最近接触到一个很棒的自然语言处理工具——AllenNLP,解决了很多在自然语言处理过程中遇到的痛点问题,开发这个工具也是鼎鼎大名的A2I实验室,然后就去拜读了他们在github上分享的文档(当然,对于本英语渣来说,如果不是中文资料实在是比较少,是不会开启左百度右谷歌模式的),发觉这个框架!真tm棒!后面在打造自己的工作箱时,越发觉得allennlp的工程思维值得每个nlper学习,因此决定深度去阅读其中优雅的代码以及官方文档,并将其记录下来。
为什么值得研究
工欲善其事,必先利器。在进行自然语言处理的过程中,有个大家都知道的梗–“语料准备3小时,训练模型3分钟”。一般的处理nlp task的流程如下:
- 拿到原始文本
- 预处理,将文本切成词或者字
- 将文本转换为index
- 将文本向量化
- 编码分布式表示
- 解码出最终的输出
- 进行训练
在进行这样的自然语言处理的过程中,我们在不同的任务中重复了很多工作,如读取和缓存,预处理循环,NLP中的padding,各种预训练向量。尽管神经网络在各种任务上都取得了显著的性能提升,但在调整新模型或复制现有结果方面,仍可能存在困难,如模型需要一定训练时间,同时对初始化和超参数设置很敏感。相信不少同学在调整了参数后,需要分析对比结果吧,我之前用fasttext训练一个分类任务,还是用的原始的excel记录下来每个参数的变动对分类效果的影响。
AllenNLP的出现,就是为了帮助nlper可以更快的验证自己的idea,将双手从重复的劳动中解放出来,其优势如下:
- 模块化的框架,集成了不少通用的数据处理模块和算法模块,同时具有拓展性。
- 使用json配置文件的方式使实验的调整更为方便
- 拥有灵活的数据API,可以进行智能的batching和padding
- 拥有在文本处理中常用操作的高级抽象
模块概览
| 模块名称 | 作用 |
|---|---|
| commands | 实现命令行功能 |
| common | 一些通用函数,如读取参数,注册 |
| data | 数据处理 |
| interpret | 用于解释模型的结果,包括显著性图与对抗攻击 |
| models | 抽象模型,类似于模板,还包含了分类与标注两个具体模型 |
| modules | pytorch用在处理文本上的模块集合,做了比较好的封装,作为组件被用于models |
| nn | 张量实用函数集合,例如初始化函数和激活函数 |
| predicators | 模型预测 |
| tools | 一些实用的脚本 |
| training | 模型训练 |
框架概览
AllenNLP是基于pytorch进行开发的,其基本的pipline包含以下组件:
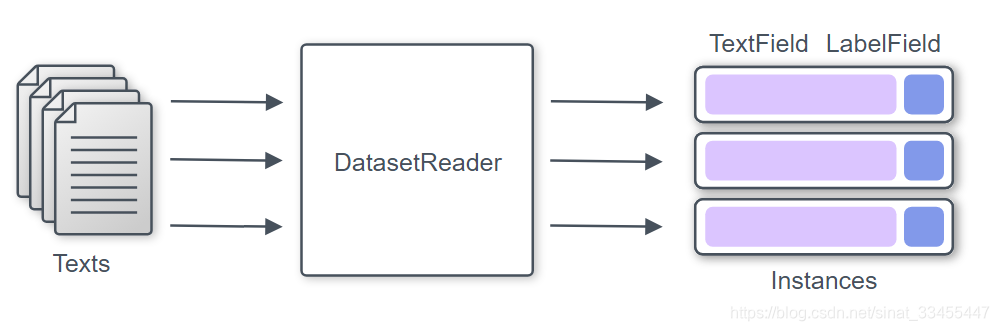
DatasetReader,读数据模块,在不同文件中抽取必要的信息,在使用的时候通过重写_read方法来实现数据集的读取,输出Instance的集合。其中这个Instance是由一个或多个字段组成,其中每个字段代表模型用作输入或输出的一条数据,字段将转换为张量并馈入模型。比如分类任务,它的输入与输出十分简单,其Instance由TextField与LabelField组成,TextField为输入的文本,LabelField为输出的标签。
Model,抽象模型模块,表示将被训练的模型。该模型将使用一批Instance,预测其输出并计算loss。拿分类任务来说,模型需要做的事情如下:对于每个词表示为特征向量,将词级向量组合成文档级特征向量,对于文档级别的特征向量进行分类。在分类模型的构造函数中,需要指定Vocabulary,其管理词汇表项(例如单词和标签)及其整数ID之间的映射;embedder如TextFieldEmbedder,获得初始化的词向量,其输出形状为(batch_size,num_tokens,embedding_dim);encoder如Seq2VecEncoder,将序列token向量压缩成一个向量,形状为 (batch_size, encoding_dim) ;最后加一个分类层,它可以将encoder的输出转换为logits,每个标签可能分类到的值(可以理解为未归一化的概率 )。 这些值将在以后转换为概率分布,并用于计算损失。接下来需要编写forward()方法,该方法实现接受输入,生成预测结果,并计算损失的功能。

Trainer,功能为处理训练与评估指标记录,负责连接必要的组件(包括模型,优化器,实例,数据加载器等)并执行循环训练。通过设置serialization_dir来保存模型与日志。Predictor,从原始文本中生成预测结果,主要流程为获得Instance的json表示,转换为Instance,喂入模型,并以JSON可序列化格式返回预测结果。
安装方法
适用版本为allennlp 1.2.2,安装命令如下:
# 首先安装torch环境
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple torch==1.6.0 torchvision==0.6.1 -f https://download.pytorch.org/whl/torch_stable.html
# 安装allennlp
pip install allennlp
# 如果出现Microsoft Visual C++ Redistributable is not installed, this may lead to the DLL load failure.的错误,安装VC_redist.x64即可,下载位置如下:
https://aka.ms/vs/16/release/vc_redist.x64.exe
官方入门demo试运行
首先准备好一些样例数据,如下:
I like this movie a lot! positive
This was a monstrous waste of time negative
AllenNLP is amazing positive
Why does this have to be so complicated? negative
This sentence expresses no sentiment positive
代码如下:
from typing import Dict, Iterable, List, Tuple
import torch
import allennlp
from allennlp.common import JsonDict
from allennlp.data import DataLoader, PyTorchDataLoader, DatasetReader, Instance
from allennlp.data import Vocabulary
from allennlp.data.fields import LabelField, TextField
from allennlp.data.token_indexers import TokenIndexer, SingleIdTokenIndexer
from allennlp.data.tokenizers import Token, Tokenizer, WhitespaceTokenizer
from allennlp.models import Model
from allennlp.modules import TextFieldEmbedder, Seq2VecEncoder
