第二章
排序问题
Problem 1

以此处为例,假如我们采用冒泡排序来完成此题,我们应该注意到冒泡排序的时间复杂度为O(待排序个数的平方),在此例中即O(n2)。而n的取值范围也在题面中明确地给出(1<=n<=100),这样我们可以估算出n2的数量级仅在万级别,其时间复杂度并没有超过百万数量级复杂度,所以使用冒泡排序在该例限定的一秒运行时间里是完全可以接受的;同时冒泡排序的空间复杂度为O(n),即大致需要100* 32bit (数组长度*int 所占内存)的内存,这样,所需的内存也不会超过该例限定的内存大小(32 兆)。只有经过这样的复杂度分析,我们才能真正确定冒泡排序符合我们的要求。
#include <stdio. h>
int main(){
int n
int buf[100]; //定义我们将要使用的变量n,并用buf[100]来保存将要排序的数字
while (scanf ("%d",&n) != EOF) {
//输入n, 并实现多组数据的输入
//若输入为字符串而程序采用gets()的方法读入,则相同功能的循环判断语句为while(gets(字符串变量))
for(int i=0;i<n;i++){
scanf ("%d",&buf[i]);
} //输入待排序数字
for(int i=0;i<n;i++){
for(int j=0:j<n-1-i;j++){
if (buf[j] > buf[j + 1]) {
int tmp = buf[j];
buf[j] = buf[j + 1];
buf[j + 1] = tmp;
}
}
} //冒泡排序主体
for(int i=0;i<n;i++){
printf("%d",buf[1]);
}//输出完成排序后的数字,注意题面输出要求在每个数字后都添加一个空格
printf("\n"); //输出 换行
return 0;
}
冒泡排序因其较高的时间复杂度(O (10000 * 10000)已经超过了 百万数量级)而不能再被我们采用,于是我们不得不使用诸如快速排序、归并排序等具有更优复杂度的排序算法。那么,新问题出现了,恐怕大部分读者都对此感到恐惧:是否能正确的写出快速排序、归并排序等的程序代码? C++已经为我们编写了快速排序库函数,我们只需调用该函数,便能轻易的完成快速排序。
C++ 头文件algorithm中的sort函数,当规模较大时为快速排序,规模较小时采用其他排序方式
#include <stdio.h>
#include <algorithm>
using namespace std;
int main(){
int n;
int buf[10000];
while (scanf("%d",&n) != EOF) {
for(int i=0;i<n;i++){
scanf("%d",&buf[i]);
}
sort(buf,buf+n);//使用该重载形式,表明将要使用自己定义的排列规则
for(int i=0;1<n;i++){
printf("%d ",buf[i]);
}
printf("\n");
}
return 0;
}
若使用sort函数的方法来完成降序排列,如该代码所示,我们新定义了一个cmp函数,来实现对于新的排序规则的定义。对于利用sort函数为其它基本类型(如double, char ,结构体等)排序的方法也大同小异。
#include <stdio.h>
#include <algorithm>
using namespace std;
bool cmp(int x,int y) {
//定义排序规则
return x > y;
}
int main(){
int n;
int buf[10000];
while (scanf("%d",&n) != EOF) {
for(int i=0;i<n;i++){
scanf("%d",&buf[i]);
}
sort(buf,buf+n,cmp);//使用该重载形式,表明将要使用自己定义的排列规则
for(int i=0;1<n;i++){
printf("%d ",buf[i]);
}
printf("\n");
}
return 0;
}
Problem 2

使用sort函数。由于自己定义了一个结构体,并不属于C++的内置基本类型,计算机并不知道两个结构体之间的如何比较大小,更不可能自动对其进行排序。于是要做的即是向计算机说明该排序依据。但是不要忘记,将sort的第三个参数设定为cmp函数,使sort函数知道该应用什么规则对其进行定序。
#include <stdio.h>
#include <algorithm>
#include <string.h>
using namespace std;
struct E{
char name[101];
int age;
int score;
}buf[1000];
bool cmp(E a,E b) {
//实现比较规则
if (a.score != b.score) return a.score < b.score; //若分数不相同则分数低者在前
int tmp = strcmp(a.name,b.name);
if (tmp != 0) return tmp < 0; //若分数相同则名字字典序小者在前
//返回值小于 0,则表示a.name小于b.name。
else return a.age < b.age; //若名字也相同则年龄小者在前
}
int main(){
int n;
while (scanf("%d",&n) != EOF) {
for(int i=0;i<n;i++){
scanf("%s%d%d",buf[i].name, &buf[i].age, &buf[i].score);
}//输入
sort(buf,buf + n,cmp): //利用自己定义的规则对数组进行排序
for(int i=0;i<n;i++){
printf("%s %d %d\n",buf[i].name,buf[i].age,buf[i].score);
} //输出排序后结果
}
return 0;
}
同样的,与编写cmp类似,可以直接定义该结构体的小于运算符来说明排序规则。由于已经指明了结构体的小于运算符,计算机便知道了该结构体的定序规则(sort函数只利用小于运算符来定序,小者在前)。于是,我们在调用sort 时,便不必特别指明排序规则(即不使用第三个参数),只需说明排序起始位置和结束位置即可。虽然,该方法与定义cmp函数的方法类似,书中还是建议使用第二种方法。
#include <stdio.h>
#include <algorithm>
#include <string.h>
using namespace std;
struct E {
char name[101];
int age;
int score;
bool operator < (const E &b) const {
//利用C++算符重载直接定文小于运算符
if (score != b.score) return score < b.score;
int tmp = strcmp(name, b.name);
if (tmp != 0) return tmp < 0;
else return age < b.age;
}
}buf[1000];
int main(){
int n;
while (scanf("%d",&n) != EOF) {
for(int i=0;i<n;i++){
scanf("%s%d%d",buf[i].name,&buf[i].age,&buf[i].score);
}
sort(buf, buf + n);
for(int i=0;i<n;i++){
printf("%s %d %d\n", buf[i].name, buf[i].age,buf[i].score);
}
}
return 0;
}
日期类问题
Problem 1


该例题考察了日期类问题中最基本的问题一求两个日期间的天数差,即求分别以两个特定日期为界的日期区间的长度。这里值得一提的是,解决这类区间问题有一个统一的思想一把原区间问题统一到起点确定的区间问题 上去。在该例中,我们不妨把问题统一到特定日期与一个原点时间(如0000年 1月1日)的天数差,当要求两个特定的日期之间的天数差时,我们只要将它们与原点日期的天数差相减,便能得到这两个特定日期之间的天数差(必要时加绝对值)。这样做有一个巨大的好处----预处理。 我们可以在程序真正开始处理输入数据之前,预处理出所有日期与原点日期之间的天数差并保存起来。当数据真正开始输入时,我们只需要用O (1)的时间复杂度将保存的数据读出,稍加处理便能得到答案。值得一提的是,预处理也是空间换时间的重要手段(保存预处理所得数据所需的内存来换取实时处理所需要的时间消耗)。
另外,日期类问题有一个特别需要注意的要点-----闰年,我们必须明确闰年的判断规则-----当年数不能被100整除时若其能被4整除则为闰年,或者其能被400整除时也是闰年。用逻辑语言表达出来即为Year%100!=0&&Year%4 == 0|| Year % 400 = 0。
#include <stdio.h>
#define ISYEAP(x) x%100!=0&&x%4==0||x%400==0?1:0
//定义宏判断是否是闰年,方便计算每月天数
int dayOfMonth[13][2] = {
0, 0,
31, 31,
28, 29,
31, 31,
30, 30,
31, 31,
30, 30,
31, 31,
31, 31,
30, 30,
31, 31,
30, 30,
31, 31
}; //预存每月的天数,注意二月配合宏定义作特殊处理
struct Date {
//日期类,方便日期的推移
int Day;
int Month;
int Year;
void nextDay(){
//计算下一天的日期
Day++;
if (Day > dayOfMonth[Month][ISYEAP(Year)]) {
//若日数超过了当月最大日数
Day = 1:
Month ++;//进入下一月
if (Month > 12) {
//月数超过12
Month = 1;
Year ++; //进入下一年
}
}
}
};
int buf[5001][13][32];//保存预处理的天数
