CPU
1:uptime:检查负载平均数以确认CPU负载是随时间上升还是下降,负载平均数超过了CPU核数通常代表CPU饱和.(一分钟, 五分钟, 十五分钟)
2: vmstat 虚拟内存统计信息, eg: vmstat -w (-w看的更清楚些)1 其中最后几列打印了系统全局范围的CPU平均负载. r 第一列标识可运行线程总数. 其中cs标识CPU上下文次数
[root@HikvisionOS logs]# vmstat
procs -----------memory---------- —swap-- -----io---- -system-- ------cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
67 0 295680 616404 28 29359808 0 0 2 43 0 1 16 21 62 0 0
3: pidstat -u -p 167647 1
4: pidstat -u -t(显示各线程的cpu统计)-p 12617 1
5: mpstat -P ALL 1 //打印每个CPU的报告, 多处理统计信息工具 %usr %sys %idle 三者加起来100%, 其中如果%usr +%sys等于100%表明CPU负荷高
6:CPU性能之Linux 的load average
7: perf top –p pid
其中 : load average表示:有多少进程在等待被CPU调度(进程等待队列的长度), 并不能反应cpu的利用率, 只是表明CPU负载情况
文件I/O
1 :iostat -d -x -k 1
iostat -dxkzt -p sda 1 指定磁盘
2:pidstat -d -p 49766 1 指定进程IO
pidstat -d 1 //显示所有进程占用磁盘io情况
kB_rd/s:每秒从磁盘读取的KB
kB_wr/s:每秒写入磁盘KB
kB_ccwr/s:任务取消的写入磁盘的KB。当任务截断脏的pagecache的时候会发生。
COMMAND: task的进程名
3: iotop –bod 5 5秒钟滚屏输出, 可检测服务器总体io及各个进程io的情况
4: sar -d 1 各个磁盘io监控
内存
1 : pmap -xp pid pmap命令用于报告进程的内存映射关系
2: sar -B 检查pgscan 寻找连续的页扫描(超过10秒), 它是内存压力的预兆
3:vmstat: 检查si, so 列, 如果一直非0, 那么系统正存在内存压力. 指交换匿名换页, 每秒运行vmstat检查free列的可用内存. 单位KB, swpd:交换出的内存量, free:空闲的可用内存, buff:用于缓冲缓存的内存,
4: free –m 可用内存= free的内存+cached的内存 + buffers的内存;
5 : top top -p pid 产看指定进程, top -Hp pid查看指定进程中的各个线程的性能占用情况
网卡
查看TCP参数命令: sysctl -a |grep tcp sysctl -a |grep ipv4
查看tcp/ipv4的系统配置
lsof 按照进程ID列出包括套接字细节在内的打开的文件
ss:套接字统计信息
iftop: 按主机总结网络接口吞吐量
traceroute: 查看到目的地的路由, 开源需要安装
ip : 网络接口统计信息
nicstat : 网络接口吞吐量和使用率
sar : 统计历史信息
netstat -I=eno2 1
nestat -s
ifconfig eno2: 检测网卡错误, 丢弃, 超限统计信息.
nc : 网络测试的瑞士军刀, nc可快速建立网络连接, 即可以客户端方式运行, 也可以以服务端方式运行, 还可以通过-x, 测试网络代理
nload: 用于查看linux网络流量状况,实时输出。可以理解为是一个控制台应用程序,用来实时监测网络流量和带宽使用情况的命令
Valgrind 之 callgrind
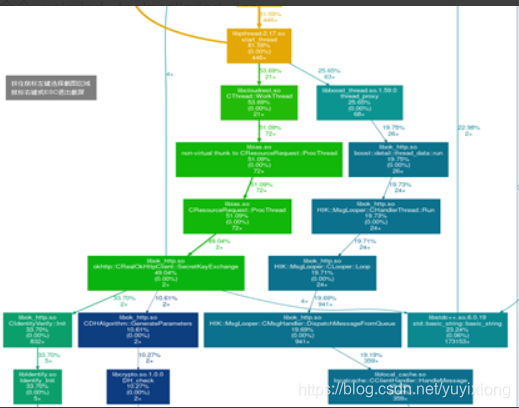
CPU: callgrind 检测CPU占用中接口调用链图
使用方法:
1 :valgrind 工具callgrind, 命令: valgrind –tool=callgrind ./ias
2 :生成CPU接口调用链图 : 生成out文件后, 使用命令 python gprof2dot.py -f callgrind -n10 -s callgrind.out.111841| dot -Tpng -o test113.png
备注: 执行上述命令前需要先获取下面两个文件, 将py脚本文件放在callgrind调试的目录下, 然后修改服务器的镜像文件, yum install graphviz
dot 工具介绍:
dot工具需要安装graphviz, 修改服务器的镜像文件/etc/yum.repos.d/CentOS-Base.repo dot是graphviz的子工具
效果图:
CentOS-Base.repo
gprof2dot.py
Perf
CPU: perf 生成CPU火焰图, 查看接口占用CPU时间片占比
1:perf record -a -g -p 27867 – sleep 60(60秒, 一般可以调大) 调试
2:https://github.com/brendangregg/FlameGraph来获取。下载后工具后,使用命令cd FlameGraph/切换到工具目录下,执行下面的命令,就可以直接生成火焰图
3:perf script -i …/perf.data | ./stackcollapse-perf.pl --all | ./flamegraph.pl > ksoftirqd.svg
也可利用 perf top -p pid 看服务中哪个接口占用cpu最高
火焰图:

FlameGraph-master.zip
Unixbench/Lmbench
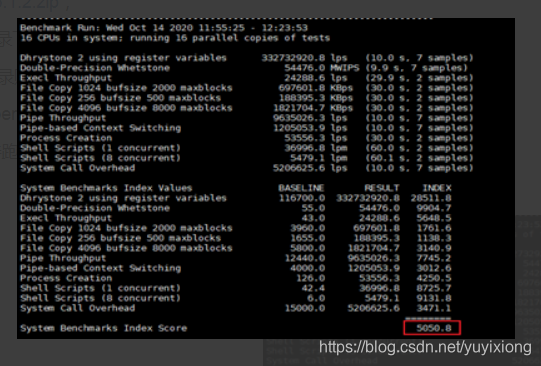
Unixbench/Lmbench工具是一款服务器综合性能检测工具 ,可以检测服务器性能如下截图:
其中unixbench给出一个综合服务器的跑分结果, lmbench则可以通过命令检测服务器各个性能, 比如带宽, 内存, 网络, 上下文等等
Lmbench工具可以参看官网资料, 非常详细:
http://www.bitmover.com/lmbench/lmbench.html#TOC
unixbench使用步骤:
1、下载工具unixbench-5.1.2.zip;
2、将工具解压到任意目录下,命令: unzip unixbench-5.1.2.zip ;
3、给unixbench-5.1.2目录赋可执行权限:cd到当前目录,然后chmod -R 777 *
4、进入到解压后的unixbench-5.1.2目录,直接执行make命令;
5、然后执行./Run,等待跑分结果,大约半小时完成
分析结果效果图: