因为全网几乎都搜不到有关paddlelite基于python API的完整部署项目,只有一些资料极不全,也跑不通的别人的代码,所以这篇博客可以说是全网第一个基于python API部署PaddlePaddle的自定义模型并实现视频流和单张图片完整预测的demo教程。
经过了三天的努力和挣扎,在大佬们的帮助下,同时借鉴了网上有个基于20年智能车人工智能组别的小车标志物识别的代码,最终终于跑通了基于python API的模型部署工作,同时实现了视频流和单张图片的预测功能。需要注意的是,本文目前只实现了Windows端的paddlelite部署,树莓派端因为我的系统是raspbian,运行我训练的模型出现内存不足的报错,所以目前还未实现,接下来我会在ubuntu上进行部署,再加更。
在此特别鸣谢夜雨飘零,帮助我了好多哈哈哈哈,虽然因为他流量没了,不能帮我解决在树莓派端无法部署的问题,但是给了我非常关键的提示和帮助,就是paddle lite在图像输入模型前,需要对图像进行归一化处理,否则模型无法正常处理。
首先需要说的是,Paddle Lite在Windows端和Linux端部署代码基本上没有区别,区别只在于前期环境的配置上,所以大家在不同系统上部署,代码不用发生变化,直接写自己的逻辑代码即可。
部署环境准备
1.Windows端部署环境准备
pip install paddlelite
缺什么pip一下就行。
2.Linux端部署环境准备
直接参考我的博客:
模型文件准备
首先你得有 图像分类 / 目标检测的分类模型,模型文件一般为两种,如图所示:
- 模型格式一:
__model__和__params__文件
 - 模型格式二:单个的
- 模型格式二:单个的.nb文件

python API预测
这个是基于Paddle Lite进行预测的核心函数,这是我自己分的,大家也可以根据自己的情况进行相应的修改,需要注意的是:
- 图像归一化部分必不可少,但是也可以全用CV库做,把PIL库扔掉。
# 加载模型
def create_predictor(model_dir):
config = MobileConfig()
config.set_model_from_file(model_dir)
predictor = create_paddle_predictor(config)
return predictor
#图像归一化处理
def process_img(image, input_image_size):
origin = image
img = origin.resize(input_image_size, Image.BILINEAR)
resized_img = img.copy()
if img.mode != 'RGB':
img = img.convert('RGB')
img = np.array(img).astype('float32').transpose((2, 0, 1)) # HWC to CHW
img -= 127.5
img *= 0.007843
img = img[np.newaxis, :]
return origin,img
# 预测
def predict(image, predictor, input_image_size):
#输入数据处理
input_tensor = predictor.get_input(0)
input_tensor.resize([1, 3, input_image_size[0], input_image_size[1]])
