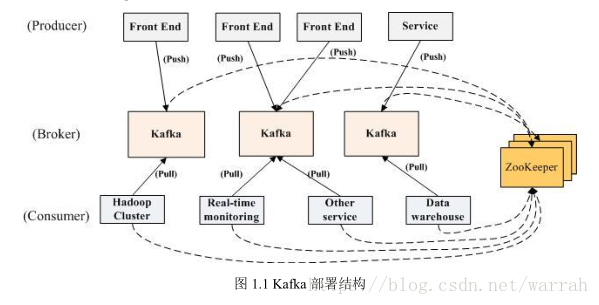
kafka是一个分布式(distributed)、分区(partioned)、复制(replicated)的提交日志服务。
kafka对消息保存时根据topic进行归类,发送消息为producer,消息接受者为consumer,在kafka集群中,kafka的实例成为broker(中间/代理人)
kafka集群用于处理来自各种不同来源的所有活动数据,同时为在线和离线数据使用者提供了一个单个数据通道,在线活动和异步处理之间形成了一个缓冲区,还可以将所有数据复制(replicate)到另外一个不同的数据中心去做离线处理。
1 一条消息只存储一次,如何降低重复消费
这里的前提条件是对一个topic而言,无论有多少使用者订阅了它,一条条消息都只会存储一次。
kafka不允许对消息进行“随机读写”,所以存取代价为O(1)。
由于Kafka与JMS不同的是:即使消息被消费,消息仍然不会被立即删除,那么如何保证不重复消费呢?
首先要明白consumer和producer状态信息,由zookeeper保存,对consumer而言,它需要保存消费消息的offset,offset也保存在zookeeper中。
接着了解kafka的消息传递机制,设计有三种at most once、at least once、exactly once,exactly once kafka并没有严格的去实现(基于2阶段提交,事务),而JMS实现消息传输担保采取的才是exactly once,故此就也是kafka的定位差别。kafka推荐首选方式是at least once,重复接收数据比丢失数据好。既然kafka采取了这种方式,那么是无法避免重复消费的。
这篇文章kafka重复消费问题给出了一个实际的例子,当consumer消费能力太低,就会造成重复消费的情况,因此kafka并不是用来做业务系统的消息队列。
由于一个partition中的消息只会被一个consumer消费,所以需要解决的不是重复消费的问题,而是提升partition的数量

2 分区数量
Partitions设计目的kafka是基于文件存储,每个partition在存储层面试append log文件,任何发布到此partition的消息都会被直接追加到log文件的尾部。