int Abs(int x) {
//求绝对值
return x<0?-x:x;
}
int main () {
Date tmp;
int cnt = 0; //天数计数
tmp.Day = 1;
tmp.Month = 1;
tmp.Year = 0; //初始化日期类对象为0年1月1日
while(tmp.Year != 5001) {
//日期不超过5000年
buf[tmp.Year][tmp.Month][tmp.Day] = cnt; //将该日与0年1月1日的天数差保存起来
tmp.nextDay(); //计算下一天日期
cnt++; //计数器累加,每经过一天计数器即+1,代表与原点日期的间隔又增加一天
}
int d1,m1,y1;
int d2,m2,y2;
while(scanf("%4d%2d%2d",&y1,&m1,&d1) != EOF) {
//利用在%d之间插入数字来读取特定位数的数字,它为处理输入带来了极大的便利
scanf("%4d%2d%2d",&y2,&m2,&d2);//读入要计算的两个日期
printf("%d\n",Abs(buf[y2][m2][d2]-buf[y1][m1][d1]) + 1);//用预处理的数据计算两日期差值,注意雷对其求绝对值
}
return 0;
}
将buf[5001][13][32]这个相对比较耗费内存的数组定义成全局变量,这不是偶然的。由于需要耗费大量的内存,若在main函数(其它函数也一样)之中定义该数组,其函数所可以使用的栈空间将不足以提供如此庞大的内存,出现栈溢出,导致程序异常终止。所以,今后凡是涉及此类需要开辟大量内存空间的情况,都必须在函数体外定义,即定义为全局变量。或者在函数中使用malloc等函数动态申请变量空间。读者必须牢记这一点。
注意:在C语言中struct结构体里面 不能定义函数,c++里可以在结构体内定义函数。
Problem 2


#include <stdio.h>
#include <string.h>
#define ISYEAP(x) x%100!=0&&x%4==0||x%400==0?1:0
//定义宏判断是否是闰年,方便计算每月天数
int dayOfMonth[13][2] = {
0, 0,
31, 31,
28, 29,
31, 31,
30, 30,
31, 31,
30, 30,
31, 31,
31, 31,
30, 30,
31, 31,
30, 30,
31, 31
}; //预存每月的天数,注意二月配合宏定义作特殊处理
struct Date {
//日期类,方便日期的推移
int Day;
int Month;
int Year;
void nextDay(){
//计算下一天的日期
Day++;
if (Day > dayOfMonth[Month][ISYEAP(Year)]) {
//若日数超过了当月最大日数
Day = 1;
Month ++;//进入下一月
if (Month > 12) {
//月数超过12
Month = 1;
Year ++; //进入下一年
}
}
}
};
int buf[5001][13][32];//保存预处理的天数
char monthname[13][20]={
"",
"January",
"February",
"March",
"April",
"May",
"June",
"July",
"August",
"September",
"October",
"November",
"December"
}; //月名每个月名对应下标1到12
char weekName[7][20] = {
"Sunday",
"Monday",
"Tuesday",
"Wednesday",
"Thursday",
"Friday",
"Saturday"
}; //周名每个周名对应下标0到6
int main(){
Date tmp;
int cnt = 0;
tmp.Day = 1;
tmp.Month = 1;
tmp.Year = 1000;
while(tmp.Year != 3001) {
buf[tmp.Year][tmp.Month][tmp.Day] = cnt;
tmp.nextDay();
cnt++;
} //以上与上题一致,预处理出每一一天与原点日期的天数差
int d,m,y;
char s[20];
while (scanf("%d%s%d",&d,s,&y) != EOF) {
for(m=1;m<=12;m++){
if (strcmp(s,monthName[m]) == 0) {
break; //将输入字符串与月名比较得出月数,即在monthName中的下标
}
}
int days = buf[y][m][d] - buf[2020][4][4]; //计算给定日期与今日日期的天数问隔(注意可能为负)
days+=6; //今天(2020.4.4)为星期六,对应数组下标为6,则计算6经过days天后的下标
