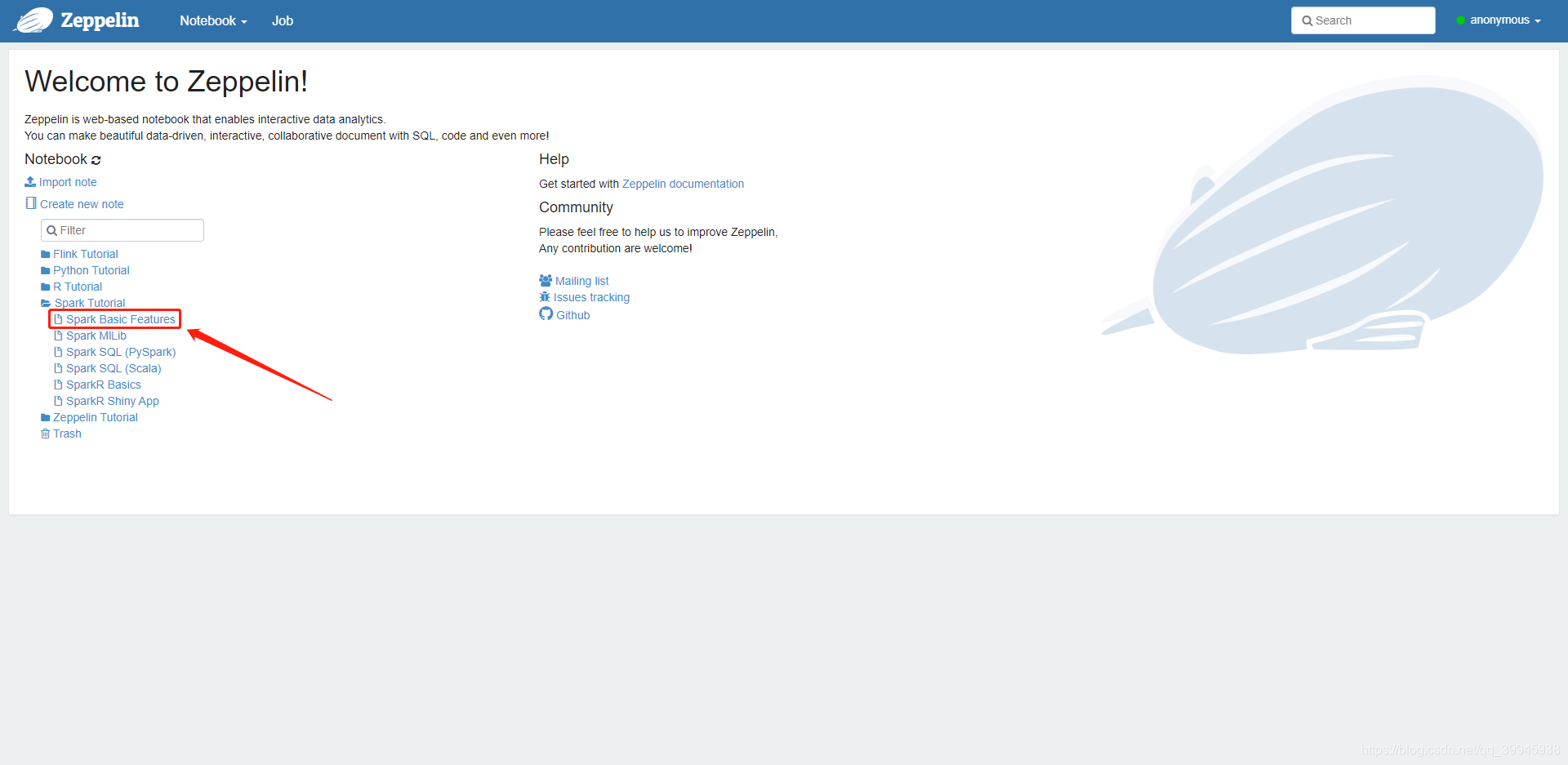
3.点击右上角三角型按钮运行
此处代码做的事是读取文件注册为一个名字叫bank的临时表
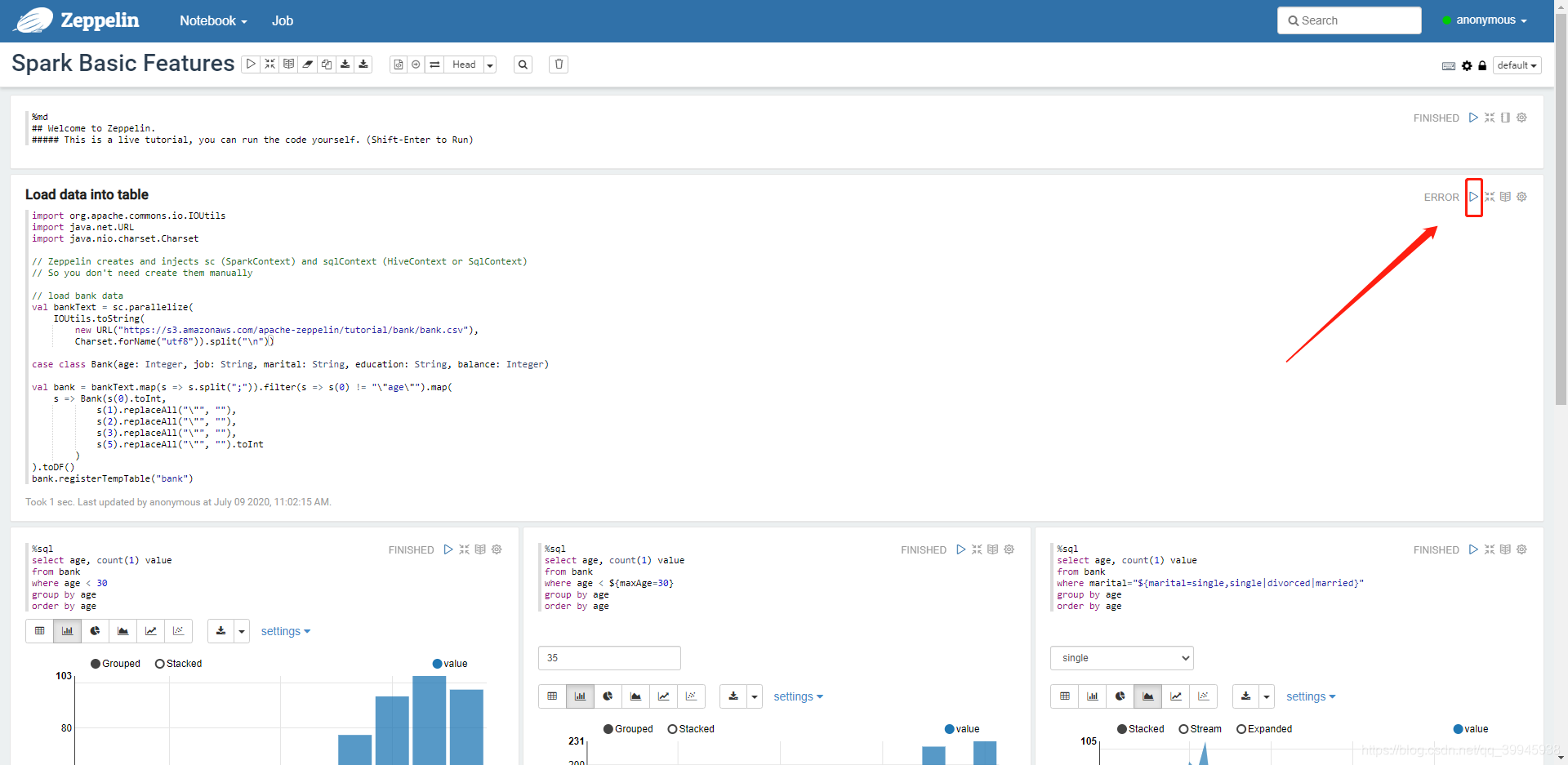 