通过分区,可以将日志内容分散到多个server上,来避免文件尺寸达到单机磁盘的上限,每个partition都会被当前server(kafka实例)保存,可以将一个topic切分到任意多个partitions。越多的partitions意味着可以容纳更多的consumer,有效提升并发消费的能力。
那么如何确定分区的数量呢?
分区数 = Tt / max(Tp, Tc)
Tp表示producer的吞吐量。测试producer通常是很容易的,因为它的逻辑非常简单,就是直接发送消息到Kafka就好了。Tc表示consumer的吞吐量。测试Tc通常与应用的关系更大, 因为Tc的值取决于你拿到消息之后执行什么操作,因此Tc的测试通常也要麻烦一些。总的目标吞吐量是Tt
3 分区扩展
3.1 使用kafka-manager添加分区
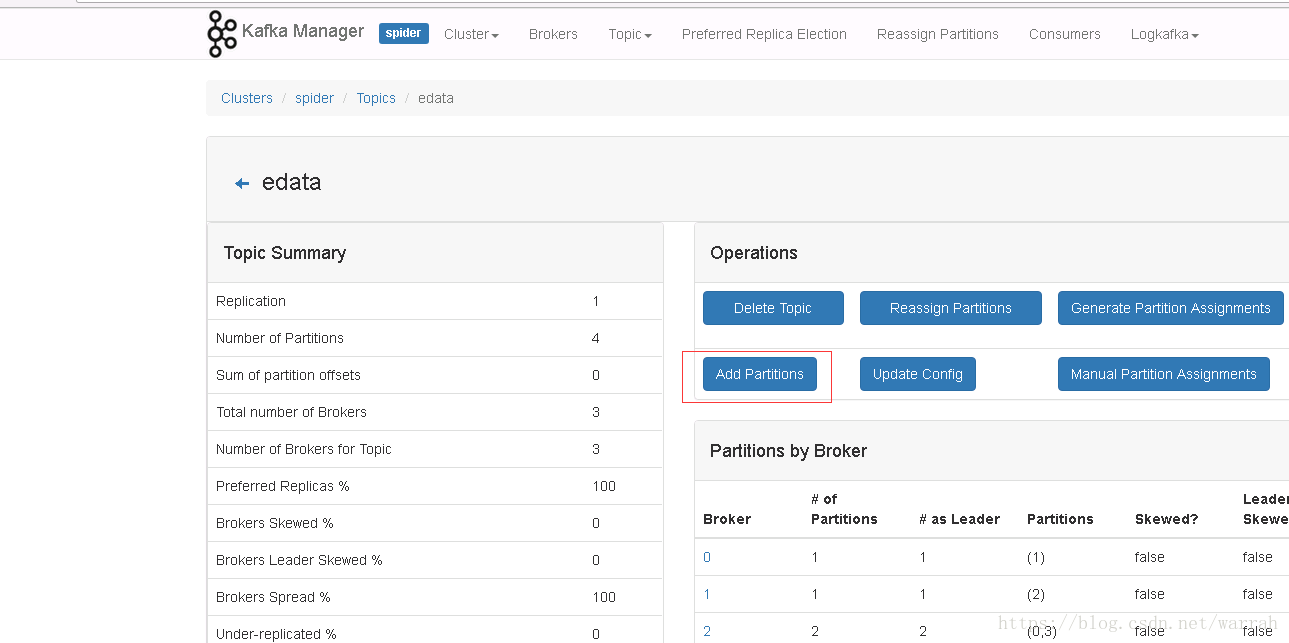
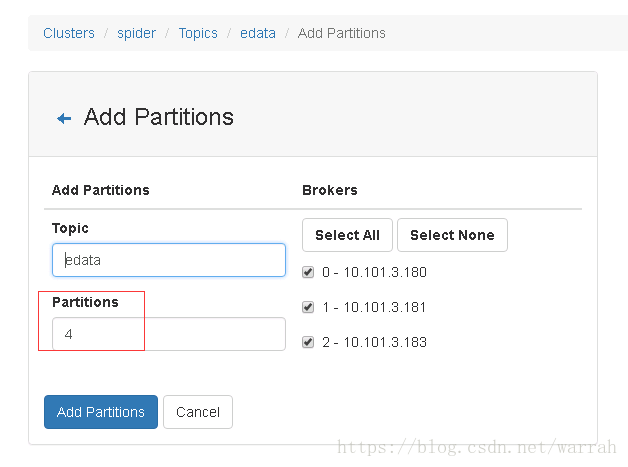
执行下面的名称,查看添加分区的结果
./kafka-topics.sh --zookeeper 10.101.3.177:2181,10.101.3.178:2181,10.101.3.179:2181 --topic edata --describe
3.2 通过命令添加分区
这里并不是实现kafka的扩容,只是想在原有的kafka中增加分区
执行下面的命令
./kafka-topics.sh --alter --zookeeper 10.101.3.177:2181,10.101.3.178:2181,10.101.3.179:2181 -partitions 6 --topic edata下图提示分区添加成功

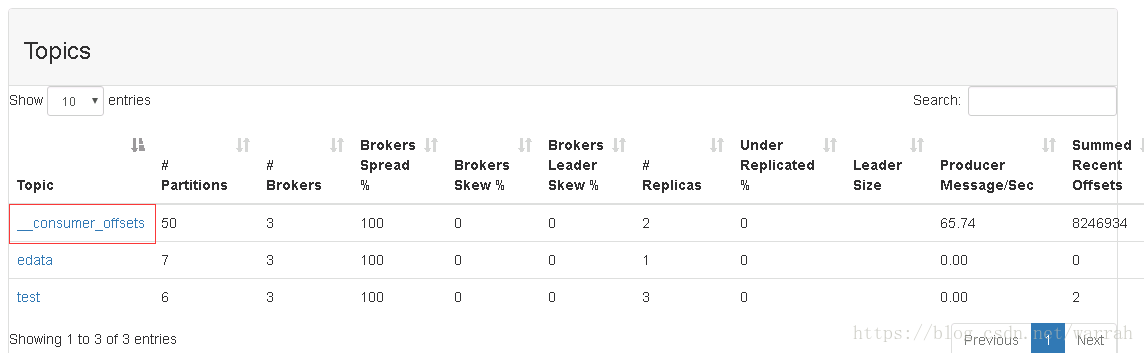
4 __consumer_offsets
启动kafka-manager,发现里面已经有一个topic,原因是由于Zookeeper并不适合大批量的频繁写入操作,新版Kafka已推荐将consumer的位移信息保存在Kafka内部的topic中,即__consumer_offsets topic
参考资料
虾皮工作室,《细细品味kafka——kafka简介及安装》精华集锦,2015.9.15
总结kafka的consumer消费能力很低的情况下的处理方案
Kafka 如何读取offset topic内容 (__consumer_offsets)