马银霜,你辞职了,我真的好难过,感觉这个公司没有你的存在,那么对我来说毫无意义
概念定义: partition,叫做数据段,在分布式理论中,数据段也可能叫segment,也可能叫chunk,这取决于具体的中间件,而在kafka中,数据段被叫做partition
在kafka中,partition是以.log文件的方式存在的,而这个log文件,就叫做 commit log文件
partition有四个属性
time index:表示这条数据插入的时间
index:表示这条数据在partition的位置
leo:log end offset,表示leader partition中最新的数据位置
hw:high watermark,消费者能看到(能消费)的最新的数据位置,也可以说hw是所有partition(同一个leader下的)副本中消息的交集,也可以说hw是所有partition中拥有的最少数据量的那个partition的最新数据
日记:leo减hw等于follower partition还没有同步的数据条数
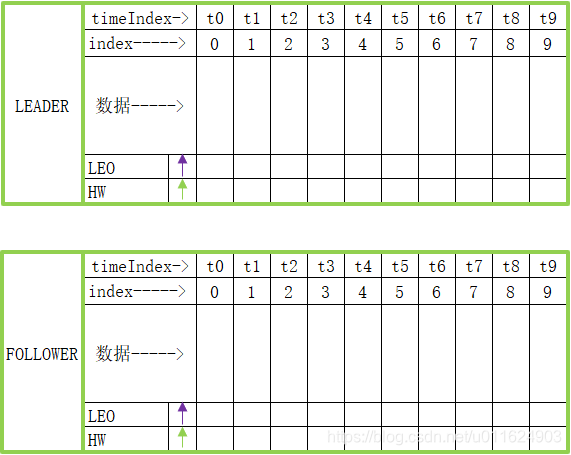
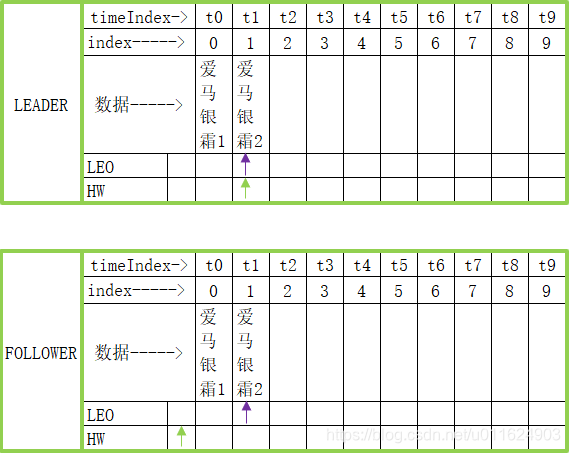
partition本质上是一个文件,在硬盘上,每条数据都存在这个文件中,并且这些数据是按照插入顺序排列的,下图将展示一个leader partition,且它拥有一个follower partition,最开始一条数据都没有
下面往这个partition中插入一条数据,数据的内容是"爱马银霜1",并且follower还没有同步leader的数据
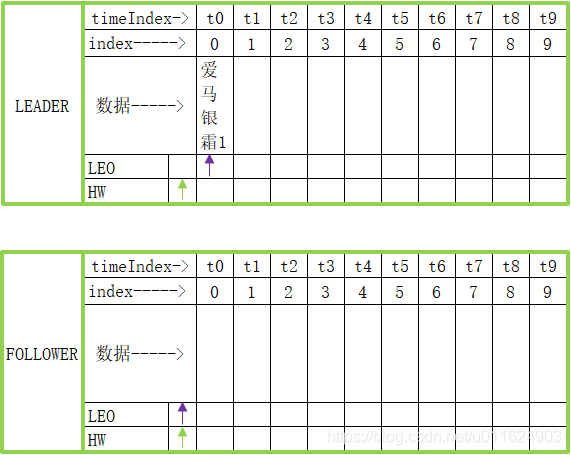
HW表示所有副本中,同步最慢的那个follower已经同步到哪里了(但是本例只有一个follower)
现在follower已经同步完毕数据
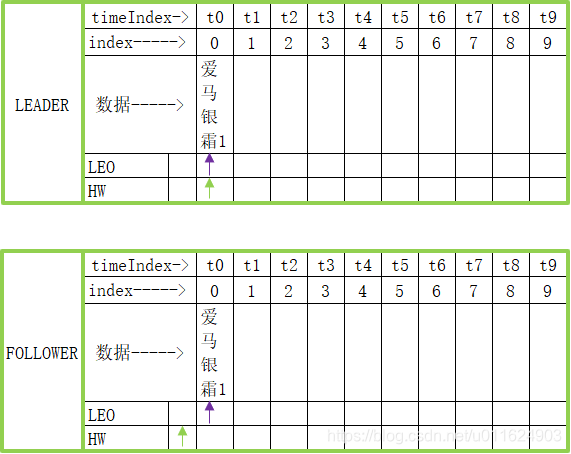
LEADER的HW表示所有同步最慢的那个副本已经同步到哪里了(但是本例只有一个follower)
LEO表示消费者可以读取到的最新数据位置
继续往这个partition中插入一条数据,数据的内容是"爱马银霜2",但是此时follower还没有同步数据
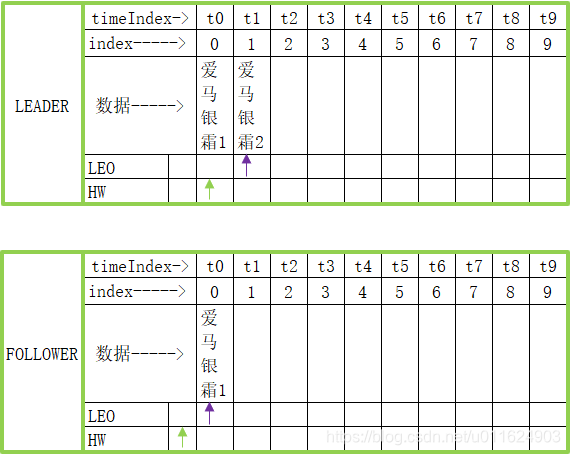
现在follower已经同步完毕数据,那么数据是下面这样的
上述两条数据的顺序不可更改
因为这台机器最多只能放10条数据,所以不能一直插入数据,那么势必要在某些情况下删除数据,才能保证新的数据可以正常插入
partition提供了两种删除策略
1.数据达到指定大小的时候删除
2.数据保留了一定时间之后再删除