Linux基础优化方法(三)———字符集编码设置优化
一、什么是字符编码
- 字符编码(英语:Character encoding)也称字集码,是把字符集中的字符编码为指定集合中某一对象(例如:比特模式、自然数序列、8位组或者电脉冲),以便文本在计算机中存储和通过通信网络的传递。常见的例子包括将拉丁字母表编码成摩斯电码和ASCII。其中,ASCII将字母、数字和其它符号编号,并用7比特的二进制来表示这个整数。通常会额外使用一个扩充的比特,以便于以1个字节的方式存储。
- 在计算机技术发展的早期,如ASCII(1963年)和EBCDIC(1964年)这样的字符集逐渐成为标准。但这些字符集的局限很快就变得明显,于是人们开发了许多方法来扩展它们。对于支持包括东亚CJK字符家族在内的写作系统的要求能支持更大量的字符,并且需要一种系统而不是临时的方法实现这些字符的编码。
二、编码GB2312、GBK、UTF-8
- 早期时候,计算机编码是不能识别汉字的,对于我们中国这个频繁使用汉字的国家来说很不公平。 因此,出现了编码GB2312。
- GB2312 也是ANSI编码里的一种,对ANSI编码最初始的ASCII编码进行扩充,为了满足国内在计算机中使用汉字的需要,中国国家标准总局发布了一系列的汉字字符集国家标准编码,统称为GB码,或国标码。
- GBK即汉字内码扩展规范,K为扩展的汉语拼音中“扩”字的声母。英文全称Chinese Internal Code Specification。GBK编码标准兼容GB2312,共收录汉字21003个、符号883个,并提供1894个造字码位,简、繁体字融于一库。GB2312码是中华人民共和国国家汉字信息交换用编码,全称《信息交换用汉字编码字符集——基本集》,1980年由国家标准总局发布。基本集共收入汉字6763个和非汉字图形字符682个,通行于中国大陆。新加坡等地也使用此编码。GBK是对GB2312-80的扩展,也就是CP936字码表 (Code Page 936)的扩展(之前CP936和GB 2312-80一模一样)。
- Unicode编码:有一种编码,将世界上所有的符号都纳入其中,无论是英文、日文、还是中文等,大家都使用这个编码表,就不会出现编码不匹配现象。每个符号对应一个唯一的编码,乱码问题就不存在了。这就是Unicode编码。
- UTF-8编码: Unicode固然统一了编码方式,但是它的效率不高,为了提高Unicode的编码效率,于是就出现了UTF-8编码。UTF-8可以根据不同的符号自动选择编码的长短。比如英文字母可以只用1个字节就够了。
三、工作时有乱码的原因
- 系统字符集设置有问题
- 远程软件字符集设置有问题
- 文件编写字符集和系统查看字符集不统一(例如编写用UTF-8,查看欧诺个的是GBK)
四、进行优化
1、CentOS 6
①、查看默认编码信息:

②、临时修改编码信息:

③、永久修改:(两种方法都使用,系统优先选择第一种)
方法一:
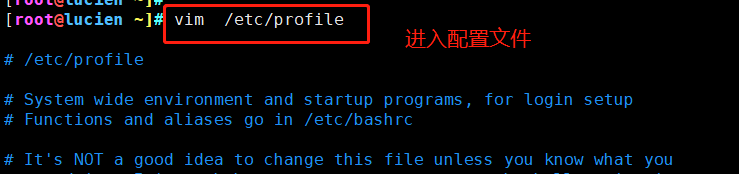

方法二:

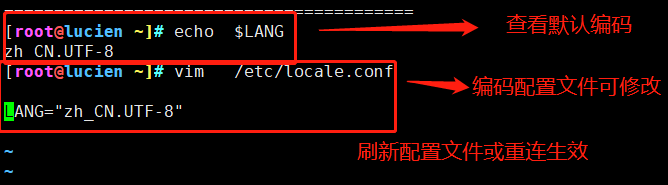
2、CentOS 7
①、查看默认编码信息:

②、临时修改编码信息:
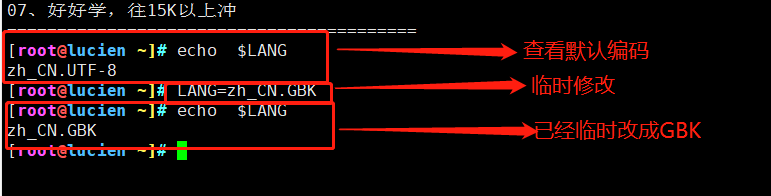
③、永久修改:(两种方法都使用,系统优先选择第一种)
方法一:
方法二: