回归分析(regression analysis)是确定两种或两种以上变数间相互依赖的定量关系的一种统计分析方法。运用十分广泛,回归分析按照涉及的自变量的多少,可分为一元回归分析和多元回归分析;按照自变量和因变量之间的关系类型,可分为线性回归分析和非线性回归分析。
回归(regression):Y变量为连续数值型(continuous numerical variable)。这就是回归的本质。
目前主流的神经机器翻译模型为自回归模型,每一步的译文单词的生成都依赖于之前的翻译结果,因此模型只能逐词生成译文,翻译速度较慢。Gu等人提出的非自回归神经机器翻译模型(NAT)对目标词的生成进行独立的建模,因此能够并行解码出整句译文,显著地提升了模型的翻译速度。然而,非自回归模型在翻译质量上与自回归模型有较大差距,主要表现为模型在长句上的翻译效果较差,译文中包含较多的重复词和漏译错误等。
非自回归(Non-autoregressive,NAR)模型并行生成序列的所有标记,与自回归(AR)模型相比,生成速度更快,但代价是准确性较低。在神经机器翻译(neural machine translation,NMT)、自动语音识别(automatic speech recognition,ASR)和语音合成(TTS)等不同的任务中,人们提出了包括知识提取和源-目标对齐在内的不同技术来弥补AR和NAR模型之间的差距。在这些技术的帮助下,NAR模型可以在某些任务中赶上AR模型的准确性,但在其他任务中则不能。
AR
AR模型,即自回归(AutoRegressive, AR)模型又称为时间序列模型,数学表达式为:
y(t)=∑i=1naiy(t−i)+e(t)y(t)=∑i=1naiy(t−i)+e(t)
此处的n表示n阶自回归。
AR模型是一种线性预测,利用前期若干时刻的随机变量的线性组合来描述以后某时刻随机变量的线性回归模型。即已知N个数据,可由模型推出第N点前面或后面的数据(设推出P点),所以其本质类似于插值,其目的都是为了增加有效数据,只是AR模型是由N点递推,而插值是由两点(或少数几点)去推导多点,所以AR模型要比插值方法效果更好。
NLP中的 sequence2sequence 和 Transformer 都是AR模型。sequence to sequence模型是一类End-to-End的算法框架,也就是从序列到序列的转换模型框架,应用在机器翻译,自动应答等场景。
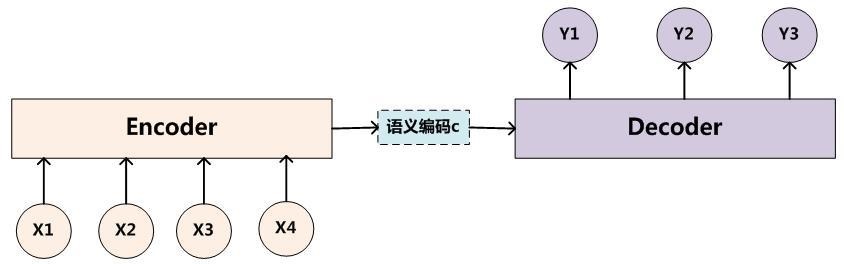
Encoder-Decoder模型可以预测任意的序列对应关系,但同时也有一个很大的问题就是从编码到解码的准确率很大程度上依赖于一个固定长度的语义向量c,输入序列到语义向量c的压缩过程中存在信息的丢失,并且在稍微长一点的序列上,前边的输入信息很容易被后边的输入信息覆盖,也就是说编码后的语义向量c已经存在偏差了,解码准确率自然会受到影响。其次在解码的时候,每个时刻的输出在解码过程中用到的上下文向量是相同的,没有做区分,也就是说预测结果中每一个词的的时候所使用的预测向量都是相同的, 这也会给解码带来问题。
一句话,就是中间形式就已经出现信息丢失了。中间形式就是固定向量,为了解决这样的问题,在Seq2Seq模型加入了注意力机制(attention mechanism),在预测每个时刻的输出时用到的上下文是跟当前输出有关系的上下文,而不是统一只用相同的一个。这样在预测结果中的每个词汇的时候,每个语义向量c中的元素具有不同的权重,可以更有针对性的预测结果。图示如下,增加了一个“注意力范围”,表示接下来输出词时候要重点关注输入序列中的哪些部分,然后根据关注的区域来产生下一个输出:
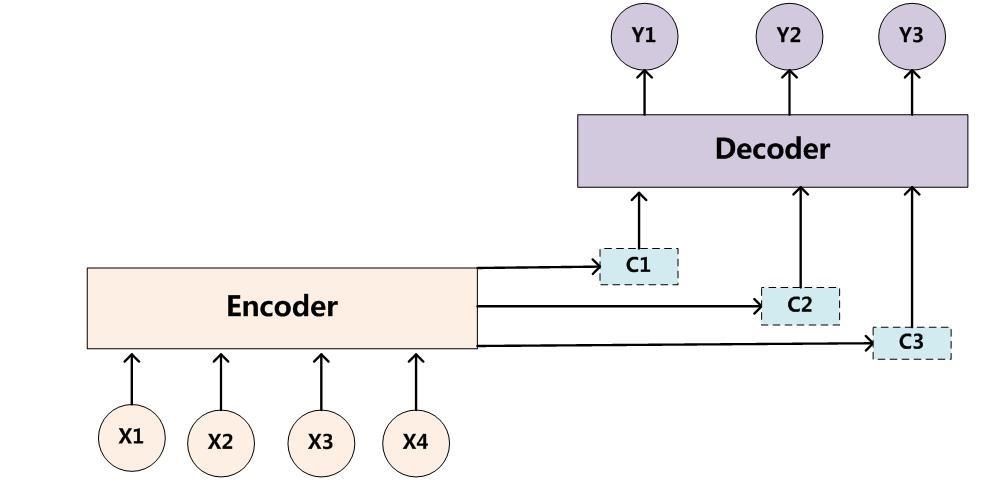

可以看到原初方式是非常容易被后面覆盖的。attention模型最大的不同在于Encoder将输入编码成一个向量的序列,而在解码的时候,每一步都会选择性的从向量序列中挑选一个子集进行输出预测,这样,在产生每一个输出的时候,都能找到当前输入对应的应该重点关注的序列信息,也就是说,每一个输出单词在计算的时候,参考的语义编码向量c都是不一样的,所以说它们的注意力焦点是不一样的。
自Attention机制提出后,加入attention的Seq2seq模型在各个任务上都有了提升,所以现在的seq2seq模型指的都是结合RNN和attention的模型。之后google又提出了解决Seq2Seq问题的Transformer模型,用全attention的结构代替了lstm,在翻译任务上取得了更好的成绩。和大多数seq2seq模型一样,transformer的结构也是由encoder和decoder组成。

