Spring Boot Jpa 是 Spring 基于 ORM 框架、Jpa 规范的基础上封装的一套 Jpa 应用框架,可使开发者用极简的代码即可实现对数据的访问和操作。它提供了包括增删改查等在内的常用功能,且易于扩展!学习并使用 Spring Data Jpa 可以极大提高开发效率。
(完全用面向对象的思想操作数据库----不要写sql语句,可以crud数据库)
jpa与mybatis的区别?
1.对象jdbc的封装程度不同。 orm 对象关系映射 object relationship mapping jpa完全用面向对象思想操作数据库的orm框架 mybatis轻量级的orm框架 2.jpa适合功能需求变更不频繁的情况。---传统项目 OA ERP 银行 mybatis-plus适合功能需求变更频繁的情况。---互联网项目 3.jpa不适合复杂的数据库的操作----数据表行转列 mybatis可以通过sql语句实现。 4.jpa的sql优化要复杂,很难控制sql语句。 mybatis很方便进行sql优化
我们就用一个员工部门的案例来实现一下多表查询
一、首先分析一下表之间的关系
1、一对一
2、多对一&一对多
3、多对多
就拿2来实现
employee:员工表
id
emp_name
emp_job
dept_id
department:部门表
id
dept_name
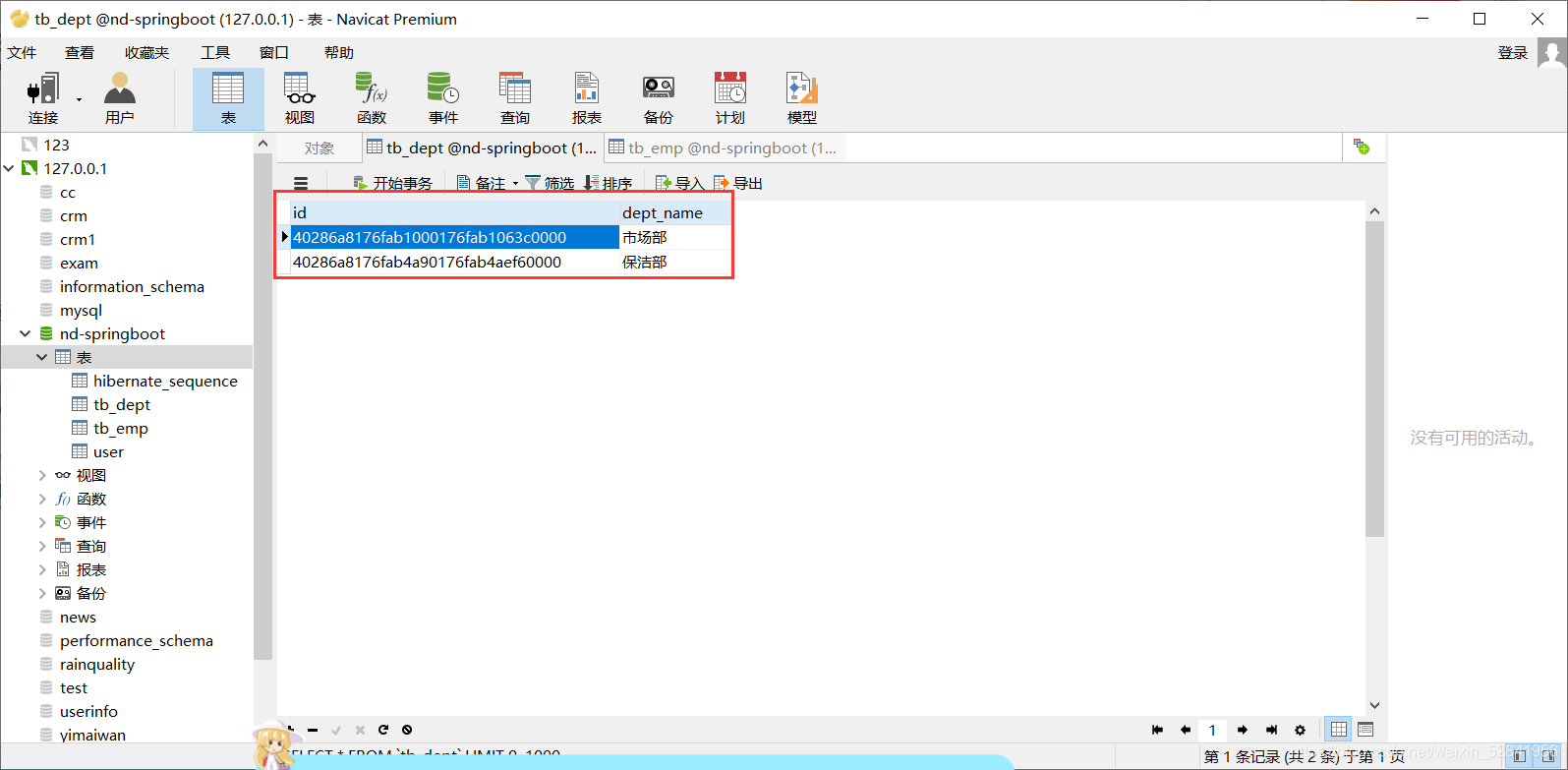
id dept_name
1 市场部
2 保洁部
员工表与部门表:多对一 多个员工属于一个部门
部门表与员工表:一对多 一个部门包含多个员工
1、导入依赖:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jpa</artifactId>
</dependency>
一、配置application.yml文件
spring: datasource:
url: jdbc:mysql://localhost:3306/nd-springboot?useUnicode=true&characterEncoding=utf-8&serverTimezone=UTC
password: 123456
username: root jpa:
database: mysql
hibernate:
#数据库自动创建表 实际开发中要关闭
