bfs不适用于记忆化搜索的一道题
dfs和bfs往往需要穷竭搜索所有情况才能得到最优解,记忆化搜索通过增加一些变量来存储某些搜索过的情况避免重复搜索不必要的耗时。正常记忆化搜索都是用dfs实现,为什么不使用bfs呢?
NOIP2017年的一道题
有一个m × m的棋盘,棋盘上每一个格子可能是红色、黄色或没有任何颜色的。你现在要从棋盘的最左上角走到棋盘的最右下角。
任何一个时刻,你所站在的位置必须是有颜色的(不能是无色的),你只能向上、下、左、右四个方向前进。当你从一个格子走向另一个格子时,如果两个格子的颜色相同,那你不需要花费金币;如果不同,则你需要花费 1 个金币。
另外,你可以花费 2 个金币施展魔法让下一个无色格子暂时变为你指定的颜色。但这个魔法不能连续使用,而且这个魔法的持续时间很短,也就是说,如果你使用了这个魔法,走到了这个暂时有颜色的格子上,你就不能继续使用魔法;只有当你离开这个位置,走到一个本来就有颜色的格子上的时候,你才能继续使用这个魔法,而当你离开了这个位置(施展魔法使得变为有颜色的格子)时,这个格子恢复为无色。
现在你要从棋盘的最左上角,走到棋盘的最右下角,求花费的最少金币是多少?
输入描述
数据的第一行包含两个正整数 m,n,以一个空格分开,分别代表棋盘的大小,棋盘上有颜色的格子的数量。
接下来的 n 行,每行三个正整数 x,y,c,分别表示坐标为(x,y)的格子有颜色 c。其中 c=1代表黄色,c=0 代表红色。相邻两个数之间用一个空格隔开。棋盘左上角的坐标为(1,1),右下角的坐标为(m, m)。
棋盘上其余的格子都是无色。保证棋盘的左上角,也就是(1,1)一定是有颜色的。
输出描述
输出一行,一个整数,表示花费的金币的最小值,如果无法到达,输出-1。
数据范围
对于 30%的数据,1≤m ≤5, 1 ≤ n ≤ 10。
对于 60%的数据,1≤m ≤20, 1 ≤ n ≤ 200。
对于 100%的数据,1 ≤ m ≤ 100, 1 ≤ n ≤ 1,000。
样例1
输入
5 5
1 1 0
1 2 0
2 2 1
3 3 1
5 5 0
输出
8
样例解释
画出图来我们很容易就能得到答案
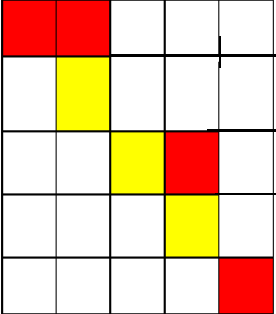
从(1,1)开始,走到(1,2)不花费金币
从(1,2)向下走到(2,2)花费1枚金币
从(2,2)施展魔法,将(2,3)变为黄色,花费2枚金币
从(2,2)走到(2,3)不花费金币
从(2,3)走到(3,3)不花费金币
从(3,3)走到(3,4)花费1枚金币
从(3,4)走到(4,4)花费1枚金币
从(4,4)施展魔法,将(4,5)变为黄色,花费2枚金币
从(4,4)走到(4,5)不花费金币
从(4,5)走到(5,5)花费1枚金币
解题思路
对于题中的数据量,如果不采用记忆化搜索,无论dfs还是bfs都会超时,而采用记忆化搜索的思路也很简单,定义一个数组dp [ i ] [ j ] \big[i\big]\big[j\big] [i][j]表示到达第 i i i行 j j j列的最小花费。搜索的时候,如果到达结点的dp [ i ] [ j ] \big[i\big]\big[j\big] [i][j]比该搜索路径记录的最小花费还要小,剪枝,不再继续搜索。用dfs是没有问题的,但是我用bfs却WA了。
更神奇的是,我修改遍历方向的顺序
int X[] = {
1, -1, 0, 0};
int Y[] = {
0, 0, 1, -1};每次WA的测试数据不同。
一开始我以为是我 i f if if的条件比较乱,修改多次仍有问题,从洛谷上下载到一个WA的测试数据,准备一探究竟。
将输入的数据画出来

我的bfs得到的结果是37,而答案是38,是哪里算少了呢?我在原来代码的基础上在Node中加入 v e c t o r < p a i r < i n t , i n t > > o p vector<pair<int,int>> op vector<pair<int,int>>op把bfs的路径记录下来
struct Node{
int x, y, color;
vector< pair<int, int> > op;
};如果到达(m,m)将路径输出,得到如下的走向和当前的dp [ i ] [ j ] \big[i\big]\big[j\big] [i][j]