from allennlp.modules.text_field_embedders import BasicTextFieldEmbedder
from allennlp.modules.token_embedders import Embedding
from allennlp.modules.seq2vec_encoders import BagOfEmbeddingsEncoder
from allennlp.predictors import Predictor
from allennlp.nn import util
from allennlp.training.metrics import CategoricalAccuracy
from allennlp.training.trainer import Trainer, GradientDescentTrainer
from allennlp.training.optimizers import AdamOptimizer
class ClassificationTsvReader(DatasetReader):
def __init__(self,
lazy: bool = False,
tokenizer: Tokenizer = None,
token_indexers: Dict[str, TokenIndexer] = None,
max_tokens: int = None):
super().__init__(lazy)
self.tokenizer = tokenizer or WhitespaceTokenizer()
self.token_indexers = token_indexers or {
'tokens': SingleIdTokenIndexer()}
self.max_tokens = max_tokens
def text_to_instance(self, text: str, label: str = None) -> Instance:
tokens = self.tokenizer.tokenize(text)
if self.max_tokens:
tokens = tokens[:self.max_tokens]
text_field = TextField(tokens, self.token_indexers)
fields = {
'text': text_field}
if label:
fields['label'] = LabelField(label)
return Instance(fields)
def _read(self, file_path: str) -> Iterable[Instance]:
with open(file_path, 'r') as lines:
for line in lines:
text, sentiment = line.strip().split('\t')
yield self.text_to_instance(text, sentiment)
class SimpleClassifier(Model):
def __init__(self,
vocab: Vocabulary,
embedder: TextFieldEmbedder,
encoder: Seq2VecEncoder):
super().__init__(vocab)
self.embedder = embedder
self.encoder = encoder
num_labels = vocab.get_vocab_size("labels")
self.classifier = torch.nn.Linear(encoder.get_output_dim(), num_labels)
self.accuracy = CategoricalAccuracy()
def forward(self,
text: Dict[str, torch.Tensor],
label: torch.Tensor = None) -> Dict[str, torch.Tensor]:
# Shape: (batch_size, num_tokens, embedding_dim)
embedded_text = self.embedder(text)
# Shape: (batch_size, num_tokens)
mask = util.get_text_field_mask(text)
# Shape: (batch_size, encoding_dim)
encoded_text = self.encoder(embedded_text, mask)
# Shape: (batch_size, num_labels)
logits = self.classifier(encoded_text)
# Shape: (batch_size, num_labels)
probs = torch.nn.functional.softmax(logits)
output = {
'probs': probs}
if label is not None:
self.accuracy(logits, label)
# Shape: (1,)
output['loss'] = torch.nn.functional.cross_entropy(logits, label)
return output
def get_metrics(self, reset: bool = False) -> Dict[str, float]:
return {
"accuracy": self.accuracy.get_metric(reset)}
def get_metrics(self, reset: bool = False) -> Dict[str, float]:
return {
"accuracy": self.accuracy.get_metric(reset)}
def build_dataset_reader() -> DatasetReader:
return ClassificationTsvReader()
def read_data(
reader: DatasetReader
) -> Tuple[Iterable[Instance], Iterable[Instance]]:
print("Reading data")
training_data = reader.read("data/train.tsv")
validation_data = reader.read("data/dev.tsv")
return training_data, validation_data
def build_vocab(instances: Iterable[Instance]) -> Vocabulary:
print("Building the vocabulary")
return Vocabulary.from_instances(instances)
def build_model(vocab: Vocabulary) -> Model:
print("Building the model")
vocab_size = vocab.get_vocab_size("tokens")
embedder = BasicTextFieldEmbedder(
{
