- 系列文章目录:https://blog.csdn.net/hancoder/category_10106944.html
- 0 sevlet的知识,从上面目录中找
- 1 tomcat的安装与目录结构:https://blog.csdn.net/hancoder/article/details/106765035
- 2 tomcat源码环境搭建: https://blog.csdn.net/hancoder/article/details/113064325
- 3 tomcat架构与参数:https://blog.csdn.net/hancoder/article/details/113065917
- 4 tomcat源码分析:https://blog.csdn.net/hancoder/article/details/113062146
- 5 tomcat调优:https://blog.csdn.net/hancoder/article/details/113065948
在上一部分中为了预备tomcat基础知识,写了半天,不得已结构就只能写到这里了,估计要和源码写到一起了。慢慢看吧
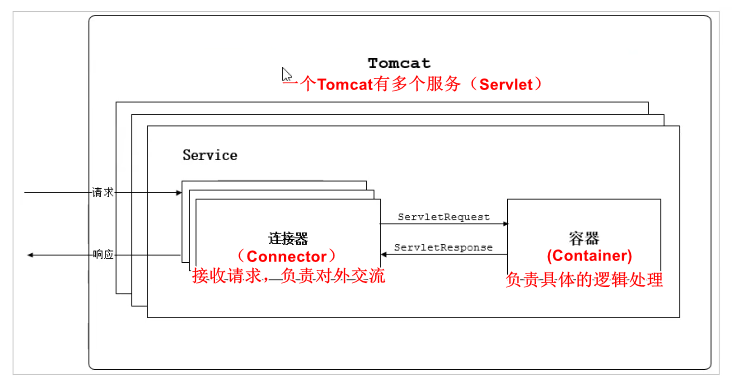
一、tomcat结构
tomcat由两大部分组成:
- 连接器:处理Socket连接,接收请求,负责网络字节流与Request和Response对象的转化。
- servlet容器:加载和管理Servlet,以及具体处理Request请求。
上篇文章https://blog.csdn.net/hancoder/article/details/113065917
介绍过,tomcat里可以有多个service
每个service可以有多个连接器
注意是连接器,不是连接数,连接器获取连接后交给容器,但在这两者内有肯定逻辑
二、连接器
我们在上篇文章中介绍了连接数(https://blog.csdn.net/hancoder/article/details/113065917)
那连接器是什么?
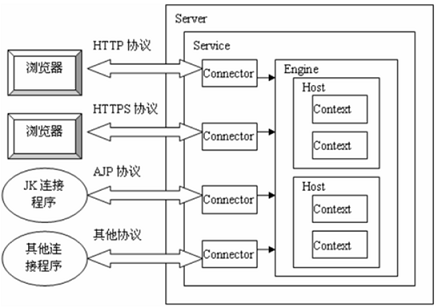
连接器是为了匹配各种协议的,你可以认为每个协议的请求是一个连接器,比如
- HTTP请求是一种连接器
- AJP请求是一种连接器
如图
1 Coyote
Coyote 是Tomcat的连接器的总称,我们要访问tomcat必须经过连接器。
每个连接器在源码里也被称为protocolHandler
下面的话随便看看,无所谓的
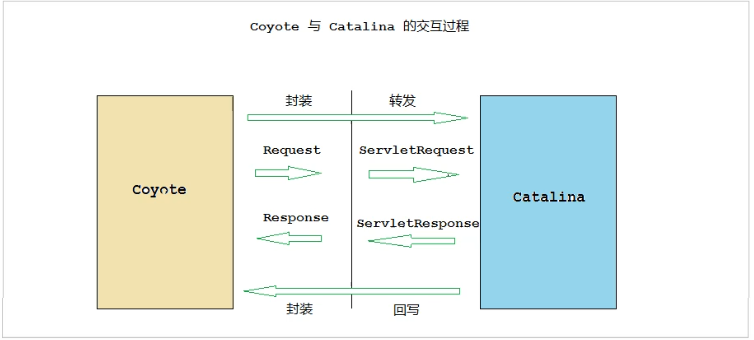
Coyote 封装了底层的网络通信(Socket 请求及响应处理),为Catalina 容器提供了统一的接口,使Catalina 容器与具体的请求协议及IO操作方式完全解耦。Coyote 将Socket 输入转换封装为 Request 对象,交由Catalina 容器进行处理,处理请求完成后, Catalina 通过Coyote 提供的Response 对象将结果写入输出流 。
Coyote 作为独立的模块,只负责具体协议和IO的相关操作, 与Servlet 规范实现没有直接关系,因此即便是 Request 和 Response 对象也并未实现Servlet规范对应的接口, 而是在Catalina 中将他们进一步封装为
ServletRequest和ServletResponse。
2 连接器与容器的关系
连接器用于获取连接,由tcp协议封装成http,生成request请求,然后用适配器把request请求转成servlet request请求,交给容器
- catalina就是servlet container容器
- coyote就是连接器的封装
3 连接器的组成
3.0 梳理
我们在之前的学习中知道了:
- 每个service可以有多个连接器
- 每个连接器在源码中叫ProtocolHandler(协议处理器)
- 每个连接器处理不同类型的请求,也就是说ProtocolHandler处理不同类型的请求
- 如http、AJP
- 每个连接器是一种协议类型,但是又分为多种通信方式,如
- BIO
- NIO
- NIO2
- APR
- 通过协议和通信方式的组合,我们可以又把连接器分得更细了
Http11Protocol:11代表是http1.1Http11NioProtocol
3.1 NIO套娃到连接器
在这里我要用NIO的知识对应到连接器源码中
我在上篇文章说过bind(addr,backlog)的问题,backlog是阻塞的个数,在源码中叫Accept[backlog]
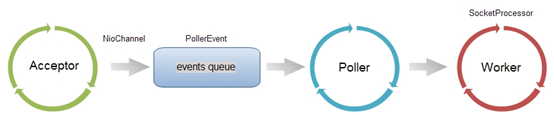
Acceptor
Acceptor定义在AbstractEndpoint类中,他实现了Runnable,是个线程
源码中Accept[backlog]什么意思:就是说创建几个线程执行accept(),serverSock.accept();这个逻辑可以在NioEndpoint的子类Acceptor.run()中看到【他继承了AbstractEndpoint中的Acceptor,实现了run()】
学过NIO的都知道他的意思吧,他是接收客户端的socket,然后去读数据。
与之前NIO有点不同的是,我们之前把serversocket注册到了selector,accept()方法也是selector通过时间知道,但tomcat中我看单独线程accept(),接收到后才注册到selector,selector只发送读写事件。
最大队列问题之前解释过了,达到最大连接数后,进去等待队列(这个等待队列有点线程池等待队列的意思,但因为有selector的关系,又感觉不全是)。等待队列满了之后再accept()到连接后,还没注册到selector上了,就阻塞了,不让注册了,直到等待队列空出来。所以说tomcat的最大连接数是maxConnections+maxAcceptors
Poller
poller对应在NIO中的selector,因为在Poller的构造器中有一句this.selector = Selector.open()
另外poller还是一个线程,实现了Runnable接口,也就是说让每个线程去执行select()操作
从acceptor获取到的socket都注册到selector上,就是注册到了poller上,poller进行select()得到发生事件的key
另外,源码中poller也是有数组的,源码中默认是new Poller[2],对应到前面连接器的不同协议,如HTTP和AJP
processor
processor就是当select()得到发生事件的key后,比如有多个socket有read事件,我们不能让他们在一个线程里一次执行吧?我们把每个socket.read()放到线程池里执行。
这时候需要包装socket.read()这个操作,把每个任务包装为了processor线程。
processor线程包装的时候,是可以从缓存中拿别人用过的processor对象的。
让processor去线程池里执行processor.doRun(),里面会执行processor.process()
线程池Executor
在service标签中,配置了一个线程池参数,他是多个Poller共享的,也就是多个连接器共享的,然后我们可以自己写executor标签后,让connector标签引用它,这样每个连接器就有了自己的线程池。
然后去理解一下这张图,看看能理解不
3.2 组成(术语)
上面的acceptor、poller都是被封装到endpoint中的,processor我们认为是线程池即可
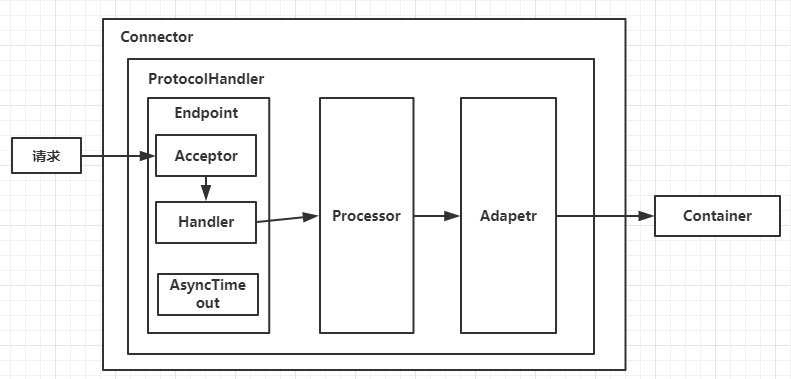
Endpoint、Processor、Adapter
其中ProtocolHandler(连接器)又含了三个部件:Endpoint、Processor、Adapter。
Endpoint:用来处理底层Socket的网络连接。- Endpoint的抽象实现AbstractEndpoint里面定义的
Acceptor和AsyncTimeout两个内部类和一个Handler接口。 - Acceptor用于监听请求,
- AsyncTimeout用于检查异步Request的超时,
- Handler(某种程度上是poller)用于处理接收到的Socket,在内部调用Processor进行处理。
- Endpoint的抽象实现AbstractEndpoint里面定义的
Processor:用于将Endpoint接收到的Socket封装成Request。他是一个线程池,我们每个【发生事件的连接】去线程池里去执行Adapter:线程池里的连接为了去找container,他拿的是request,但是容器接收的是http request,那适配器就转一下- 将Request交给Container进行具体的处理。
另外还有一个术语
ProtocolHandler
就是每个连接器,有了协议加上处理器。
ProtocolHandler: Coyote 协议接口, 通过Endpoint + Processor, 实现针对具体协议的处理能力。
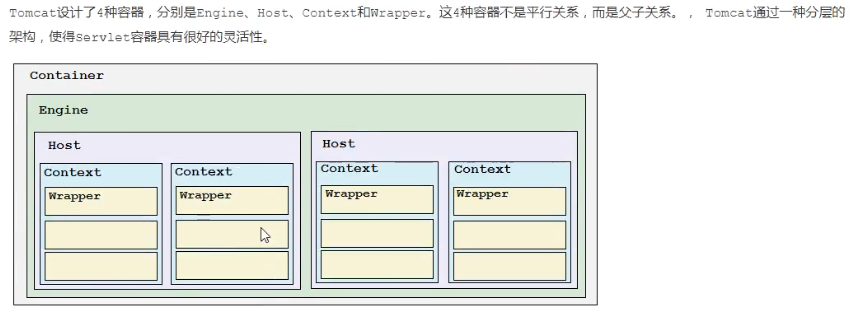
三、容器
在上篇文章中,我们介绍了tomcat的四大容器:EHCW
连接器拿个http request对象来找对应的servlet,要去调用service()方法。在上篇文章介绍了pipeline的关系,这里也不说了。简单说几句去看源码吧
四、源码
1 生命周期
要读源码,先要知道生命周期
在同期中的很多对应Server、Service、Engine、Host、Context都是有声明周期的,所以定义了一个接口LifeCycle.
他们主要有如下方法
-
- init():初始化组件
- 2)start():启动组件
- 3)stop():停止组件
- 4)destroy():销毁组件
实现关系:
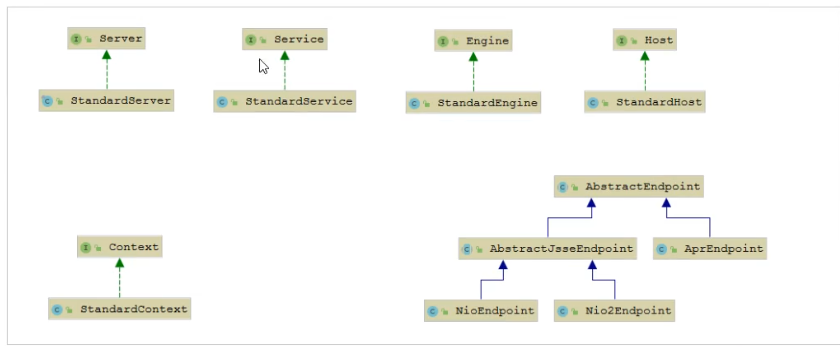
再看看我的源码UML图,执行的过程都是init和start方法的结果。
2 UML
https://www.processon.com/view/link/600c2299637689349033bc53
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-QjObvuef-1611431360425)(http://assets.processon.com/chart_image/600ad5bae401fd0332dec095.png)]
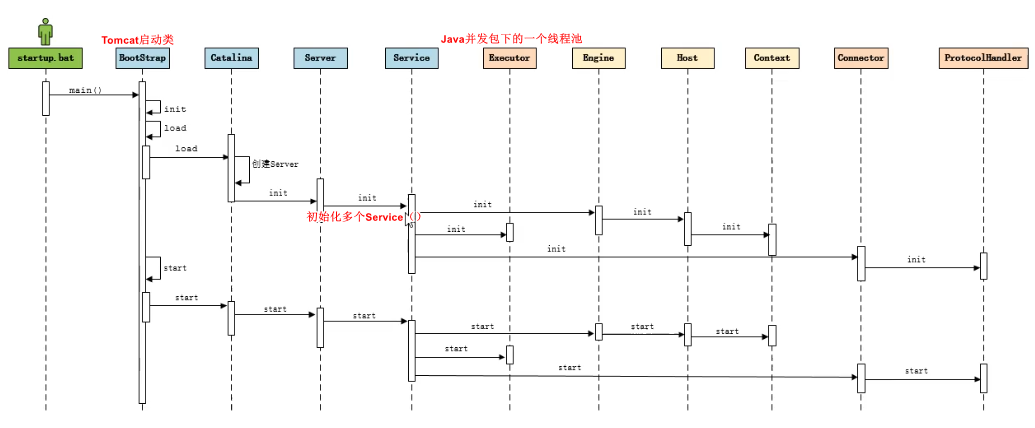
可以看看黑马的tomcat教程,别的教程不太推荐,感觉没讲到点上
3 bootstrap
bootstrap是tomcat的主类,也就是有main()。
4 init
init方法像递归一样调用,最后的结果是读取了xml文件,创建了一些对象,然后去执行start方法
5 start
还是看我的UML 吧,都写到里面了。
https://www.processon.com/view/link/600c2299637689349033bc53
递归调用start(),但是start()方法都在抽象类里,但是抽象类里调用的startInternal()是每个子类实现了的。
我们会在最后Endpoint类的start方法里看到如下的逻辑
- 创建连接器poller线程池,poller是守护线程,他是在执行
select()看看有没有事件。有事件poller就去执行processor.doRun()方法 - acceptor也是在执行自己的内容,他在
accept()
上面是源码tomcat启动的内容
如果来了连接,他就先被accept(),然后被注册到poller,然后select()到事件,去线程池执行。然后后是下面管道和过滤器。
贴一下管道和过滤器的关系
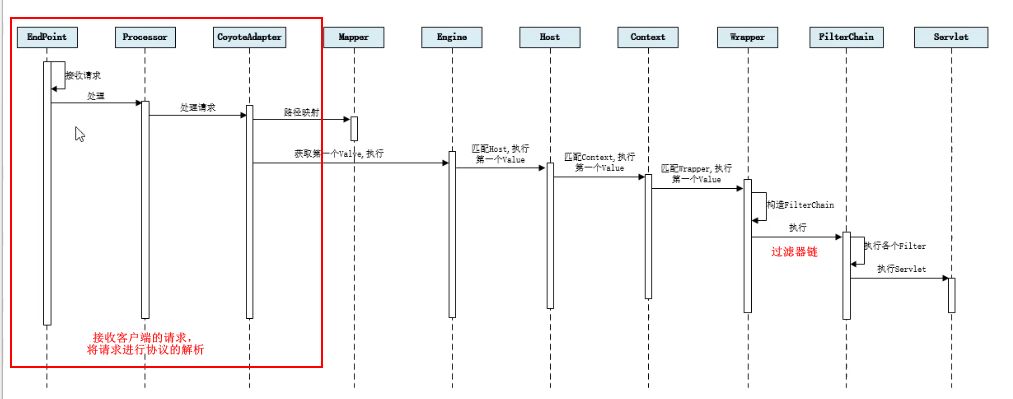
service()方法是在过滤器中执行的。
五、88
晚4点了,88了,毕业就业压力大喔