问题一:hbase证件号+日期 又查询单条,有统计一天的量
需求:有一张数据表,其中包含手机号码字段。
1. 查询一段时间内固定号码的所有数据 2. 查询一段时间内所有数据。
分析:HBase要想查询快速,只能从rowKey上下手,
解决思路1:rowKey=phoneNum+时间 可以实现目标1,设置StartRow ;
在建立一个scan对象后,我们setStartRow(00000120120901),setEndRow(00000120120914)。
这样,scan时只扫描userID=000001的数据,且时间范围限定在这个指定的时间段内
但是目标2很难实现,RowFilter的SubstringComparator(子串匹配)话全表扫描,很慢,效率很低
rowKey=时间+phoneNum 可以实现目标2,但是目标1很难实现,
且数据量越来越大可能导致热点问题。
解决思路1:牺牲空间换时间,写数据时同时写入两张表,内容一样,只是一张表rowKey=phoneNum+时间,另一张表rowKey=时间+phoneNum。数据量太大,占用空间太大,浪费资源,不可取
解决思路2:牺牲部分空间部分时间,两张表,
一张全量表,rowKey=phoneNum+时间,
另一张索引表只存rowKey=时间+phoneNum,
目标1通过scan全量表就可以实现,目标2先scan索引表然后批量get全量表。
Hbase统计表总行数的三种方式
1. 使用HBase Shell自带的count命令统计:count 'hbase_table'
2. 使用HBase自带的MapReduce统计工具统计行数;
$HBASE_HOME/bin/hbase org.apache.hadoop.hbase.mapreduce.RowCounter
3. 使用Hive创建外表关联HBase数据表,然后使用SQL语句统计查询;
对于存在的hbase表,在hive中创建关联表,然后使用语句统计总行数 #select count(*) from Test;
CREATE EXTERNAL TABLE Test( mRID string, name string, nominalVoltage FLOAT )
ROW FORMAT SERDE'org.apache.hadoop.hive.hbase.HBaseSerDe'
STORED BY'org.apache.hadoop.hive.hbase.HBaseStorageHandler'
WITH SERDEPROPERTIES("hbase.columns.mapping" = ":key,pw:name,pw:nominalVoltage") TBLPROPERTIES("hbase.table.name"= "test");4. 使用 coprocessor 新特性:
5. scan方式设置过滤器循环计数
二、scan方式设置过滤器循环计数(JAVA实现)
这种方式是通过添加 FirstKeyOnlyFilter 过滤器的scan进行全表扫描,循环计数RowCount,速度较慢! 但快于第一种count方式!
public void rowCountByScanFilter(String tablename){
long rowCount = 0;
try {
//计时
StopWatch stopWatch = new StopWatch();
stopWatch.start();
TableName name=TableName.valueOf(tablename);
//connection为类静态变量
Table table = connection.getTable(name);
Scan scan = new Scan();
//FirstKeyOnlyFilter只会取得每行数据的第一个kv,提高count速度
scan.setFilter(new FirstKeyOnlyFilter());
ResultScanner rs = table.getScanner(scan);
for (Result result : rs) {
rowCount += result.size();
}
stopWatch.stop();
System.out.println("RowCount: " + rowCount);
System.out.println("统计耗时:" +stopWatch.getTotalTimeMillis());
} catch (Throwable e) {
e.printStackTrace();
}
}
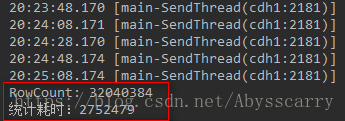
耗时45分钟!
四、利用HBase协处理器Coprocessor(JAVA实现)
这是我目前发现效率最高的RowCount统计方式,利用了HBase高级特性:协处理器!
我们往往使用过滤器来减少服务器端通过网络返回到客户端的数据量。但HBase中还有一些特性让用户甚至可以把一部分计算也移动到数据的存放端,那就是协处理器 (coprocessor)。
使用客户端API,配合筛选机制,例如,使用过滤器或限制列族的范围,都可以控制被返回到客户端的数据量。如果可以更进一步优化会更好,例如,数据的处理流程直接放到服务器端执行,然后仅返回一个小的处理结果集。这类似于一个小型的MapReduce框架,该框架将工作分发到整个集群。
协处理器 允许用户在region服务器上运行自己的代码,更准确地说是允许用户执行region级的操作,并且可以使用与RDBMS中触发器(trigger)类似的功能。在客户端,用户不用关心操作具体在哪里执行,HBase的分布式框架会帮助用户把这些工作变得透明。
Configuration conf = HBaseConfiguration.create();
HTable hTable = new HTable(conf, TableName.valueOf("T_REVIEW_MODULE"));
LongColumnInterpreter columnInterpreter = new LongColumnInterpreter();
AggregationClient aggregationClient = new AggregationClient(conf);
//Scan scan = new Scan( Bytes.toBytes("2018-07-01 12:12:12"), Bytes.toBytes("2018-07-27 12:12:12"));
Scan scan = new Scan(startRow, stopRow);
Long count = aggregationClient.rowCount(hTable, columnInterpreter, scan);实现代码:
public void rowCountByCoprocessor(String tablename){
try {
//提前创建connection和conf
Admin admin = connection.getAdmin();
TableName name=TableName.valueOf(tablename);
//先disable表,添加协处理器后再enable表
admin.disableTable(name);
HTableDescriptor descriptor = admin.getTableDescriptor(name);
String coprocessorClass = "org.apache.hadoop.hbase.coprocessor.AggregateImplementation";
if (! descriptor.hasCoprocessor(coprocessorClass)) {
descriptor.addCoprocessor(coprocessorClass);
}
admin.modifyTable(name, descriptor);
admin.enableTable(name);
//计时
StopWatch stopWatch = new StopWatch();
stopWatch.start();
Scan scan = new Scan();
AggregationClient aggregationClient = new AggregationClient(conf);
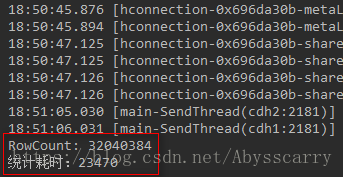
System.out.println("RowCount: " + aggregationClient.rowCount(name, new LongColumnInterpreter(), scan));
stopWatch.stop();
System.out.println("统计耗时:" +stopWatch.getTotalTimeMillis());
} catch (Throwable e) {
e.printStackTrace();
}
}
发现只花了 23秒 就统计完成!
为什么利用协处理器后速度会如此之快?
Table注册了Coprocessor之后,在执行AggregationClient的时候,会将RowCount分散到Table的每一个Region上,Region内RowCount的计算,是通过RPC执行调用接口,由Region对应的RegionServer执行InternalScanner进行的。
因此,性能的提升有两点原因:
1.分布式统计。将原来客户端按照Rowkey的范围单点进行扫描,然后统计的方式,换成了由所有Region所在RegionServer同时计算的过程。
2.使用了在RegionServer内部执行使用了InternalScanner。这是距离实际存储最近的Scanner接口,存取更加快捷。
二、hive中创建关联hbase表的几种方案
【运行环境】
hive-1.2.1 hbase-1.1.2
【需求背景】
有时候我们需要把已存在Hbase中的用户画像数据导到hive里面查询,也就是通过hive就能查到hbase里的数据。但是我又不想使用sqoop或者DataX等工具倒来倒去。这时候可以在hive中创建关联表的方式来查询hbase中的数据。
【创建关联表的几种方案】
前提是:hbase中已经存在了一张表。
可选的方案:既可以在hive中关联此表的所有列簇,也可以仅关联一个列簇,也可以关联单一列蔟下的单一列,还可以关联单一列簇下的多个列。
假设我在hbase中的 users 名称空间下面有一个表 china_mainland,此表的视图如下:
hbase(main):001:0> desc "users:china_mainland"
users:china_mainland, {TABLE_ATTRIBUTES => {METADATA => {'OWNER' => 'hbase'}}
COLUMN FAMILIES DESCRIPTION
{NAME => 'act', BLOOMFILTER => 'ROW', VERSIONS => '3', IN_MEMORY => 'false', KEEP_DELETED_CELLS => 'FALSE', DATA_BLOCK_ENCODING => 'NONE', TTL => 'FOREVER', COMPRESSION => 'SNAPPY', MIN_VERSIONS => '0', BLOCKCACHE => 'true', BLOCKSIZE => '65536', REPLICATION_SCOPE => '0'}
{NAME => 'basic', BLOOMFILTER => 'ROW', VERSIONS => '3', IN_MEMORY => 'false', KEEP_DELETED_CELLS => 'FALSE', DATA_BLOCK_ENCODING => 'NONE', TTL => 'FOREVER', COMPRESSION => 'SNAPPY', MIN_VERSIONS => '0', BLOCKCACHE => 'true', BLOCKSIZE => '65536', REPLICATION_SCOPE => '0'}
{NAME => 'docs', BLOOMFILTER => 'ROW', VERSIONS => '3', IN_MEMORY => 'false', KEEP_DELETED_CELLS => 'FALSE', DATA_BLOCK_ENCODING => 'NONE', TTL => 'FOREVER', COMPRESSION => 'SNAPPY', MIN_VERSIONS => '0', BLOCKCACHE => 'true', BLOCKSIZE => '65536', REPLICATION_SCOPE => '0'}
{NAME => 'pref', BLOOMFILTER => 'ROW', VERSIONS => '3', IN_MEMORY => 'false', KEEP_DELETED_CELLS => 'FALSE', DATA_BLOCK_ENCODING => 'NONE', TTL => 'FOREVER', COMPRESSION => 'SNAPPY', MIN_VERSIONS => '0', BLOCKCACHE => 'true', BLOCKSIZE => '65536', REPLICATION_SCOPE => '0'}
{NAME => 'rc', BLOOMFILTER => 'ROW', VERSIONS => '3', IN_MEMORY => 'false', KEEP_DELETED_CELLS => 'FALSE', DATA_BLOCK_ENCODING => 'NONE', TTL => 'FOREVER', COMPRESSION => 'SNAPPY', MIN_VERSIONS => '0', BLOCKCACHE => 'true', BLOCKSIZE => '65536', REPLICATION_SCOPE => '0'}
5 row(s) in 0.2430 seconds可以看到有5个列簇。我的列簇个数太多了,应该控制在3个列簇以内的,这个问题今后再说吧,计划是按照每个列簇分别拆分成不同的表吧,不然读写性能会随着数据量的增长而下降得很厉害。
下面演示如何在hive中创建外部表,注意:不能使用load data加载数据到这个hive的外部表,因为外部表是使用HBaseStorageHandler创建的。但是内部表就可以load data。
【方案一】创建一个hive外表,使其与hbase中的china_mainland表的所有列簇映射(包括每个列簇下的所有列)
注意这里的关键步骤是在建表的时候,在WITH SERDEPROPERTIES指定关联到hbase表的哪个列簇或列!
hive>
CREATE EXTERNAL TABLE china_mainland(
rowkey string,
act map<STRING,FLOAT>,
basic map<STRING,FLOAT>,
docs map<STRING,FLOAT>,
pref map<STRING,FLOAT>,
rc map<STRING,FLOAT>
) STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler'
WITH SERDEPROPERTIES ("hbase.columns.mapping" = ":key,act:,basic:,docs:,pref:,rc:")
TBLPROPERTIES ("hbase.table.name" = "users:china_mainland")
;【方案二】与单一列簇下的单个列映射
hive表china_mainland_acturl中的2个字段rowkey、act_url分别映射到Hbase表users:china_mainland中的行健和“act列簇下的一个url列”
hive>
CREATE EXTERNAL TABLE china_mainland_acturl(
rowkey string,
act_url STRING
) STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler'
WITH SERDEPROPERTIES ("hbase.columns.mapping" = ":key,act:url")
TBLPROPERTIES ("hbase.table.name" = "users:china_mainland")
;【方案三】与单一列簇下的多个列映射
hive表china_mainland_kylin_test中的3个字段pp_professionact、pp_salary、pp_gender,分别映射到Hbase表users:china_mainland中的列簇act下的3个列pp_profession、pp_salary、pp_gender
hive>
CREATE EXTERNAL TABLE china_mainland_kylin_test(
rowkey string,
pp_profession string,
pp_salary double,
pp_gender int)
STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler'
WITH SERDEPROPERTIES ("hbase.columns.mapping" =":key,act:pp_profession,act:pp_salary,act:pp_gender")
TBLPROPERTIES ("hbase.table.name" = "users:china_mainland");【方案四】
关联到hbase表的单一列簇下的所有列
hive>
CREATE EXTERNAL TABLE china_mainland_pref(
rowkey STRING,
pref map<STRING, STRING>
)
STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler'
WITH SERDEPROPERTIES ("hbase.columns.mapping" = ":key,pref:")
TBLPROPERTIES ("hbase.table.name" = "users:china_mainland")
;hive> DESC FORMATTED china_mainland_pref;
OK
# col_name data_type comment
rowkey string from deserializer
pref map<string,string> from deserializer
# Detailed Table Information
Database: lmy_test
Owner: hive
CreateTime: Thu May 03 15:12:32 CST 2018
LastAccessTime: UNKNOWN
Protect Mode: None
Retention: 0
Location: hdfs://ks-hdfs/apps/hive/warehouse/tony_test.db/china_mainland_pref
Table Type: EXTERNAL_TABLE
Table Parameters:
COLUMN_STATS_ACCURATE{\"BASIC_STATS\":\"true\"}
EXTERNAL TRUE
hbase.table.name users:china_mainland
numFiles 0
numRows 0
rawDataSize 0
storage_handler org.apache.hadoop.hive.hbase.HBaseStorageHandler
totalSize 0
transient_lastDdlTime1525331552
# Storage Information
SerDe Library: org.apache.hadoop.hive.hbase.HBaseSerDe
InputFormat: null
OutputFormat: null
Compressed: No
Num Buckets: -1
Bucket Columns: []
Sort Columns: []
Storage Desc Params:
hbase.columns.mapping:key,pref:
serialization.format1
Time taken: 0.165 seconds, Fetched: 36 row(s)
建好china_mainland_pref以后,马上就能用了——
# 查看前几条
hive> SELECT * FROM china_mainland_pref LIMIT 5;
OK
P_0 {"preference_game":"2","preference_shopping":"29"}
P_00 {"preference_news":"2","preference_shopping":"3","preference_travel":"2"}
P_0000001876382F627351AA1353507E7E {"preference_news":"1","preference_science":"9","preference_shopping":"2","profession_communication":"1","train_collegeexam":"8","train_postgraduexam":"1"}
P_00000050B563527DE611805C3513BFCF {"preference_news":"2","preference_shopping":"68","preference_sns":"2","title_doc2vec_vector":"[-0.029652609855638477, 0.16829780398795727, 0.0634797563895506, 0.09985980261821016, -0.027206807371619682, 0.04609297546347725, 0.22684986310548136, 0.07509010726482222, -0.35608007793539426, 0.17766480221945294, 0.46286574267486735, 0.2597907394226127, -0.14725957574341025, 0.07262948642247423, 0.07125068438490716, 0.19818145833107004, -0.11506854374877365, 0.22868833573045896, -0.43365914508786096, -0.3630766762536705]"}
P_00000051992B3C6B48DF65CFCD00F570 {"preference_automobile":"2","preference_entertainment":"3","preference_financial":"2","preference_game":"2","preference_house":"1","preference_maternal":"2","preference_medcine":"2","preference_news":"1043","preference_science":"1","preference_shopping":"153","preference_sns":"1","preference_sport":"11","preference_travel":"1","profession_Agriculture":"9","profession_appliance":"1","profession_building":"4","profession_businesstrade":"4","profession_electronic":"1","profession_food":"11","profession_logistics":"14","profession_metallurgy":"4","profession_otherindustry":"2","shopping_frequence":"0:7 11:0.286 14:0.143 15:0.143 19:0.143 20:0.143 21:0.143 25:0.571 29:0.143 30:0.286","title_doc2vec_vector":"[-0.24758818000253893, 0.2338153449865942, -0.05848859099970545, -0.02417380306100351, 0.14515214525269712, 0.30990456699703955, -0.09866324401812501, -0.2331386034898917, -0.33209567698858355, 0.07699443458979872, 0.1471409695212827, 0.45493278257739733, 0.3085450975389932, -0.32623349923656875, -0.13339757411540565, -0.05206131438941852, 0.1003091645774786, 0.24435056196480162, -0.15905020331297162, -0.19182652834852418]","train_postgraduexam":"1"}
Time taken: 0.385 seconds, Fetched: 5 row(s)
# 查询此表的总记录数
hive> select count(rowkey) from china_mainland_pref;
OK
851887471
Time taken: 1080.993 seconds, Fetched: 1 row(s)