puts(weekName[(days % 7 + 7) % 7]);//将计算后得出的下标用7对其取模。并且保证其为非负数。则读下标即为答案所对应的下标,输出即可。
}
return 0;
}
这里顺便可以提一句,计算星期几问题存在着公式解法:蔡勒(Zeller)公式。但是该公式比较复杂,完全记忆需要一定的时间,有兴趣读者可以查阅相关资料。

Hash的应用
相信各位读者对上一节中,将一个日期对应的预处理數据存储在一个以该日期的年月日为下标的三维数组中还有印象。这种将存储位置与数据本身对应起来的存储手段就是Hash。 与以往不同的是,本节所讨论的Hash旨在讲述其在机试试题解答中的作用,而不像《数据结构》教科书上,对各种Hash方法、冲突处理做过多的阐述。
Problem 1
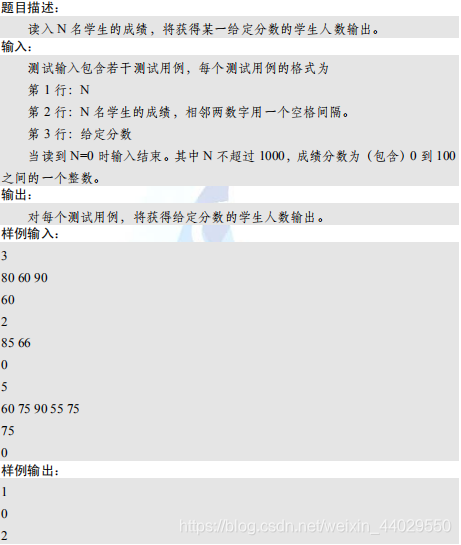
初见此题,读者可能可以一下于想到非常多的方法来解决此题。但是我们这里还是指出使用Hash解决此类问题不失为一种好的办法。在开始具体解题之前,我们要注意这类问题存在的一个共同特点:输入的分数种类是有限的。在此例中,可以看到,输入的分数不仅严格在0到100的区间之内,同时它又一定是一个整数。这样,输入的数据一共只有101种可能,只要为这101种可能分别计数,便能在输入结束时便得知每一种分数的重复情况。
#include <stdio.h>
int main(){
int n;
while (scanf ("%d",&n) != EOF && n != 0) {
//输入判断增加对n是否等于零进行判断
int Hash[101] = {
0}; //建立一个初始为0的Hash数组用来记录各种分数出现的次
for(int i=1;i<=n;i++){
int x;
scanf("%d",&x);
Hash[x] ++; //统计分数出现次数
}
int x;
scanf ("%d",&x);
printf("%d\n",Hash[x]); //得到需要查询的目标分数后,只需简单的查询我们统计的数量即可
}
return 0;
}
Problem 2

容易联想到,要输出前m大的数,只需将其降序排序,然后输出前m个数即可。在前几例中并没有着重分析算法的复杂度,但这不代表复杂度分析在我们解题的过程中不那么重要,相反复杂度分析是一个算法可行的前提与保证。即使本文没有明确的分析复杂度,读者也要有自己估算复杂度的意识。在本例中,如果使用排序来解决该题,由于待排序数字的数量十分庞大( 1000000),即使使用时间复杂度为O (nlogn) 的快速排序,其时间复杂度也会达到千万数量级,而这在一秒时限内是不能被所接受的,所以这里并不能使用快速排序来解决本题。
有了上例的启发,读者应该很快就能注意到,本例与上例有一个共同的特点:输入数量的有限性。该例题面限定了输入的数字一定是[-500000,500000]区间里的整数,且各不相同。若利用一个数组分别统计每一种数字是否出现,其空间复杂度依旧在题目的限定范围内。且统计出现数字当中较大的m个数字,也仅需要从尾至头遍历这个数组,其时间复杂度仍在百万数量级,所以该解法是符合要求的。
#include <stdio.h>
#define OFFSET 500000 //偏移量,用于补偿实际数字与数组下标之问偏移
int Hash[1000001]; //Hash数组,记录每个数字是否出现,不出现为0,出现后被标记成1
int main(){
int n,m;
while (scanf("%d%d",&n,&m) != EOF) {
for(int i=-500000;i<=500000;i++) {
Hash[i + OFFSET] = 0;
} //初始化,将每个数字都标记为未出现
for(int i=1;i<=n;i++){
int x;
scanf("%d",&x);
Hash[x + OFFSET] = 1;//凡是 出现过的数字,该数组元素均被设置成1
}
for (int i = 500000;i>=-500000;i--) {
//输出前m个数
if (Hash[i + OFFSET] == 1) {
//若该数字在输入中出现
printf("%d",i); //输出该数字
m--; //输出一个数字后,m减一,直至m麦为0
if (m != 0) printf(" ");//注意格式,者m个数未被输出完毕,在输出的数字后紧跟一个空格
else {
printf("\n"); //若m个数字已经被输出完毕,则在输出的数字后面紧跟一个换行,并跳出遍历循环
break;
}
}
}
}
return 0;
}
排版题
考察对于输出格式的把握
Problem 1


该题有规律可循,较为简单。
#include<stdio.h>
int main(){
int h;
while (scanf ("%d",&h) != EOF) {
int maxLine = h+ (h-1)*2; //计算最后一行包含的星号个数
for (int i=1;i<=h;i++) {
//依次输出每行信息
for (int j=1;j<=maxLine;j++) {
//依次输出每行当中的空格成星号
if(Q<maxLine-h-(i-1)*2+1) //输出空格