前馈神经网络(FNN)是人工智能领域中最早发明的简单人工神经网络类型。在它内部,参数从输入层经过隐含层向输出层单向传播。与递归神经网络不同,在它内部不会构成有向环。FNN由一个输入层、一个(浅层网络)或多个(深层网络,因此叫作深度学习)隐藏层,和一个输出层构成。每个层(除输出层以外)与下一层连接。这种连接是 FNN 架构的关键,具有两个主要特征:加权平均值和激活函数。就是不带环呗。最基本的transformers 完全依赖于注意力机制.一个单词,有注意力模型后,就对其他单词有不同权值,如果没有注意力机制,那么就都是一样的。
这里要特别注意一下,编码可以并行计算,一次性全部encoding出来,但解码不是一次把所有序列解出来的,而是像rnn一样一个一个解出来的,因为要用上一个位置的输入当作attention的query
NAR
举例说明:在机器翻译中,不同于自回归(Autoregressive Translation , ART)模型需要用已生成的词来预测下一个位置的词,非自回归 (Non-Autoregressive Translation, NART)模型打破了生成时的串行顺序,希望一次能够解码出整个目标句子,从而解决AT模型所带来的问题。
与自回归模型相比,非自回归(Non-Autoregressive)模型尝试同时生成一整个序列,从而解决上述三个问题。一个简单的非自回归模型直接假设目标序列的每个词都是独立的。然而这一独立性假设过强,显然与实际问题不符。为了缓解独立性假设过强的问题,一个方案是引入隐变量z,得到:
Pθ(y|x)=∫zPθ(y|z,x)pθ(z|x)dzPθ(y|x)=∫zPθ(y|z,x)pθ(z|x)dz
假定给定隐变量的前提下,目标序列的每个词是独立的,则:
Pθ(y|z,x)=∏t=1TPθ(yt|z,x)Pθ(y|z,x)=∏t=1TPθ(yt|z,x)
从上面的公式可以看出,隐变量需要保存关于目标序列的全部信息,才能解码整个目标序列。因此隐变量的概率分布必须有足够的复杂度。
近年来,以 FastSpeech 为代表的非自回归语音合成(Text to Speech, TTS)模型相比传统的自回归模型(如 Tacotron 2)能极大提升合成速度,提升语音鲁棒性(减少重复吐词、漏词等问题)与可控性(控制速率和韵律),同时达到相匹配的语音合成质量。
对于一些在线预测任务来说,复杂的模型结构不利于线上预测任务的快速响应需求,因此模型压缩的需求应运而生。深度学习下为了能够获得更好的准确率,训练出的网络往往结构比价复杂,这个teacher-student模式架构主要的目的就是用来进行深度学习模型的压缩,属于model compression领域中的一种比较流行的做法。teacher结构相当于原始的复杂的深度神经网络结构,student则是一种轻量级的网络结构;因此teacher会有更高的预测准确率,它会指导student到达在简化参数之后最好的模型效果。
在化学中,蒸馏是一个有效的分离沸点不同的组分的方法,大致步骤是先升温使低沸点的组分汽化,然后降温冷凝,达到分离出目标物质的目的。在前面提到的这个过程中,我们先让温度 T 升高,然后在测试阶段恢复「低温」,从而将原模型中的知识提取出来,因此将其称为是蒸馏,实在是妙。
FastSpeech 2,它抛弃了 Teacher-Student 知识蒸馏框架降低训练复杂度,直接用真实的语音数据作为训练目标避免信息损失,同时引入了更精确的时长信息和语音中的其它可变信息(包括音高(Pitch)和音量(Energy)等)来提高合成的语音质量。基于 FastSpeech 2,我们还提出了加强版 FastSpeech 2s 以支持完全端到端的从文本到语音波形的合成,省略了梅尔频谱的生成过程。实验结果表明,FastSpeech 2 和 2s 在语音质量方面优于 FastSpeech,同时大大简化了训练流程减少了训练时间,还加快了合成的速度。
在 FastSpeech 2 的基础上,我们提出了 FastSpeech 2s 以实现完全端到端的文本到语音波形的合成。FastSpeech 2s 引入了一个波形解码器,如图1(d)所示,它以可变信息适配器的输出隐层序列为输入,以波形为输出。在训练时,为了帮助可变信息预测器的训练,梅尔频谱解码器及其训练损失函数被保留。在生成阶段,将梅尔频谱解码器丢弃后,使其成为一个文本到波形的端到端系统。
