准备
- 建议最少4台物理机或者虚拟机(一个控制节点,3个数据节点),4核16G,硬盘500G,挂载根目录
- 如果用于学习,可以4核8G,如果是生产部署,推荐8核32G以上
- 系统为CentOS7.6,使用root用户登录
- CDH版本为6.2.0
基础配置
改host、jdk那些跟安装hadoop集群的前期操作是一样的,这里不再多说
这个做个答疑:关于安装mysql库的问题:
几乎每篇帖子都会写道安装mysql库,其实也可以不安装mysql库,用你自己之前有的,改一下配置文件就好,接下来我开始说详细应该怎么去安装:
1.安装mysql驱动(所有节点)
在官网上下载mysql-connector-java-5.1.47.tar.gz,解压出 mysql-connector-java-5.1.47.jar
在所有节点上,执行:
mkdir -p /usr/share/java
cp mysql-connector-java-5.1.47.jar /usr/share/java/mysql-connector-java.jar2.下载cloudera 6.2.0(注:目前cm6.2.0 已经更新为安装6.2.1,这个需提前下载好)
ClouderaManager下载地址
https://archive.cloudera.com/cm6/6.2.0/redhat7/yum/RPMS/x86_64/
下载这四个文件:

CDH6.2.0安装包地址:https://archive.cloudera.com/cdh6/6.2.0/parcels/
下载这四个文件:

3. 创建/usr/share/java目录,将mysql-jdbc包放过去(所有节点)
- mkdir -p /usr/share/java
- mv /opt/mysql-j/mysql-connector-java-5.1.34.jar /usr/share/java/
- mysql-connector-java-5.1.34.jar 一定要命名为mysql-connector-java.jar
4.防止出现莫名错误,事先安装以下插件(所有节点)
yum install cloudera-manager-daemons cloudera-manager-agent cloudera-manager-server --skip-broken --nogpgcheck
5. 安装Httpd服务(manager)
- yum install httpd
- service httpd start
- systemctl enable httpd.service 设置httpd服务开机自启
6.导入GPG key(如果没有这步操作,很可能cloudera服务安装失败)manager节点
rpm --import https://archive.cloudera.com/cm6/6.2.0/redhat7/yum/RPM-GPG-KEY-cloudera
7.安装cloudera-manager-server(主节点节点)
yum install cloudera-manager-server-6.2.0-968826.el7.x86_64.rpm cloudera-manager-daemons-6.2.0-968826.el7.x86_64.rpm
8.parcel初始化
在cdh1节点上,新建parcel目录:
mkdir -p /opt/cloudera/parcel-repo并复制parcel到该目录:(把cdh那4个包全挪过来)
mv CDH-6.2.0-1.cdh6.2.0.p0.967373-el7.parcel /opt/cloudera/parcel-repo
mv CDH-6.2.0-1.cdh6.2.0.p0.967373-el7.parcel.sha1 /opt/cloudera/parcel-repo/CDH-6.2.0-1.cdh6.2.0.p0.967373-el7.parcel.sha
mv manifest.json /opt/cloudera/parcel-repo9.配置cloudera-scm-server数据库连接
在cdh1节点上,编辑/etc/cloudera-scm-server/db.properties,配置数据库,示例如下:(这块写你自己的库,事先创好库)
com.cloudera.cmf.db.type=mysql
com.cloudera.cmf.db.host=localhost
com.cloudera.cmf.db.name=cmf
com.cloudera.cmf.db.user=YOUR_DB_USER_NAME
com.cloudera.cmf.db.password=YOUR_DB_USER_PASSWORD
com.cloudera.cmf.db.setupType=EXTERNAL注意:请保证mysql中有一个名为cmf的空数据库
10.启动server
在cdh1节点上,执行:
service cloudera-scm-server start11.安装cloudera-manager-agent(所有数据节点)
rpm安装
yum install cloudera-manager-agent-6.2.0-968826.el7.x86_64.rpm cloudera-manager-daemons-6.2.0-968826.el7.x86_64.rpm
12.config配置
在cdh2、cdh3、cdh4节点上,编辑/etc/cloudera-scm-agent/config.ini文件,将server_host修改为cdh1
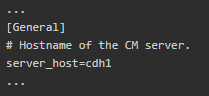
13.启动angent
在cdh2、cdh3、cdh4节点上,执行:
service cloudera-scm-agent start14.安装cloudera
打开浏览器,访问cdh01:7180(启动比较慢,需要1-2分钟)
默认用户名/密码: admin/admin
按照步骤安装即可(建议选择社区版安装)
下面是遇到的问题,可以参考:
Can't open /var/run/cloudera-scm-agent/process/261-hdfs-DATANODE/supervisor.conf: Permission denied.