下 1 下 3 右 4 下 6 右 6 下 6 下 6 下 7 右 7 下 9 下 10 右 11 右 12 右 13 下 15 右 16 下 17 下 19 下 20 右 21 下 23 下 24 右 24 下 26 右 26 下 27 右 29 右 29 下 30 右 30 下 32 右 33 下 35 下 35 右 35 右 37 右 38 右 36 右 35 37
发现(4,3)到(5,3)应该+2,但是却没有变,位置在该数据图的左上角的箭头所示处
加入这么一段代码输出到达(4,3)的路径看看为什么
if (xx == 5 && yy == 3 && t.x == 4 && t.y == 3) {
printf("@@@@@\n");
tt = t.op;
for (int j = 0; j < tt.size(); j++) {
cout << mp[tt[j].first] << " " << tt[j].second << " ";
}
printf("@@@@@\n");
}@@@@@
下 1 下 3 右 4 下 6 右 6 @@@@@
@@@@@
下 1 下 3 右 4 右 4 下 4 @@@@@
@@@@@
有2个路径到达(4,3),一条花费6,另一条花费4
按照记忆化搜索的思想,应该是花费4的路径保留,为什么最终输出路径的却是花费6的这条路径?而且这条路径上的dp [ 4 ] [ 3 ] \big[4\big]\big[3\big] [4][3]从6变成了4,导致从(4,3)到(5,3)的输出结果显示6 下 6 下
仔细思考,bfs的遍历方式是层次遍历,经过相同距离到达的格点会都被遍历一遍然后再向更远处遍历,第二条路径遍历的时候会把dp [ 4 ] [ 3 ] \big[4\big]\big[3\big] [4][3]更新成4,然后第一次的路径会用这个第二条路径更新的dp [ 4 ] [ 3 ] \big[4\big]\big[3\big] [4][3]来继续更新后续格点。所以输出的路径方向虽然是第一条路径的,但是输出的数据却是第二条路径中更优的解。
我们发现了一些问题,但并不能解释这道题为什么WA呢?我虽然路径混用了,但dp [ 4 ] [ 3 ] \big[4\big]\big[3\big] [4][3]的值更新的是对的,不妨碍我得到最终的最优解呀?
这道题的特殊性决定了bfs在某些地方会出现问题,我们看该数据图的右下角的箭头所示处,同样,通过在代码中加入输出操作,得到该箭头上面绿色的格子(20,19)的dp [ 20 ] [ 19 ] \big[20\big]\big[19\big] [20][19]为 33 33 33,该箭头左边红色格子(21,18)的dp [ 21 ] [ 18 ] \big[21\big]\big[18\big] [21][18]为38
从(21,18)到(21,19)应该是将(21,19)变成红色,更新一次dp [ 21 ] [ 19 ] \big[21\big]\big[19\big] [21][19],从(20,19)到(21,19)是将(21,19)变成绿色,更新dp [ 21 ] [ 19 ] \big[21\big]\big[19\big] [21][19]得到35覆盖原来的值。
接下来错误发生了,(21,18)到(21,19)到(21,20)的路径会使用更新后的dp [ 21 ] [ 19 ] = 35 \big[21\big]\big[19\big]=35 [21][19]=35来继续搜索,而(21,19)和(21,20)都是红色!!!不需要+1的花费,dp [ 21 ] [ 19 ] = 35 \big[21\big]\big[19\big]=35 [21][19]=35是只有当(21,19)是绿色的时候才会更新出来的答案,需要+1的花费!!!这就是为什么我的答案是37,比正确答案少38的原因。
反思总结
这道题中,没有颜色的格点涂成哪种颜色是不确定的,会对之后的结果产生影响,而bfs的遍历方式使得在遍历的过程中会出现互相影响,进而产生不存在的情况发生,从而导致得不到正确答案。而dfs每一次遍历都是直到最后,不会受到其他遍历情况的影响,所以不会出现问题。
所以记忆化搜索多采用bfs。