可以看到日志没有报错,右上角状态为finish
可以看到日志没有报错,右上角状态为finish
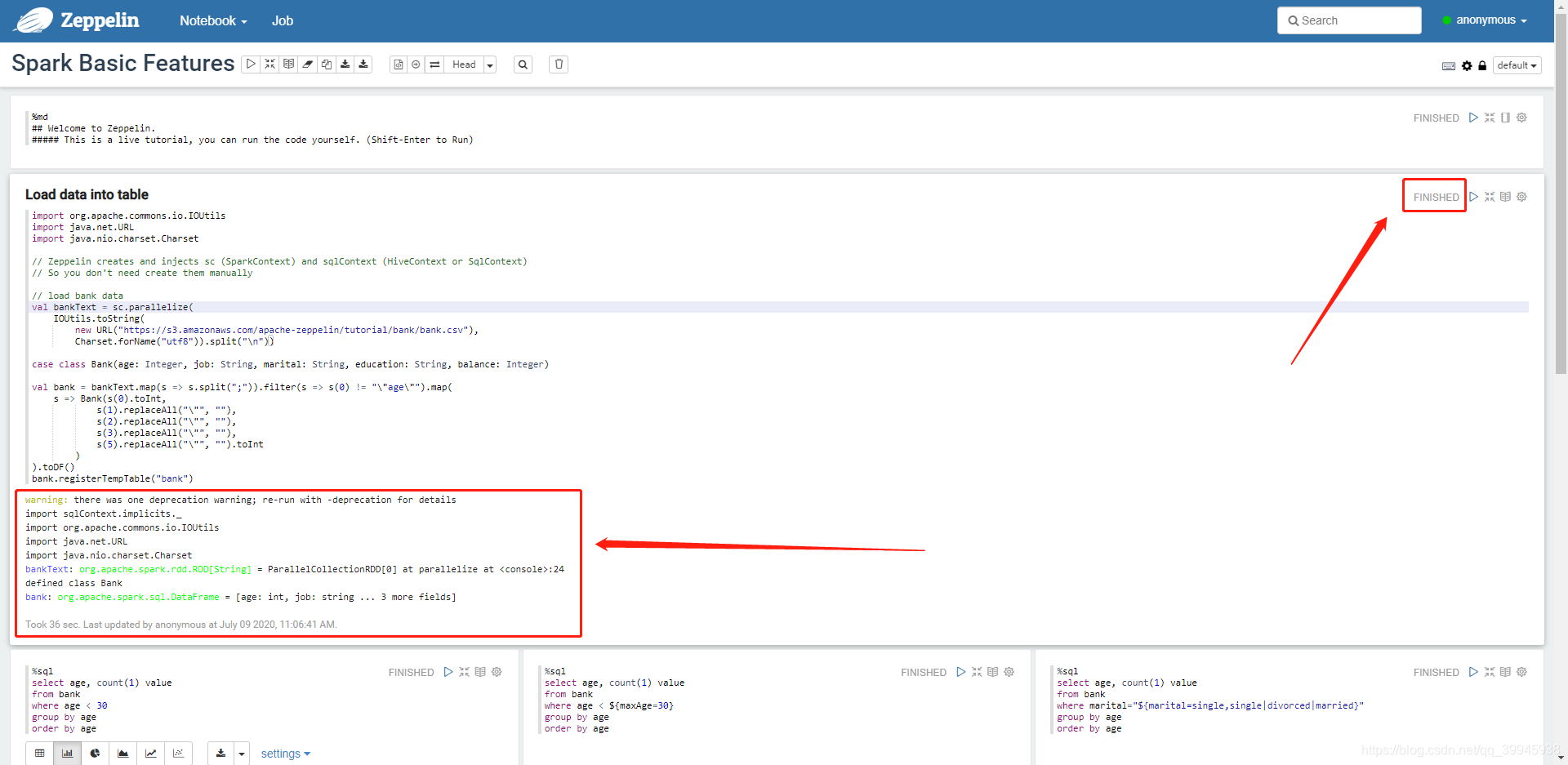
4.依次点击按钮执行下方的任务
