聚类算法原理简介
聚类概念
聚类涉及到数据点的分组,给定一组数据点,我们可以根据聚类算法将每个数据点划分为一个特定的组。同一组中的数据点应该具有相似的属性或特征,不同组中的数据点应该具有高度不同的属性或特征。聚类是一种无监督机器学习的方法(没有标签),或许多领域中常用的统计数据分析技术有时候作为监督学习中稀疏特征的预处理,有时候可以作为异常值检测。
应用场景:新闻聚类、用户购买模型(交叉销售)、图像与基因技术等。聚类的难点有评估和调参等(无标签)。
K-means算法
k-means是无监督机器学习,就在在没有任何监督信号的情况下,将数据分为k份的一种方法
要得到簇的个数,需要指定K值(簇的个数);
质心:均值,即向量各维取平均即可
距离的度量:常用欧式距离和余弦距离(对数据先标准化)
优化目标:
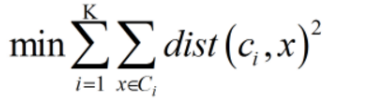
工作流程

(1)指定K的值,随机初始化两个质心(b)
(2)遍历所有样本点(a),分别计算样本点到两个质心的距离并进行聚类(c)
(3)根据聚类的结果更新质心的位置(d)
(4)重新遍历样本点计算到质心的距离并进行聚类(e)
(5)不断更新并聚类直到质心的位置不再发生明显的变化为止(f)
优势:简单快速适合常规数据集
劣势:
1. K值难确定,复杂度与样本程线性关系,很难发现任意形状的簇
2. k-means是局部最优的,容易受到初十质心的影响
解决办法:二分k-means算法,对初始质心的选择不太敏感,因为初始时只选择一个质心

k-means的细节问题
- k值怎么定,我们怎么知道应该分几类
没有确定的做法,分几类主要取决于个人的经验和感觉,通常的做法是多尝试几个k值,看分成几类的结果更好解释,更符合分析目的等或者可以把各种k值算出的SSE作比较,取最小的SSE的k值 - 初始的k个质心怎么选
通常就是随机选,初始质心的选取对最终聚类结果有影响,因此算法一定要多执行几次,那个结果更reasonable就用那个结果。
当然也有一些优化的方法:
第一种是选择彼此距离最远的点,具体来说就是先选第一个点,然后选离第一个点最远的当第二个点,然后选第三个点,第三个点到第一、第二两点的距离之和最小,以此类推
第二种是先根据其他聚类算法(如层次聚类)得到聚类结果,从结果中每个分类选取一个点 - k-means会不会陷入一直选质心的过程,永远停不下来
不会,有数学证明K-Means一定会收敛,大致思路是根据SSE(误差平方和)的概念,即每个点到自身所归属质心的距离的平方和,这个平方和是一个函数,然后可以证明这个函数式最终收敛的函数。 - 判断每个点归属那个质心距离怎么算
第一种:欧几里德距离: 后 续 补 充 \frac{后续}{补充} 补充后续
第二种:余弦相似度:余弦相似度用向量空间中两个向量夹角的余弦值作为衡量两个个体差异的大小,相比距离度量,余弦相似度更加注重两个向量在方向上的差异,而非距离或长度上。
还有其他一些计算距离的方法,但都是欧氏距离和余弦相似度的衍生,明可夫斯基距离、切比雪夫距离、曼哈顿距离、马哈拉诺比斯距离、调整后的余弦相似度、Jaccard相似系数… - 大家的单位要一致
- 每一轮迭代如何选取新的质心
各个维度的算术平均,比如(x1,y1,z1)、(x2,y2,z2)、(x3,y3,z3),那新的质心就是[(x1+x2+x3)/3,(y1+y2+y3)/3,(z1+z2+z3)/3],*这里要注意,新质心不一定是实际的一个数据点 - 关于离群值
离群值就是远离整体的、非常异常、非常特殊的数据点,在聚类之前应该将这些"极大"、"极小"之类的离群数据都去掉,否则会对于聚类的结果有影响。但是离群值往往自身就很有分析的价值、可以把离群值单独作为一类来分析。 - 用SPSS做出的k-means聚类结果,包含anova(单因素方差分析),是什么意思?
简单说就是判断用于聚类的变量是否对于聚类结果有贡献,方差分析检验结果越显著的变量,说明对聚类结果越有影响。对于不显著的变量,可以考虑从模型中剔除