"tokens": Embedding(embedding_dim=10, num_embeddings=vocab_size)})
encoder = BagOfEmbeddingsEncoder(embedding_dim=10)
return SimpleClassifier(vocab, embedder, encoder)
def build_data_loaders(
train_data: torch.utils.data.Dataset,
dev_data: torch.utils.data.Dataset,
) -> Tuple[allennlp.data.DataLoader, allennlp.data.DataLoader]:
# Note that DataLoader is imported from allennlp above, *not* torch.
# We need to get the allennlp-specific collate function, which is
# what actually does indexing and batching.
train_loader = PyTorchDataLoader(train_data, batch_size=1, shuffle=True)
dev_loader = PyTorchDataLoader(dev_data, batch_size=1, shuffle=False)
return train_loader, dev_loader
def build_trainer(
model: Model,
serialization_dir: str,
train_loader: DataLoader,
dev_loader: DataLoader
) -> Trainer:
parameters = [
[n, p]
for n, p in model.named_parameters() if p.requires_grad
]
optimizer = AdamOptimizer(parameters)
trainer = GradientDescentTrainer(
model=model,
serialization_dir=serialization_dir,
data_loader=train_loader,
validation_data_loader=dev_loader,
num_epochs=5,
optimizer=optimizer,
)
return trainer
def run_training_loop():
dataset_reader = build_dataset_reader()
# These are a subclass of pytorch Datasets, with some allennlp-specific
# functionality added.
train_data, dev_data = read_data(dataset_reader)
vocab = build_vocab(train_data + dev_data)
model = build_model(vocab)
# This is the allennlp-specific functionality in the Dataset object;
# we need to be able convert strings in the data to integers, and this
# is how we do it.
train_data.index_with(vocab)
dev_data.index_with(vocab)
# These are again a subclass of pytorch DataLoaders, with an
# allennlp-specific collate function, that runs our indexing and
# batching code.
train_loader, dev_loader = build_data_loaders(train_data, dev_data)
# You obviously won't want to create a temporary file for your training
# results, but for execution in binder for this guide, we need to do this.
serialization_dir = 'result/20201202'
trainer = build_trainer(
model,
serialization_dir,
train_loader,
dev_loader
)
trainer.train()
return model, dataset_reader
class SentenceClassifierPredictor(Predictor):
def predict(self, sentence: str) -> JsonDict:
return self.predict_json({
"sentence": sentence})
def _json_to_instance(self, json_dict: JsonDict) -> Instance:
sentence = json_dict["sentence"]
return self._dataset_reader.text_to_instance(sentence)
# We've copied the training loop from an earlier example, with updated model
# code, above in the Setup section. We run the training loop to get a trained
# model.
model, dataset_reader = run_training_loop()
vocab = model.vocab
predictor = SentenceClassifierPredictor(model, dataset_reader)
output = predictor.predict('A good movie!')
print([(vocab.get_token_from_index(label_id, 'labels'), prob)
for label_id, prob in enumerate(output['probs'])])
output = predictor.predict('This was a monstrous waste of time.')
print([(vocab.get_token_from_index(label_id, 'labels'), prob)
for label_id, prob in enumerate(output['probs'])])
运行结果如下:
[('positive', 0.307565301656723), ('negative', 0.6924346685409546)]
[('positive', 0.4760109782218933), ('negative', 0.5239890813827515)]
以上,一个简单的2分类实验就结束了。后面的文章将对AllenNLP进行流程细读。
参考资料