# ddl-auto 几种属性
# create: 每次运行程序时,都会重新创建表,故而数据会丢失
# create-drop: 每次运行程序时会先创建表结构,然后待程序结束时清空表
# upadte: 每次运行程序,没有表时会创建表,如果对象发生改变会更新表结构,原有数据不会清空,只会更新(推荐使用)
# validate: 运行程序会校验数据与数据库的字段类型是否相同,字段不同会报错
ddl-auto: update #在开发阶段使用
#在控制台显示sql语句
show-sql: true
这里url要注意时区,否则会报错
二、创建实体类employee和department,定义两个类用于关联查询,查询出员工的同时获取所在的部门信息
部门表:department
@Entity
@Table(name = "tb_dept")
@Data
//@Setter@Getter
public class Department {
@Id
@GeneratedValue(generator = "idGenerator")
@GenericGenerator(name = "idGenerator", strategy = "uuid")
private String id;
private String deptName;
@OneToMany(mappedBy = "department",cascade = {
CascadeType.ALL},fetch = FetchType.EAGER)
private Set<Employee> employees;
}
员工表:employee
@Entity
@Table(name="tb_emp")
//@Data
@Setter@Getter
public class Employee {
@Id
//主键字符串,通过程序自动生产主键值
@GenericGenerator(name = "idGenerator", strategy = "uuid")
@GeneratedValue(generator = "idGenerator")
private String id;
private String empName;
private String empJob;
@ManyToOne(targetEntity = Department.class,fetch = FetchType.EAGER)
@JoinColumn(name="dept_id")
private Department department;
}
注意: 级联查询,不要使用@Data,正确的做法:@Setter@Getter+自己生产toString
否则会导致StackOut…,栈溢出
稍微解释一下@ManyToOne和@OneToMany的参数
cascade:级联(一个犯法,满门cz)
CascadeType.MERGE级联更新:若User属性修改了那么中间表保存时同时修改items里的对象。对应EntityManager的merge方法 CascadeType.PERSIST级联保存:对user对象保存时也对role里的对象也会保存。对应EntityManager的presist方法 CascadeType.REFRESH级联刷新:获取user对象也同时也重新获取最新的role时的对象。对应EntityManager的refresh(object)方法有效。即会重新查询数据库里的最新数据 CascadeType.REMOVE级联删除:对users对象删除也对中间表role里的对象也会删除。对应EntityManager的remove方法 CascadeType.ALL包含所有; fetch:抓取策略 fetch.lazy :懒加载 获取user对象信息时,不会马上去获取该用户对应的所有角色信息 当我们通过user.getRoles是才会去获取该用户的所有角色的所有信息。 fetch.EAGER 立即加载 获取user对象信息时,会立即获取该用户所对用的所有角色的所有信息。
三、 创建接口DepartmentRepository和EmployeeRepository集成JpaRespository:
接口:EmployeeRepository
@Repository
public interface EmployeeRepository extends JpaRepository<Employee,String> {
}
接口:DepartmentRepository
@Repository
public interface DepartmentRepository extends JpaRepository<Department,String> {
}
四:编写NdspringbootJpa03ApplicationTests测试类
@SpringBootTest
class NdspringbootJpa03ApplicationTests {
@Autowired
private DepartmentRepository departmentRepository;
//一对多
@Test
void contextLoads() {
//一.添加 2个新员工到1个新部门
//1)创建2个员工对象和1个部门对象
Department d1 = new Department();
d1.setDeptName("保洁部");
d1.setDeptName("市场部");