printf(" ");
else //输出星号
printf("");
}
printf("n"); //输出换行
}
}
return 0;
}
Problem 2


如此例所示,其输出图形的规律性主要体现在由内而外的各个环上,而这与我们的输出顺序又不太契合(从上至下,从左至右),不容易将该图形存在的规律直接应用到输出当中,所以需要使用刚才所提到的办法一一先排版后输出。并在排版(而不是输出)时利用我们观察到的“环形规律”完成排版。如下代码:
#include <stdio. h>
int main(){
int outPutBuf[82][82]; //用于预排版的输出缓存
char a,b; //输入的两个字符
int n; //叠框大小
bool firstCase = true; //是否为第一组数据标志,初始值为true
while (scanf ("%d %c %c",&n,&a,&b) == 3) {
if (firstCase == true) {
//若是第一组数据
firstCase = false; //将第一组数据标志标记成false
}
else printf("\n"); //否则输出换行
for (int i=1,j=1;i<=n;i+=2,j++) {
//从里至外输出每个圈
//i表示第j圈的边长
//首先明确该圈使用哪一个字符来填充,使用判断循环次数指示变量j的奇偶性来判断当前需要使用的字符
int x=n/2+1,y=x;//中间圈
x-=j-1;y-=j-1; //计算每个圈左上角点的坐标,以其为基准
char c=j%2==1?a:b; //计算当前圈需要使用哪个字符
//奇数圈使用第一个,偶数圈使用第二个
for(int k=1;k<=i;k++){
//对当前圈进行赋值
outPutBuf[x + k - 1][y] = c; //左边赋值
outPutBuf[x][y + k - 1] = c; //上边赋值
outPutBuf[x + i - 1][y + k-1] = c; //右边赋值
outPutBuf[x + k - 1][y + i-1] = c; //下边赋值
}
}
if(n!=1){
//注意当n为1时不需此步骤
outPutBuf[1][1] =' ';
outPutBuf[n][1] =' ';
outPutBuf[1][n] =' ';
outPutBuf[n][n] =' ';//将四角置为空格
}
for(int i=1;i<=n;i++){
for(int j=1;j<=n;j++){
printf("%c",outPutBuf[i][j]);
}
printf("\n");
} //输出已经经过排版的在输出缓存中的数据
}
return 0;
}
查找问题
Problem 1

代码很简单,如下。
#include <stdio.h>
int main(){
int buf[200];
int n;
while (scanf("%d",&n) != EOF) {
for(int i=0;i<n;i++){
scanf("%d",&buf[i]);
}
int x,ans = -1; //初始化答案为-1,在找不到答案时能正确的输出-1
scanf ("%d",&x);
for (int i = 0;i < n;i++) {
//依次遍历数组元素
if (x == buf[i]) {
//目标数字与数组元素依次比较
ans = i;
break;
}
}
printf("%d\n",ans);
}
return 0;
}
二分查找是一种常有策略性的、跳跃的方法来遍历查找空间。二分查找建立在待查找元素排列有序的前提上。例如在一个升序有序的长度为L的数组中查询某元素。时间复杂度可由原本线性查找的O(L)降低到O(logL)。以下二分查找部分代码:
//存在一个升序有序的数组buf,其大小为size,目标数字为target
int base = 0, top = size; //初始情况与二分查找一致
while (base <= top) {
//二分循环条件与二分查找一致
int mid=(base+top)/2;
if (buf[mid] <= target) base = mid + 1; //符合前一部分数字规定
else top = mid - 1; //否则
)
int ans = top; //最后,top即为我们要求的数字数组下标,buf[top]为该数字本身
Problem 2


若我们依旧采用每次询问时线性遍历数组来查找是否存在我们需要查找的元素,那么,该算法的时间复杂度达到了O (n*m) (查找次数中每次查找所需比较的个数),达到了千万数量级。于是,使用二分查找。为了符合查找空间单调有序的要求,首先要对所有数组元素按照学号关键字升序排列。当数组内各元素已经升序有序时,就可以在每次询问某个特定学号的学生是否存在时,使用二分查找来查找该学生。
#include <stdio.h>
#include <algorithm>
#include <string.h>
using namespace std;
struct Student{
//用于表示学生个体的结构体
char no[100];//学号
char nane[100]; //姓名
int age; //年龄
char sex[5]; //性别
bool operator < (const Student &A) const {
//重载小于运算符使其能使用sort函数排序
return strcmp(no,A.no) < 0;
}
}buf[1000];
int main(){
int n;
while (scanf("%d",&n) != EOF) {
for(int i=0;i<n;i++){
scanf("%s%s%s%d",buf[i].no,buf[i].name,buf[i].sex,&buf[i].age);
}
sort(buf,buf + n): //对数组排序使其按照学号升序排列
int t;
scanf ("%d",&t);//有t组询问
while (t--!= 0) {
//while循环保证查询次数为t
int ans = -1;//目标元素下标,初始化为-1
char x[30];
scanf ("%s",x); //待查找学号
int top=n-1,base=0; //初试时,开始下标0,结束下标n-1.查找子集为整个数组
while(top >= base){
//当查找子集不为空集时重复二分查找
int mid=(top+base)/2;//计算中间点下标
int tmp = strcmp(buf[mid].no,x); //比较中间点学号与目标学号
if (tmp== 0) {
ans=mid;
break;//若相等,则查找完成跳出二分查找
}
else if (tmp > 0) top = mid - 1;//若大于,则结束下标变为中阿点前一个点下标
else base = mid + 1; //若小于, 则开始点下标变为中间点后一个点坐标
}
if (ans == -1) {
//若查找失败
printf("No Answer!\n" );
}
else printf("%s %s %s %d\n",buf[ans].no,buf[ans].name,buf[ans].sex,buf[ans].age);//若查找成功
}
}
return 0;
}
利用二分查找,原本O(n*m)的时间复杂度被优化到O(nlogn(排序) +mlogn),该复杂度是符合题目要求的。
贪心算法
在本章的最后介绍一种思路相对简单的算法一贫心。 说它是算法,倒不如说他是一种思想,一种总是选择“当前最好的选择”面不从整体上去把握的思想。但往往这种“贪心”的策略能得到接近最优的结果,甚至在某些情况下,这样就能得到最优解。
Problem 1

每次都买剩余物品中性价比(即重量价格比)最高的物品,直到该物品被买完或者钱耗尽。若该物品已经被买完,则我们继续在剩余的物品中寻找性价比最高的物品,重复该过程;若金钱耗尽,则交易结束。
#include <stdio.h>
#include <algorithm>
using namespace std;
struct goods {
//表示可买物品的结构体
double j; //该物品总重
double f; //该物品总价值
double s;//该物品性价比
bool operator <(const goods &A) const {
//重载小于运算符,确保可用sort函数将数组按照性价比降序排列
return s > A.s;
}
}buf[1000];
int main(){
double m;
int n;
while (scanf("%lf%d",&m,&n) != EOF) {
if (m == -1&&n == -1) break; //当n == -1且m == -1时跳出循环,程序运行结束
for(int i=0;i<n;i++){
scanf("%lf%lf",&buf[i].j,&buf[i].f); //输入
buf[i].s = buf[i].j/buf[i].f; //计算性价比
}
sort(buf,buf + n); //使各物品按照性价比降序排列
int idx = 0; //当前货物下标
double ans = 0; //累加所能得到的总重量
while (m> 0&&idx < n) {
//循环条件为,既有物品制余(idx < n)还有钱剩余(m > 0)时继续循环
if (m > buf[idx].f) {
ans+=buf[idx].j;
m-=buf[idx].f;
}//若能买下全部该物品
else {
ans+=buf[idx].j*m/buf[idx].f;
m=0;
} //若只能买下部分该物品
idx++; //继续下一个物品
}
printf("%.3lf\n",ans);
}
return 0;
}
Problem 2

此题的贪心策略就不再像上题一样那么显而易见了。读者可以在继续阅读之前,自己先考虑一下,何种贪心策略可以被应用到该题当中。
我们首先来思考这样一个问题:第一个节目我们应该选什么。
读者可能会有以下猜测过程。
- 选择开始时间最早的?