这三个任务做的事都是查询上面注册的叫bank的临时表,下方的图表是结果
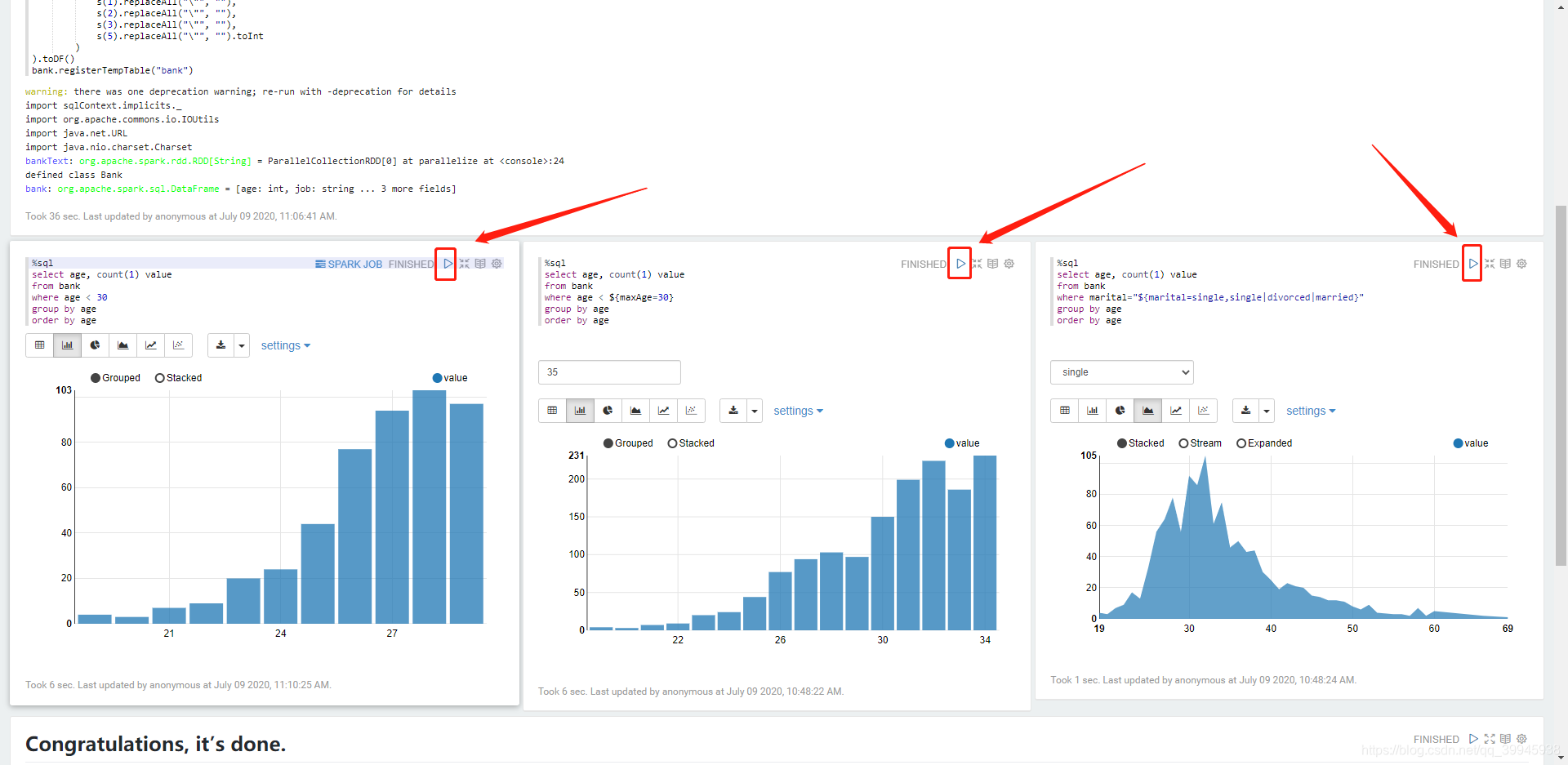 下图是执行结果,从下方图表、日志和状态来看,3个任务都已执行成功
