什么是高并发
由于分布式系统的问世,高并发(High Concurrency)通常是指通过设计保证系统能够同时并行处理很多请求。通俗来讲,高并发是指在同一个时间点,有很多用户同时的访问同一 API 接口或者 Url 地址。它经常会发生在有大活跃用户量,用户高聚集的业务场景中。
高并发的等级
- 一线:阿里、腾讯、京东 …
- 二线:美团、58同城 …
- 三线:瓜子 …
在谈高并发下的系统架构之前,首先要明确并发量的等级,对于不同量级的并发架构是不同的。对于一线互联网公司来说,并发量是及其大的,尤其对于详情页的访问量,对于详情页是可以单独拿出来作为一个模块处理的。而对于二线互联网公司来说,除此之外还有如12306、考试系统等瞬时高并发。
在这里我们主要聊对于阿里、腾讯这样的一线大厂的高并发架构。
高并发下的数据一致性
除了并发量的等级之外另一个需要明确的就是对数据一致性的要求
数据一致性问题是处理高并发的核心问题之一,数据是否需要一致,是高一致性还是最终一致性,数据如何分布,如何同步,响应时间等问题都需要事先考虑好。
- 高一致性:会带来更高的性能消耗
- 最终一致性:采取延迟更新、性能消耗低一些
什么是削峰
从业务上来说,秒杀活动是希望更多的人来参与,也就是抢购之前希望有越来越多的人来看购买商品。
但是,在抢购时间达到后,用户开始真正下单时,秒杀的服务器后端缺不希望同时有几百万人同时发起抢购请求。
我们都知道服务器的处理资源是有限的,所以出现峰值的时候,很容易导致服务器宕机,用户无法访问的情况出现。
这就好比出行的时候存在早高峰和晚高峰的问题,为了解决这个问题,出行就有了错峰限行的解决方案。
同理,在线上的秒杀等业务场景,也需要类似的解决方案,需要平安度过同时抢购带来的流量峰值的问题,这就是流量削峰
亿级流量多级缓存架构
当高流量的请求发送过来时,首先要对其进行削峰,我们可以采用Nginx做一层反向代理,然后让他代理到后端的几十台或者几百台服务器上做负载均衡。
采用这种架构时,首先作为负载均衡器的Nginx就要能抗住高并发的请求,否则后续架构也无法谈下去。
对于Nginx能承受的并发量,官方给出数据是最高约50000
也就是说,采用上述架构一旦并发量超过50000,就不适用了
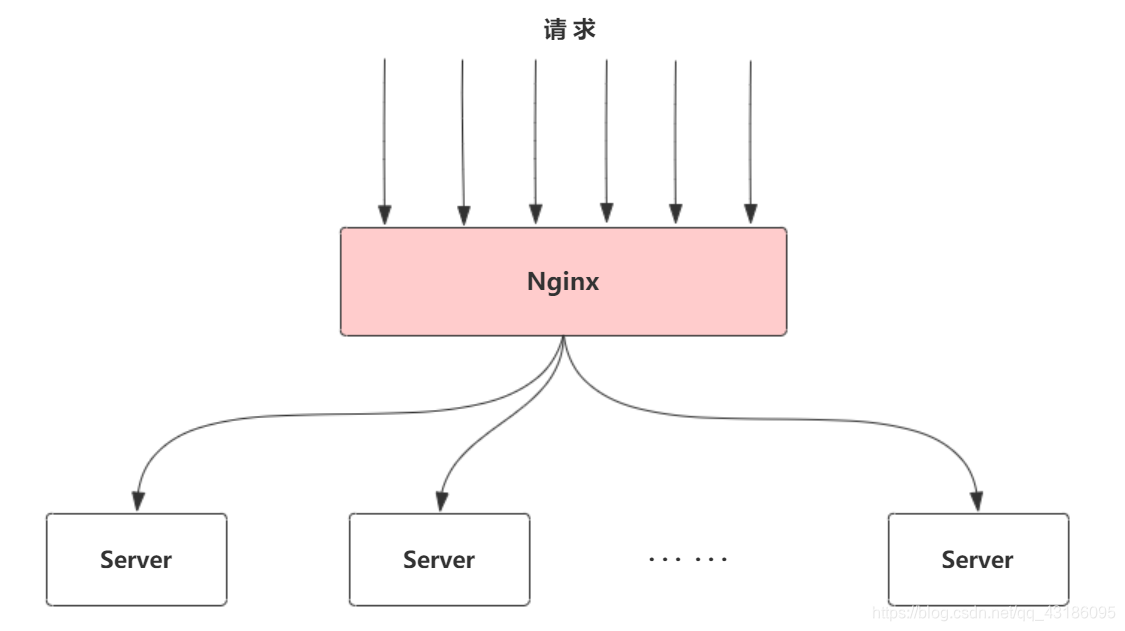
当并发量超过50000后,或者说在亿级流量下,可以采取如下架构
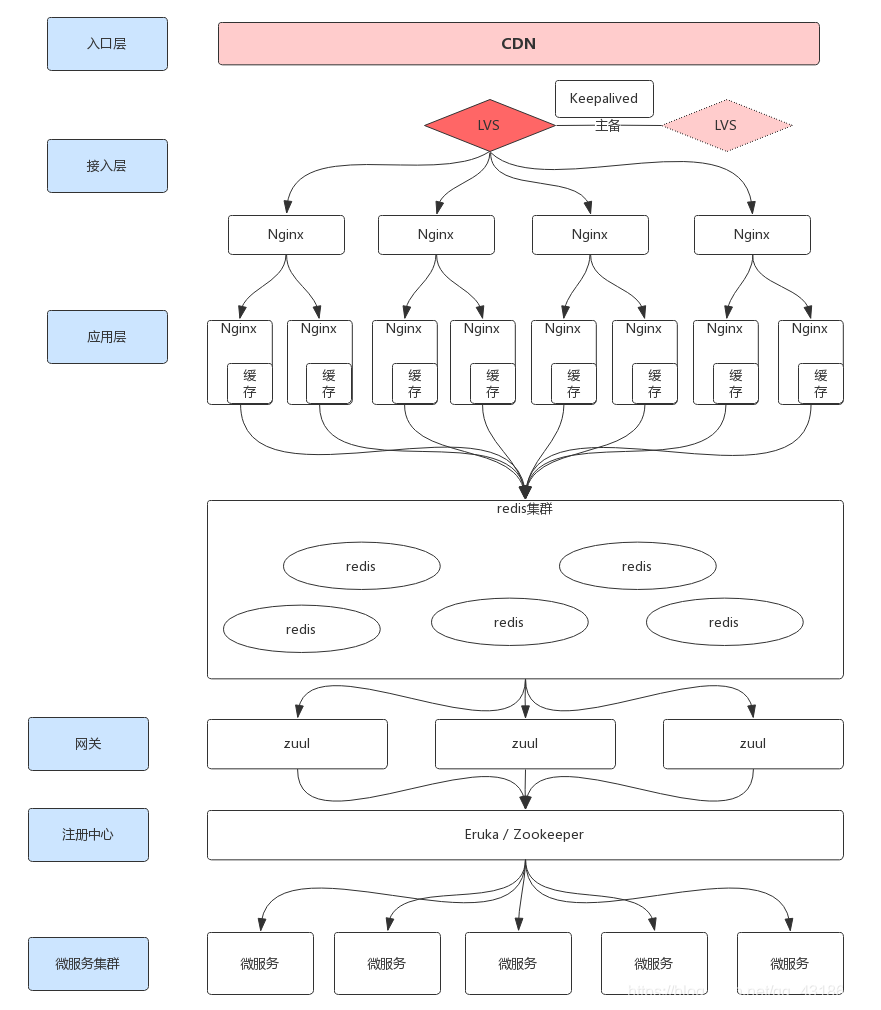
首先对业务进行拆分,拆分成不同的模块,每个模块为一个业务线,对不同的业务线做多机房部署
比如划分域名:
- qq.com
- down.qq.com
- games.qq.com
- … …
每个域名为一个业务线,对应一组服务器
入口层
接下来对单域名做CDN,让CDN去缓存 静态资源以及少量/一致性要求低/动态缓存。