这个问题先处理权限问题,处理完事儿后再试,
sduo chmod -R 777 /usr/local/hadoop/logschown -R cloudera-scm:cloudera-scm /var/*
不行再用第二种方法;
怀疑是权限问题,上网查询了之后,才知道看起来是权限问题,其实不是,需要看看具体的datanode启动日志,于是到/var/log/hadoop-hdfs/目录下
namenode的clientID与datanode的clientID不一致的错误。
1.namenode启动失败,查看错误原因,是无法格式化,再看日志,根据日志提示,清空对应的目录,即可解决这个问题。
2.datanode启动失败:
问题原因
是由于之前初始化 namenode 在 /dfs/nn 留下了残留数据(失效数据),从而影响再次初始化
解决方法
清空残留数据后,重新初始化
namenode节点:
rm -rf /dfs/nndatanode节点:
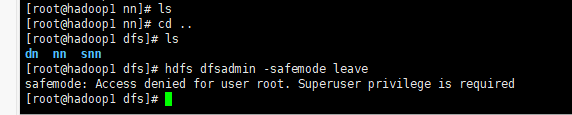
rm -rf /dfs/dnCommand aborted because of exception: Command timed-out after 90 seconds
解决方法:
su - hdfs
hdfs dfsadmin -safemode leavejava.lang.Error: Properties init: Could not determine current working directory

该错误表示 getcwd 命令无法定位到当前工作目录。一般来说是因为你 cd 到了某个目录之后 rm 了这个目录,这时去执行某些 service 脚本的时候就会报 getcwd 错误。只需要 cd 到任何一个实际存在的目录下再执行命令即可。
这里再说明一点:
关于hive,经常性有人装不上去,但有时候特别顺利,这个时候留意hive对应的库的表够不够,有时候创建表不全的时候就会出现这个找不到表之类的问题,多试几次,或者用已经安装过的表,直接导入
================================================================================================
以上为安装过程的一些问题,现在总结一下安装好后关于环境配置的一些问题,这些问题可能不影响大的使用,但是会影响一些使用效果:
注意点:hdfs://172.16.30.81:8020 CDH是8020不是9000
1.Kafka 修改内容:

2.Spark 修改参数:
a.修改乱码


spark-conf/spark-defaults.conf 的 Spark 客户端高级配置代码段(安全阀):
spark.executor.extraJavaOptions=-Dfile.encoding=utf-8 -Dsun.jnu.encoding=utf-8
spark.driver.extraJavaOptions=-Dfile.encoding=utf-8 -Dsun.jnu.encoding=utf-8
spark.kryoserializer.buffer.max=256m //写入redis报错
spark.kryoserializer.buffer=64m
spark-conf/spark-history-server.conf 的 History Server 高级配置代码段(安全阀)
spark.executor.extraJavaOptions=-Dfile.encoding=utf-8 -Dsun.jnu.encoding=utf-8
spark.driver.extraJavaOptions=-Dfile.encoding=utf-8 -Dsun.jnu.encoding=utf-8b.

这个错加这个
spark.kryoserializer.buffer.max=256m //写入redis报错
spark.kryoserializer.buffer=64m 3.Yarn

-Djava.net.preferIPv4Stack=true -Dfile.encoding=utf-8 -Duser.language=zh


4.HDFS:

5.Hive 修改参数:



org.elasticsearch.bootstrap.StartupException: java.lang.IllegalStateException: failed to obtain node
解决方案:
修改elasticsearch config目录下的elasticsearch.yml
添加:

node.max_local_storage_nodes: 256
CDH重启命令
service cloudera-scm-server-db restart
service cloudera-scm-server restart
service cloudera-scm-agent restart
--- 备注:
如果运行环境跟jar包运行环境不在同一台机器上,如果运行自己程序报错的话,将CDH机器上的 /opt 下cdh相关的内容和 /etc下的相关内容传送过来,配置对应的环境变量,可以使用