1. 1.7中实现原理
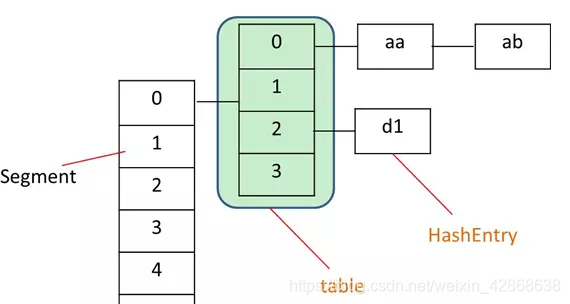
- 一个ConcurrentHashMap里包含一个Segment数组,每个Segment里包含一个HashEntry数组,我们称之为table,每个HashEntry是一个链表结构的元素。
- Segment实际继承自可重入锁(ReentrantLock),在ConcurrentHashMap里扮演锁的角色;HashEntry则用于存储键值对数据。
- 如何在保证高并发下线程安全的同时实现了性能提升?
ConcurrentHashMap允许多个修改操作并发进行,其关键在于使用了锁分离技术。它使用了多个锁来控制对hash表的不同部分进行的修改。内部使用段(Segment)来表示这些不同的部分,每个段其实就是一个小的hash table,只要多个修改操作发生在不同的段上,它们就可以并发进行。
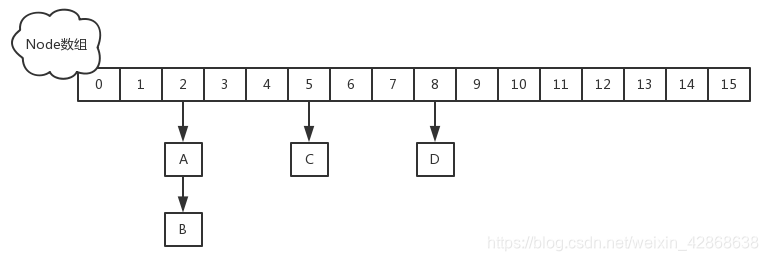
2. 1.8中实现原理
JDK1.8的实现已经摒弃了Segment的概念,而是直接用Node数组+(链表或红黑树)的数据结构来实现,并发控制使用Synchronized和CAS来操作。
-
取消segments字段,直接采用transient volatile HashEntry<K,V>[] table保存数据,采用table数组元素作为锁,从而实现了对每一行数据进行加锁,进一步减少并发冲突的概率。
-
将原先table数组+单向链表的数据结构,变更为table数组+单向链表+红黑树的结构。对于hash表来说,最核心的能力在于将key hash之后能均匀的分布在数组中。如果hash之后散列的很均匀,那么table数组中的每个队列长度主要为0或者1。但实际情况并非总是如此理想,虽然ConcurrentHashMap类默认的加载因子为0.75,但是在数据量过大或者运气不佳的情况下,还是会存在一些队列长度过长的情况,如果还是采用单向列表方式,那么查询某个节点的时间复杂度为O(n);因此,对于个数超过8(默认值)的列表,jdk1.8中采用了红黑树的结构,那么查询的时间复杂度可以降低到O(logN),可以改进性能。