Pytorch交叉熵损失函数CrossEntropyLoss及BCE_loss
什么是交叉熵?
交叉熵(Cross Entropy)是信息论中一个重要概念,主要用于度量两个概率分布间的差异性信息。交叉熵越小说明两个分布越接近,反之差异越大。其中p为真实分布,q为非真实分布。交叉熵可在神经网络(机器学习)中作为损失函数,即p往往用来表示样本的真实标签,q用来表示模型的预测结果。交叉熵损失函数可以衡量p与q的相似性。
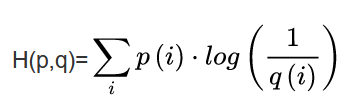
Pytorch中的CrossEntropyLoss()函数
是默认的加上了softmax的操作,即对最后输出的分布q,加上了softmax的。此时公式为:
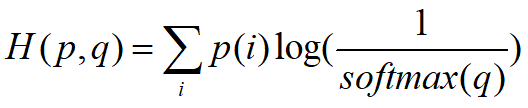
函数的具体实现形式如图所示:

代码如下(示例):
import torch
import torch.nn as nn
q_output=torch.randn(3,3)#网络输出[Batch,pre_label]
p_target=torch.tensor([2,1,0])#真实标签
softmax_func=nn.Softmax(dim=1)
soft_output=softmax_func(q_output)#计算输入softmax
logsoftmax_output=torch.log(soft_output)#在softmax的基础上取log
"""
#等价于nn.LogSoftmaxloss
logsoftmax_func=nn.LogSoftmax(dim=1)
logsoftmax_output=logsoftmax_func(x_input)
"""
#nn.NLLLoss()点乘
nllloss_func=nn.NLLLoss()
nlloss_output=nllloss_func(logsoftmax_output,p_target)
print('nlloss_output:\n',nlloss_output)
#等价于nn.CrossEntropyLoss()
crossentropyloss=nn.CrossEntropyLoss()
crossentropyloss_output=crossentropyloss(q_output,p_target)
print('crossentropyloss_output:\n',crossentropyloss_output)
带权重的CrossEntropyLoss
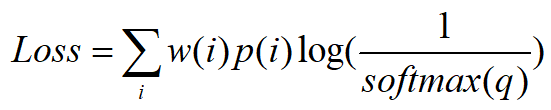
BCE_loss
就是CrossEntropy的特例,二分类问题。
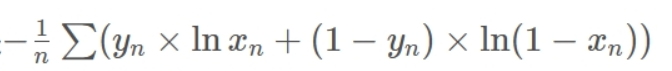
BCE_withlogistic
BCE_withlogistic就是把Sigmoid-BCEloss合成一步
思考
1.与MSE比较
目前,基本认为是如果要做个分类器的话就是交叉熵,要做回归问题的话就是mse。主要是两种损失函数对分类和回归结果误差的衡量的方式不同。比如,交叉熵,在分类时(热编码),如果分类正确,则损失值为零,否则就有个较大的损失值,然后反向传播,能够更好地更新权重;同理,均方误差mse,则是很好地衡量了预测的实数值和事实值之间的数值大小的差异程度,如果很大,则bp之后权重更新会较为明显,反之,则只是微调权重。
更好的解释参照链接: 听话的耳背少年 交叉熵
2.为什么要用softmax?
加softmax函数是因为它可以将所有类别打分都限制在【0,1】之间,而且所有类别打分和是1,这样就可以将最终输出结果看做是该类别的概率。当然,如果不用softmax,也是可以采用其它方法的,如最后输出层不加softmax,则需要自行设计一种方案来处理不同类别间分类差异并提供合理性的损失来优化网络。
此外,并非所有0-1之间的数都可以称为概率,sigmoid 本身不能赋予输出概率意义,而是 cross entropy 这样有概率意义的损失函数,才让输出可以解释成概率的。
说明
以上仅为个人学习心得,如有不恰当之处,请留言。