image = Image.fromarray(cv2.cvtColor(image, cv2.COLOR_BGRA2RGBA))
origin, img = process_img(image, input_image_size)
image_data = np.array(img).flatten().tolist()
input_tensor.set_float_data(image_data)
#执行预测
predictor.run()
#获取输出
output_tensor = predictor.get_output(0)
print("output_tensor.float_data()[:] : ", output_tensor.float_data()[:])
res = output_tensor.float_data()[:]
return res
代码的小Tips:
output_tensor.float_data()[:]是模型的预测输出,如果是分类问题,输出的是每个类别对应的概率,最终输出层一般都是Softmax函数,所以大家直接选取概率大的输出即可,可以直接参考我的单张图片预测的代码。- 如果是目标检测问题,一般情况都是label+score+box,一般都是6个参数,当然这只是一个框,如果有多个物体的话你的输出当然就是6*物体个数个输出了,然后可以根据box进行画框处理,并呈现在图像上即可。
单张图片预测
因为我这里做了一个基于PaddleClas的垃圾分类模型,所以只需要输入图片,输出结果即可,如果是目标检测模型的部署,就在输出后还需要处理label、score、point,并在原图上进行画框即可。
from paddlelite.lite import *
import cv2
import numpy as np
import sys
import time
from PIL import Image
from PIL import ImageFont
from PIL import ImageDraw
# 加载模型
def create_predictor(model_dir):
config = MobileConfig()
config.set_model_from_file(model_dir)
predictor = create_paddle_predictor(config)
return predictor
#图像归一化处理
def process_img(image, input_image_size):
origin = image
img = origin.resize(input_image_size, Image.BILINEAR)
resized_img = img.copy()
if img.mode != 'RGB':
img = img.convert('RGB')
img = np.array(img).astype('float32').transpose((2, 0, 1)) # HWC to CHW
img -= 127.5
img *= 0.007843
img = img[np.newaxis, :]
return origin,img
# 预测
def predict(image, predictor, input_image_size):
#输入数据处理
input_tensor = predictor.get_input(0)
input_tensor.resize([1, 3, input_image_size[0], input_image_size[1]])
image = Image.fromarray(cv2.cvtColor(image, cv2.COLOR_BGRA2RGBA))
origin, img = process_img(image, input_image_size)
image_data = np.array(img).flatten().tolist()
input_tensor.set_float_data(image_data)
#执行预测
predictor.run()
#获取输出
output_tensor = predictor.get_output(0)
print("output_tensor.float_data()[:] : ", output_tensor.float_data()[:])
res = output_tensor.float_data()[:]
return res
# 展示结果
def post_res(label_dict, res):
print(max(res))
target_index = res.index(max(res))
print("结果是:" + " " + label_dict[target_index])
if __name__ == '__main__':
# 初始定义
label_dict = {
0:"metal", 1:"paper", 2:"plastic", 3:"glass"}
image = "./test_pic/images_orginal/glass/glass300.jpg"
model_dir = "./trained_model/ResNet50_trash_x86_model.nb"
image_size = (224, 224)
# 初始化
predictor = create_predictor(model_dir)
# 读入图片
image = cv2.imread(image)
# 预测
res = predict(image, predictor, image_size)
# 显示结果
post_res(label_dict, res)
cv2.imshow("image", image)
cv2.waitKey()
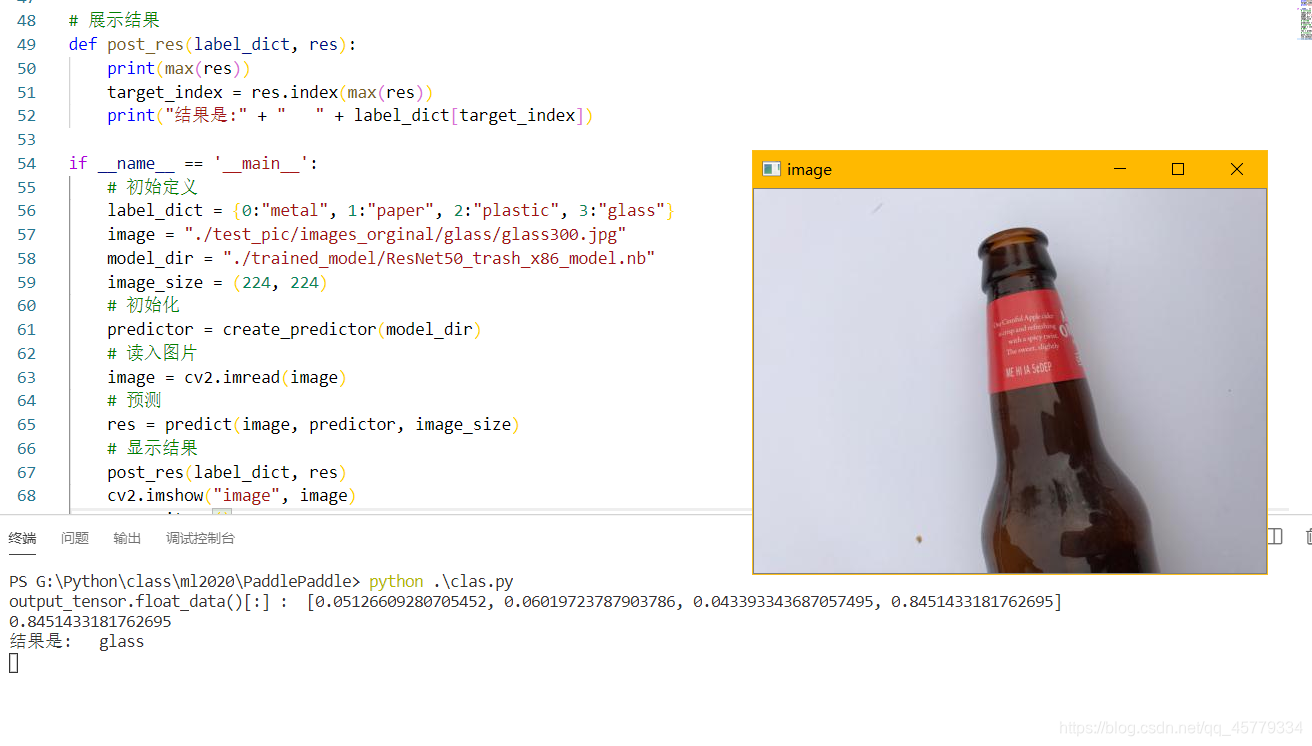
- 效果展示:
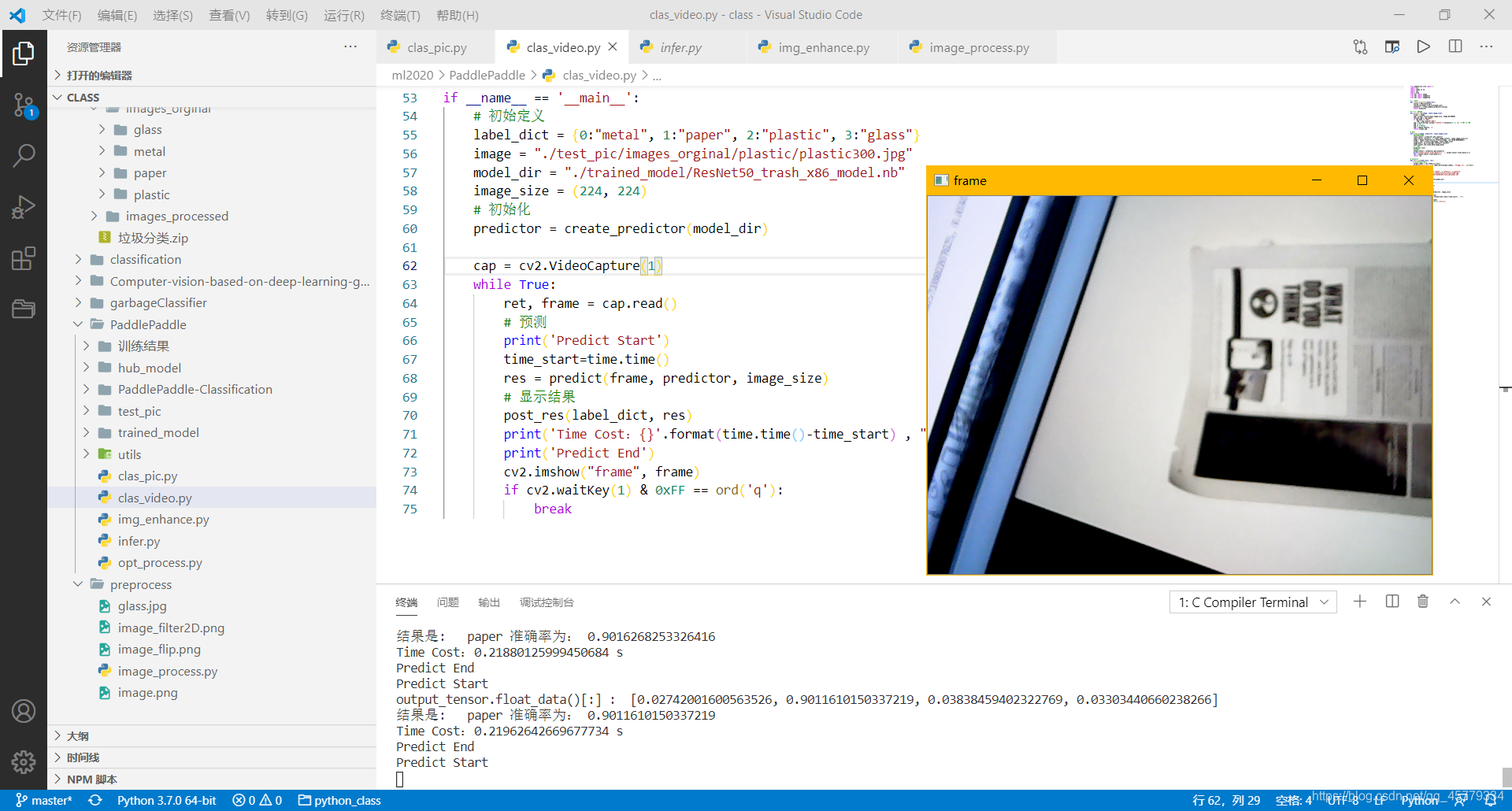
视频流预测
from paddlelite.lite import *
import cv2
import numpy as np
import sys
import time
from PIL import Image
from PIL import ImageFont
from PIL import ImageDraw
# 加载模型
def create_predictor(model_dir):
config = MobileConfig()
config.set_model_from_file(model_dir)
predictor = create_paddle_predictor(config)
return predictor
#图像归一化处理
def process_img(image, input_image_size):
origin = image
img = origin.resize(input_image_size, Image.BILINEAR)