FastSpeech2 Trainer基于FastSpeech Trainer
混合精度,唉,做不了。。。
在训练模型的过程中,一个step其实指的就是一次梯度更新的过程。例如在每个epoch中有2000个用于训练的图片,我们选取了batch_size=100,那么我们就需要2000 images / 100 (images/step) = 20 steps来完成这个epoch。
用Python写代码的时候,在想看的地方写个print xx 就能在控制台上显示打印信息,这样子就能知道它是什么了,但是当我需要看大量的地方或者在一个文件中查看的时候,这时候print就不大方便了,所以Python引入了logging模块来记录我想要的信息。
print也可以输入日志,logging相对print来说更好控制输出在哪个地方,怎么输出及控制消息级别来过滤掉那些不需要的信息。默认生成的root logger的level是logging.WARNING,低于该级别的就不输出了
with是从Python2.5引入的一个新的语法,它是一种上下文管理协议,目的在于从流程图中把 try,except 和finally 关键字和
资源分配释放相关代码统统去掉,简化try….except….finlally的处理流程。with表达式其实是try-finally的简写形式。但是又不是全相同。with发生了异常也会关闭程序。但是with本身并没有异常捕获的功能,但是如果发生了运行时异常,它照样可以关闭文件释放资源。
Adam 是一种可以替代传统随机梯度下降(SGD)过程的一阶优化算法,它能基于训练数据迭代地更新神经网络权重。Adam 最开始是由 OpenAI 的 Diederik Kingma 和多伦多大学的 Jimmy Ba 在提交到 2015 年 ICLR 论文(Adam: A Method for Stochastic Optimization)中提出的。
「Adam」,其并不是首字母缩写,也不是人名。它的名称来源于适应性矩估计(adaptive moment estimation)。Adam 算法和传统的随机梯度下降不同。随机梯度下降保持单一的学习率(即 alpha)更新所有的权重,学习率在训练过程中并不会改变。而 Adam 通过计算梯度的一阶矩估计和二阶矩估计而为不同的参数设计独立的自适应性学习率 Adam 算法的提出者描述其为两种随机梯度下降扩展式的优点集合。
在python的类中,没有真正的私有化,不管是方法还是属性,为了编程的需要,约定加了下划线 _ 的属性和方法不属于API,不应该在类的外面访问,也不会被from M import * 导入。
在类A中,__method方法其实由于name mangling技术的原因,变成了_A__method,所以在A中method方法返回的是_A__method,B作为A的子类,只重写了__method方法,并没有重写method方法,所以调用B中的method方法时,调用的还是_A__method方法
matplotlib,风格类似 Matlab 的基于 Python 的图表绘图系统。
matplotlib 是 Python 最著名的绘图库,它提供了一整套和 matlab 相似的命令 API,十分适合交互式地进行制图。而且也可以方便地将它作为绘图控件,嵌入 GUI 应用程序中。
@tf.function
- 将python的函数编译成tensorflow的图结构,所以可以方便的直接使用python的语法去写深度学习的一些函数代码
- 易于将模型导出为GraphDef+checkpoint和saveModel
- 使得eager exection默认打开。如果不使用@tf.function,虽然可以使用eager exection去写代码,但是模型的中间结果无法保存,所以无法进行预测
- tf1.0的代码可以经过@tf.function修饰之后在tf2里面继续使用。
此时其功能就是tf1里面的session
Learner可以是learn to classify 也可以是learn to approximate (regression),是一个广义概念。
Classifier特指learn to classify
Predictor在绝大多数时候指learn to approximate,有的时候特指具有时序结构的regression问题。
Estimator主要特指估算概率分布,也是learn to approximate的一类问题。但是不排除其他用法
pipeline,管道机制,可以看成java的string的函数调用链,就是如此了。