假如有电视节目A[0,5], B[1,2], C[3,4]。 显然,选择最先开始的节目并不一定能够得到最优解。
- 选择持续时间最短的?
假如电视节目是这样安排的A[0,10), B[11,20], C[9,12]。 显然,选择时间最短的节目也并不一定能够得到最优解。.
- 那么选择结束时间最早的?
这在以上两组案例中优先选择结束时间最早的节目是可以得到最优解的。那么它是否就真的是我们所需要的贪心策略?可以试着先来证明该命题:最优解中,第一个观看的节目一定是所有节目里结束时间最早的节目。因为按照优先选择结束时间最早的节目,我们所观看的第一个节目一定是所有节目里结束时间最早的。
同样的我们用反正法来证明:假设命题:最优解中,第一个观看的节目A[s1,e1]不是所有节目时间里结束时间最早的节目。即,存在节目B[s2,e2], 其中e2<e1。 那么B节目一定不在该解当中,因为若在,其顺序一定在A节目之前,但是A节目已经被假定为第一个节目,所以B节目一定没被我们收看。那么,我们可以将该解中的第一个节目A替换为B节目,该替换保证是合法的,即去除B节目以后,其它节目的播出时间一定不会与A节目冲突。做这样的咎换以后,原解与当前解除了第一个节目不同(由节目B变为节目A),其它节目安排完全相同。那么这两组解所包含的节目数是一模一样的,该解也是最优解。
由以上证明可见,如果最优解的第一个节目并不是结束最早的节目,那么我们可以直接用结束时间最早的节目代替该解中的第一个节目,替换后的解也是最优解。这样,我们就可以得出当第一个节目选择所有节目中结束时间最早的节目,这样是一定不会得不到最优解的。于是,在我们所要求的最优解中,第一个被收看的节目可以安排所有节目中结束时间最早的节目(若有多个,则可任意选择一个)。
当第一个被收看的节目被决定了以后,那么第二个呢?
只要不断重复上述证明过程,就会知道:在选择第x(x>=1)个节目时,一定是选择在收看完前x-1个节目后,其它所有可以收看节目中结束时间最早的节目,这就是我们要找的贪心策略。
#include <stdio.h>
#include <algorithm>
using namespace std;
struct program {
//电视节目结构体
int startTime; //节目开始时间
int endTime; //节日结束时间
bool operator < (const program & A) const {
//重载小于号,保证sort函数能够按照结束时间升序排列
return endTime < A. endTime;
}
}buf[100];
int main(){
int n;
while (scanf("%d",&n) != EOF) {
if (n == 0) break;
for(int i=0;i<n;i++){
scanf("%d%d",&buf[i].startTime,&buf[i].endTime);
}
sort(buf,buf + n); //按照结束时间升序排列
int currentTime = 0, ans = 0; //记录当前时间变量初始值为0,答案计数初始值为0
For(int i=0;i<n;i++){
//按照结束时间升序遍历所有的节目
if (currentTime <= buf[i].startTime) {
//若当前时间小于等于该节目开始时间,那么收看该在剩余节目里结束时间最早的节目
currentTime = buf[i].endTime; //当前时间变为该节目结束时间
ans++; //又收看了一个节目
}
}
printf("%d\n",ans);
}
return 0;
}