下图是执行结果,从下方图表、日志和状态来看,3个任务都已执行成功
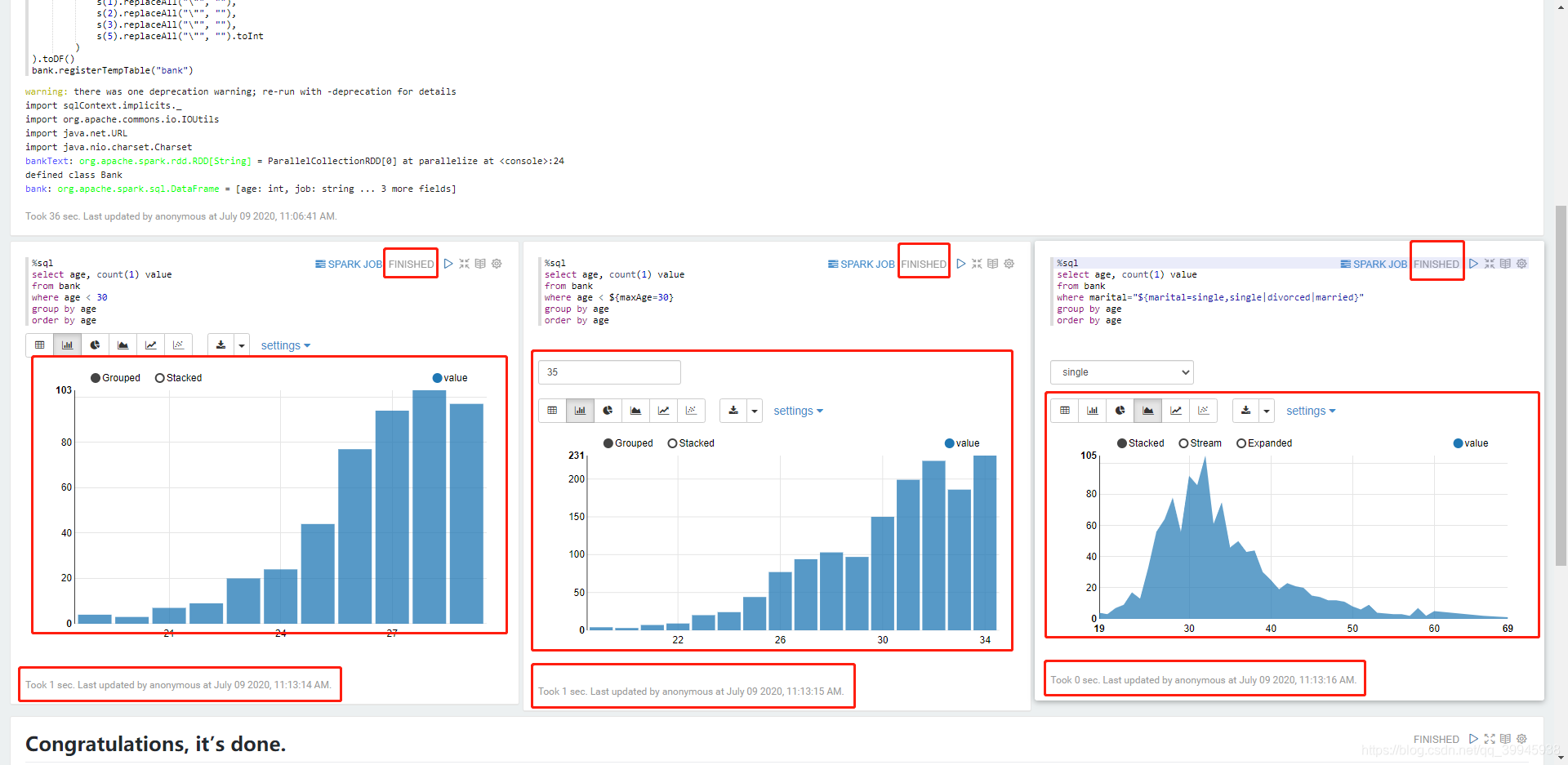 注意:Spark Basic Features 第2次执行Load datainto table时会报错。
注意:Spark Basic Features 第2次执行Load datainto table时会报错。
解决:
https://blog.csdn.net/qq_39945938/article/details/107230571