Employee e1 = new Employee();
e1.setEmpName("权哥");
Employee e2 = new Employee();
e2.setEmpName("兰输");
// //2)相互认识
// //a.将2个员工添加到部门对象中
Set<Employee> employs =new HashSet<>();
employs.add(e1);
employs.add(e2);
d1.setEmployees(employs);
// b.将部门对象添加到2个员工对象中
e1.setDepartment(d1);
e2.setDepartment(d1);
//
// //3)保存部门对象
departmentRepository.save(d1);
}
}
运行创建出需要使用的表以及数据
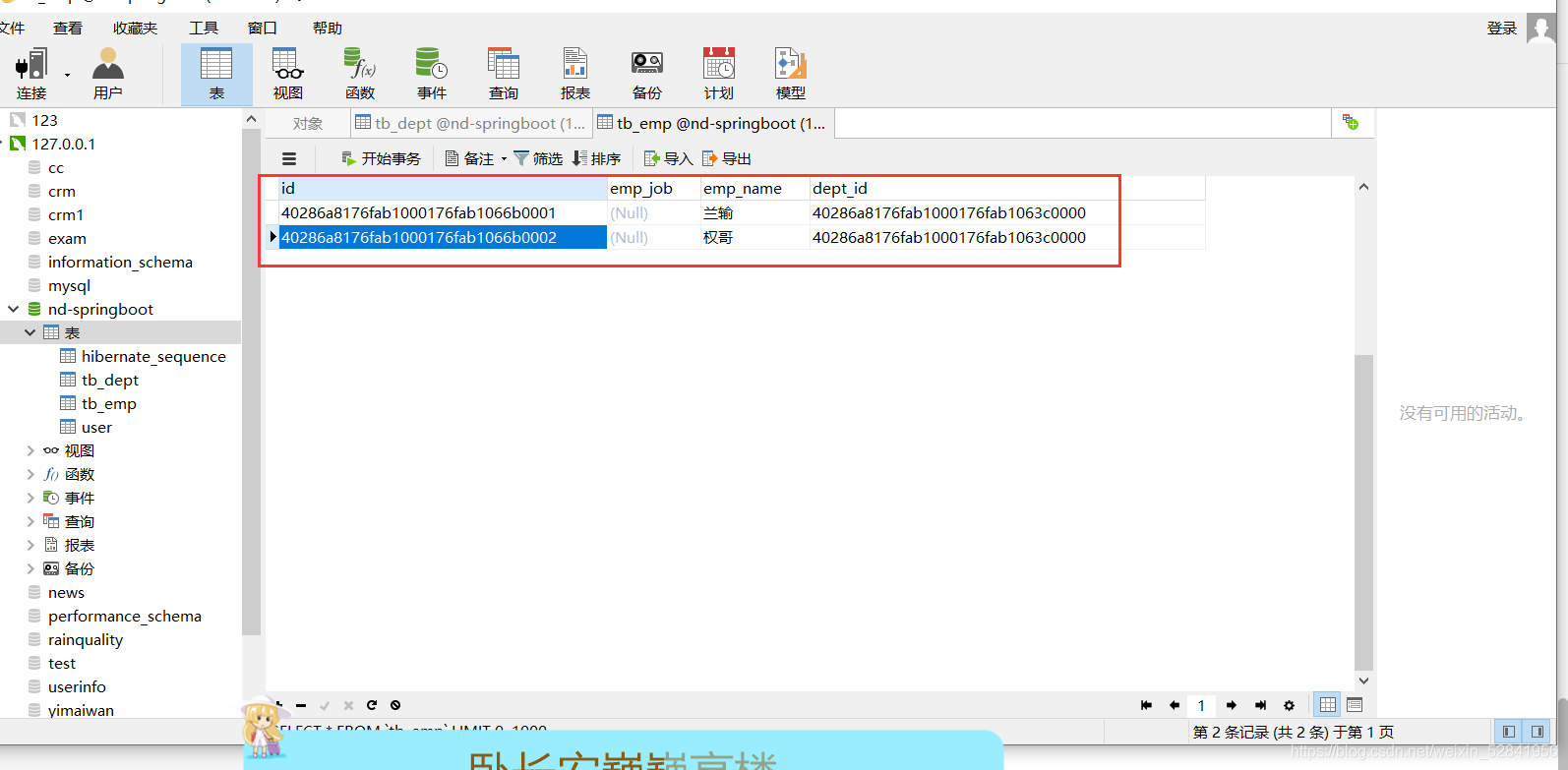
实际功能测试
我们来将一个新员工,添加到旧部门
@SpringBootTest
class NdspringbootJpa03ApplicationTests {
@Autowired
private DepartmentRepository departmentRepository;
//一对多
@Test
void contextLoads() {
Employee e1 = new Employee();
e1.setEmpName("兰输");
Optional<Department> optional = departmentRepository.findById("40286a8176fab4a90176fab4aef60000");//企划部
Set<Employee> employees = optional.get().getEmployees();
employees.forEach(e->{
System.out.println(e);
});
Department dept = optional.get();
Set <Employee> employees1 = dept.getEmployees();
//添加新员工到部门中
employees.add(e1);
//员工对象中添加部门对象
e1.setDepartment(dept);
//更新部门
departmentRepository.save(dept);
}
}
我们来看看数据库效果
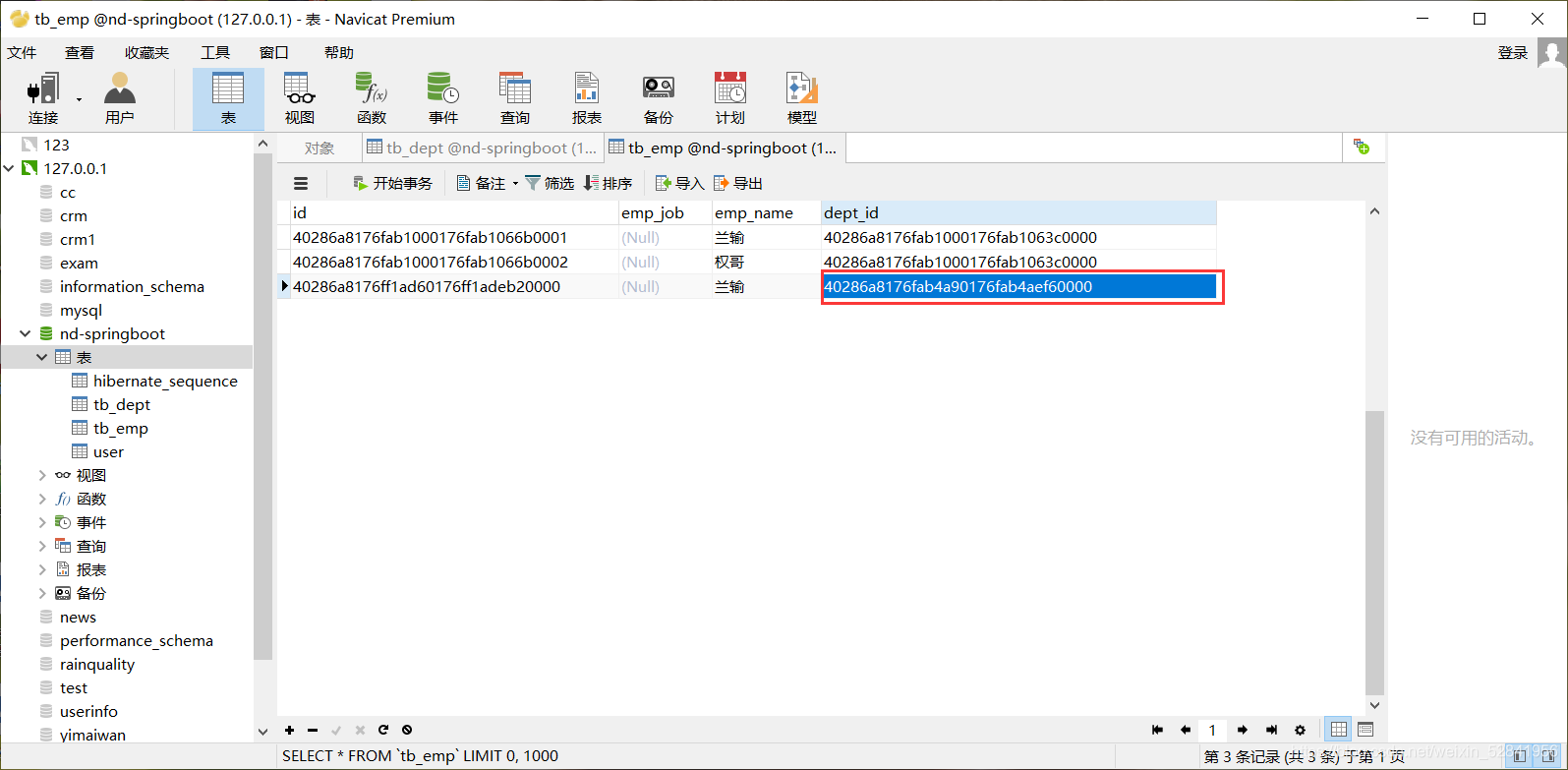
新加的人物id属于保洁部,所以效果达到了