对于动态缓存,比如说搜索结果页,我们可以降低数据一致性,把搜索结果页的前几页在CDN做缓存,设一个定时JOB,五分钟更新一次这个缓存。
CDN可以极大的降低并发量
除此之外,可以把处理完的数据放在缓存中,即redis集群里,每次请求都从缓存中取数据,如果没有数据再进行处理,并将处理完成后的数据放入redis集群中。
比如:将常用的SQL语句作为key写入redis集群,减少对数据库的压力
我们知道,tomcat中有controller存在,controller调用service,service最后调用了redis集群,是这样一个流程。在这里tomcat最好并发不要超过200,否则会出现卡顿等问题。
接入层
在CDN之后可以加两台LVS,做主备,并且加入Keepalived达到HA高可用的目的。
在LVS之后加入Nginx集群做反向代理,达到流量分发的目的。
应用层
在接入层的Nginx集群之后,还可以加一层应用层级别的Nginx集群,对于接入层的每一个Nginx之后加两个主备Nginx。
应用层Nginx上,可以内嵌Lua脚本,去访问redis集群或者在redis集群前再加一层削峰,加入kafka消息队列
此外,在应用层Nginx中还可以加入Lua的缓存,减少socket请求以及redis返回给客户端的请求,即减少性能上的开销
然后在接入层的Nginx上对URL做hash,保证每个URL只会访问同一个Nginx,除此之外要对URL中的锚点做过滤
架构难点
- redis集群数据更新,应用层Nginx中缓存如何同步
- 微服务集群如何更新redis中数据
网关zuul
以上的接入层以及应用层相当于一个网关,但是也可以在接入层之后再加一个网关zuul
为了进一步减少并发,对网关也可以做集群,不同的Nginx的请求发送给不同的网关
注册中心
在网关之后加入注册中心eruka或者zookeeper,将微服务集群注册到注册中心
注册中心将网关的请求发给微服务集群,微服务集群之间做回调,返回给网关结果,网关再把结果发送给前端的Nginx
以上便是一套粗粒度的、针对于读请求的高并发系统架构。
秒杀系统架构
业务背景
百万人抢100个商品
一层过滤
前端做实名认证、登录等,假设过滤掉了10w人
二层过滤
在js中做延迟提交,对数据分流。三秒钟每秒处理30w
对于这30w的并发就可以采取上述系统架构来支撑
之后对这30w请求做异地多活,然后建立一个中央仓库,做冷数据备份,每一个机房中做闭环数据的备份
也就是说100个库存在中央仓库和每一个机房中都存在,两者需要做同步(非即时性)
之后在反向代理Nginx上做低一致性的过滤,允许超过100个用户的请求进来,也就是说允许多于100个用户,假设2w个用户预秒到这100个商品,这个时候30w的并发已经削峰到只剩2w了
最后通过kafka去消费这2w请求,当消息到100的时候,抛弃后边数据。这里做的是强一致性。