resized_img = img.copy()
if img.mode != 'RGB':
img = img.convert('RGB')
img = np.array(img).astype('float32').transpose((2, 0, 1)) # HWC to CHW
img -= 127.5
img *= 0.007843
img = img[np.newaxis, :]
return origin,img
# 预测
def predict(image, predictor, input_image_size):
#输入数据处理
input_tensor = predictor.get_input(0)
input_tensor.resize([1, 3, input_image_size[0], input_image_size[1]])
image = Image.fromarray(cv2.cvtColor(image, cv2.COLOR_BGRA2RGBA))
origin, img = process_img(image, input_image_size)
image_data = np.array(img).flatten().tolist()
input_tensor.set_float_data(image_data)
#执行预测
predictor.run()
#获取输出
output_tensor = predictor.get_output(0)
print("output_tensor.float_data()[:] : ", output_tensor.float_data()[:])
res = output_tensor.float_data()[:]
return res
# 展示结果
def post_res(label_dict, res):
# print(max(res))
target_index = res.index(max(res))
print("结果是:" + " " + label_dict[target_index], "准确率为:", max(res))
if __name__ == '__main__':
# 初始定义
label_dict = {
0:"metal", 1:"paper", 2:"plastic", 3:"glass"}
model_dir = "./trained_model/ResNet50_trash_x86_model.nb"
image_size = (224, 224)
# 初始化
predictor = create_predictor(model_dir)
cap = cv2.VideoCapture(0)
while True:
ret, frame = cap.read()
# 预测
print('Predict Start')
time_start=time.time()
res = predict(frame, predictor, image_size)
# 显示结果
post_res(label_dict, res)
print('Time Cost:{}'.format(time.time()-time_start) , "s")
print('Predict End')
cv2.imshow("frame", frame)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
- 效果展示: