当我们的数据库占用空间过大时,经常会想到通过删除部分数据来释放空间,但往往操作完成后会发现表文件的大小并没有发生改变,这是为什么呢?
首先,来看一下数据删除的流程,之后再来分析这个问题产生的原因。
一.数据删除流程
我们知道,InnoDB 里的数据都是用 B+ 树的结构组织的,如下图所示:
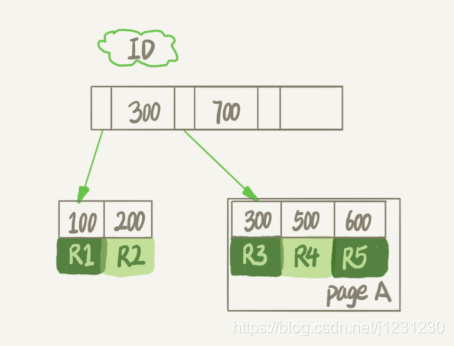
假设,我们要删掉 R4 这个记录,InnoDB 引擎只会把 R4 这个记录标记为删除。如果之后要再插入一个 ID 在 300 和 600 之间的记录时,可能会复用这个位置,但是,磁盘文件的大小并不会缩小。
而 InnoDB 的数据是按页存储的,对于数据页来说,如果我们删掉了一个数据页上的所有记录,整个数据页就可以被复用了。
此外,如果相邻的两个数据页利用率都很小,系统就会把这两个页上的数据合到其中一个页上,另外一个数据页就被标记为可复用了。
所以我们知道,如果用 delete 命令把整个表的数据都删除,那所有的数据页都会被标记为可复用,但是磁盘上,文件不会变小。这样看来,通过 delete 命令是不能回收表空间的。这些可以复用,而没有被使用的空间,看起来就像是“空洞”。
实际上,不止是删除数据会造成空洞,插入数据也会。
如果数据是按照索引递增顺序插入的,那么索引是紧凑的。但如果数据是随机插入的,就可能造成索引的数据页分裂,如下图所示:
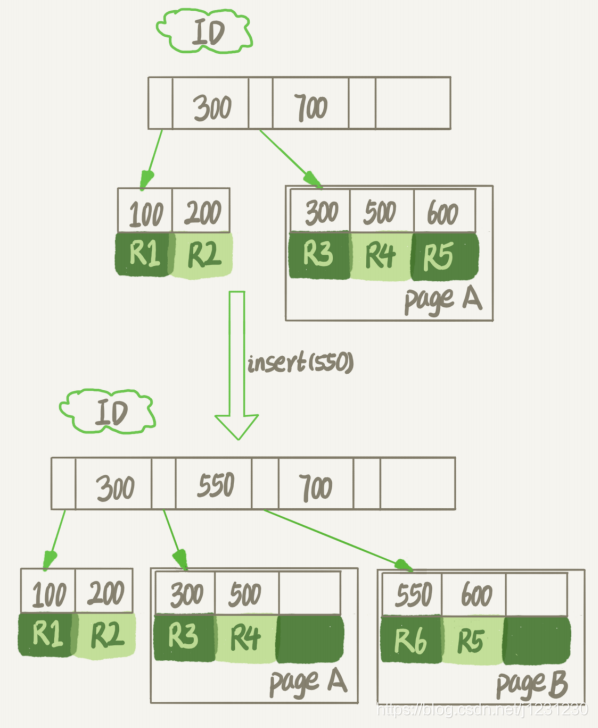
由于 page A 满了,再插入一个 ID 是 550 的数据时,就不得不再申请一个新的页面 page B 来保存数据了。页分裂完成后,page A 的末尾就留下了空洞。另外,更新索引上的值,可以理解为删除一个旧的值,再插入一个新值,这也是会造成空洞的。
也就是说,经过大量增删改的表,都是可能是存在空洞的。所以,如果能够把这些空洞去掉,就能对表空间进行收缩,我们可以通过重建表来达到这样的目的。
二.重建表
重建表主要分为以下四个方式:
1. 新建临时表导入数据
新建一个与表 A 结构相同的表 B,然后按照主键 ID 递增的顺序,把数据一行一行地从表 A 里读出来再插入到表 B 中。
由于表 B 是新建的表,所以表 A 主键索引上的空洞,在表 B 中就都不存在了。而且表 B 的主键索引更紧凑,数据页的利用率也更高。如果我们把表 B 作为临时表,数据从表 A 导入表 B 的操作完成后,用表 B 替换 A,从效果上看,就起到了收缩表 A 空间的作用。
2. 使用 alter 命令重建表
使用 alter table A engine=InnoDB 命令来重建表。在 MySQL 5.5 版本之前,这个命令的执行流程跟我们前面描述的差不多,区别只是这个临时表 B 不需要你自己创建,MySQL 会自动完成转存数据、交换表名、删除旧表的操作。具体流程如下所示:
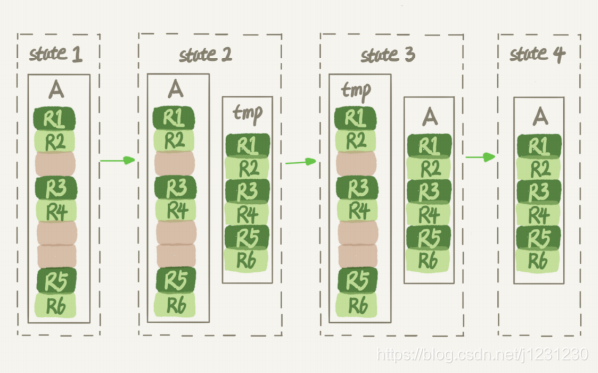
显然,花时间最多的步骤是往临时表插入数据的过程,如果在这个过程中,有新的数据要写入到表 A 的话,就会造成数据丢失。因此,在整个 DDL 过程中,表 A 中不能有更新。也就是说,这个 DDL 不是 Online 的。
3. 使用 Online DDL 重建表
使用 Online DDL 重建过程如下:
-
建立一个临时文件,扫描表 A 主键的所有数据页;
-
用数据页中表 A 的记录生成 B+ 树,存储到临时文件中;
-
生成临时文件的过程中,将所有对 A 的操作记录在一个日志文件(row log)中,对应的是图中 state2 的状态;
-
临时文件生成后,将日志文件中的操作应用到临时文件,得到一个逻辑数据上与表 A 相同的数据文件,对应的就是图中 state3 的状态;
-
用临时文件替换表 A 的数据文件。

可以看到,与图 3 过程的不同之处在于,由于日志文件记录和重放操作这个功能的存在,这个方案在重建表的过程中,允许对表 A 做增删改操作。这也就是 Online DDL 名字的来源。
上述的3种重建方法都会扫描原表数据和构建临时文件。对于很大的表来说,这个操作是很消耗 IO 和 CPU 资源的。因此,如果是线上服务,你要很小心地控制操作时间。如果想要比较安全的操作的话,推荐使用 GitHub 开源的 gh-ost 来做。
4. 使用 gh-ost 重建表
gh-ost 作为一个伪装的备库,可以从主库/备库上拉取 binlog,过滤之后重新应用到主库上去,相当于主库上的增量操作通过 binlog 又应用回主库本身,不过是应用在幽灵表上。
大致的工作流程如下:
- gh-ost 首先连接到主库上,根据 alter 语句创建幽灵表;
- 然后作为一个备库连接到其中一个真正的备库或者主库上(根据具体的参数来定),一边在主库上拷贝已有的数据到幽灵表,一边从备库上拉取增量数据的 binlog,然后不断的把 binlog 应用回主库。
- 等待全部数据同步完成,进行 cut-over 幽灵表和原表切换。也就是锁住主库的源表,等待 binlog 应用完毕,然后替换 gh-ost 表为源表。
gh-ost 在执行中,会在原本的 binlog event 里面增加 hint 和心跳包,用来控制整个流程的进度和检测状态等。当然 gh-ost 也会做很多前置的校验检查,比如 binlog_format,表的主键和唯一键,是否有外键等。
采用这种方式有很多好处,例如:
- 整个流程异步执行,对于源表的增量数据操作没有额外的开销,高峰期变更业务对性能影响小。
- 降低写压力,触发器操作都在一个事务内,gh-ost 应用 binlog 是另外一个连接在做。
- 可停止,binlog 有位点记录,如果变更过程发现主库性能受影响,可以立刻停止获取和应用 binlog,稳定之后再继续应用。
- 可测试,gh-ost 提供了测试功能,可以连接到一个备库上直接做 Online DDL,在备库上观察变更结果是否正确,再对主库操作,不过我们并不推荐在备库直接操作。