HashMap的底层数据结构?
HashMap 是我们非常常用的数据结构,由 数组和链表组合构成 的数据结构。数组里每个地方都存了Key-Value这样的实例,在Java7叫Entry,在Java8中叫Node。

初始化后所有的位置都为null,在put插入的时候会根据key的hash去计算一个index值。
链表?为啥需要链表?链表具体是什么样的?
数组的长度是有限的,在有限的长度里面使用哈希,哈希本事就存在一定的概率性,当两个key的hash一样时就会hash到一个值上,形成链表。
每个节点都会有自身的hash、key、value、以及下个节点,Node的源码:
static class Node<K,V> implements Map.Entry<K,V>{
final int hash;
fianl K key;
V value;
Node<K,V> next;
...
}
链表,新的Entry节点在插入链表的时候,是怎么插入的?
Java8之前是头插法,就是说新来的值会取代原有的值,原有的值就顺推到链表中去,因为当时设计这段代码的作者认为后来的值被查找的可能性更大一点,提升查找的效率。
Java8之后,都是采用尾部插入。
为什么改用尾插法?
改用尾插法是因为HashMap的扩容机制,数组容量是有限的,数据多次插入,到一定的数量就会进行扩容,也就是resize。
什么时候resize?
resize的两个条件:
- Capacity:HashMap当前长度。
- LoadFactor:负载因子,默认值0.75f
/**
* The load factor used when none specfified in constructor
*/
static final float FEFAULT_LOAD_FACTOR=0.75f;
简单的理解就是,假如当前容量是100,当存进第76个的时候,判断发现需要进行resize了,那就进行扩容。
HashMap是怎么扩容的?
分两步:
- 扩容:创建一个新的Entry空数组,长度为原数组的2倍。
- Rehash:遍历原Entry数组,把所有的Entry重新Hash到新数组。
为什么不直接复制,为什么需要重新Hash?
因为长度扩大后,Hash的规则也随之改变。
Hash公式:index = HashCode(Key) & (Length-1)
扩容后Length发生了改变,重新计算的index与扩容前明显不一样。
Java8以前用头插法,Java8之后为什么改为尾插法了呢?
先举个例子吧,我们现在往一个容量大小为2的put两个值,负载因子是0.75,我们在put第二个的时候就会进行resize ,现在我们要在容量为2的容器里面用不同线程插入A,B,C,假如我们在resize之前打个断点,那意味着数据都插入了但是还没进行resize那扩容前可能是这样的,我们可以看到链表的指向A->B->C
Tip:A的下一个指针是指向B的
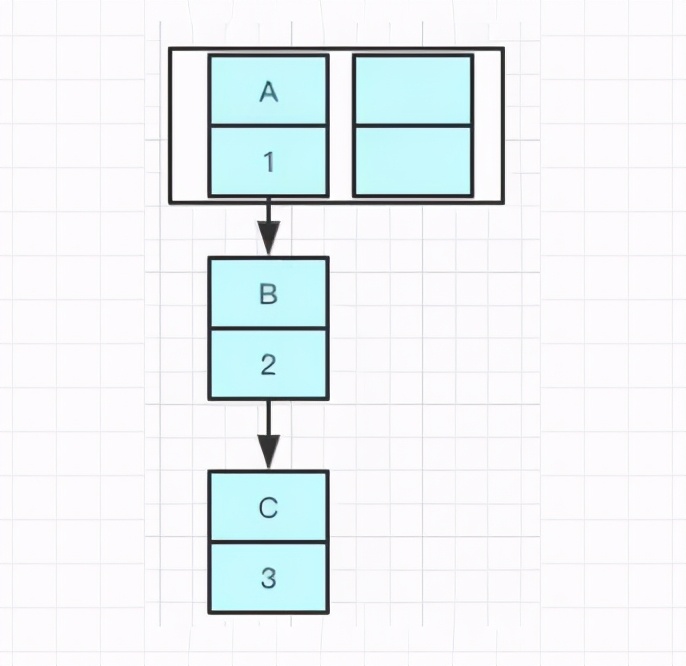
因为resize的赋值方式,也就是使用了单链表的头插入方式,同一位置上新元素总会被放在链表的头部位置,在旧数组中同一条Entry链上的元素,通过重新计算索引位置后,有可能放到了新数组的不同位置上。
可能出现如下情况,B的下个指针指向了A:
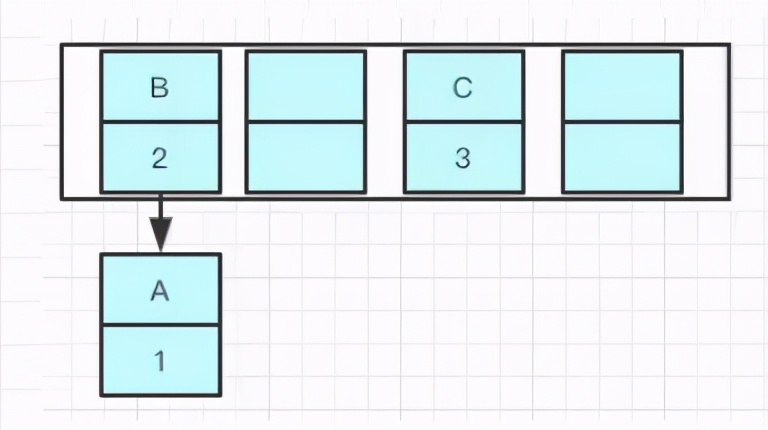
一旦几个线程同时都调整完成,就可能出现环形链表。

如果这个时候去取值,就会出现–Infinite Loop。
Java8之后的尾插法
使用头插法会改变链表的顺序,如果使用尾插,在扩容的时候保持链表元素原来的顺序,就不会出现链表成环的问题了。
就是说原本是A->B,在扩容后那个链表还是A->B
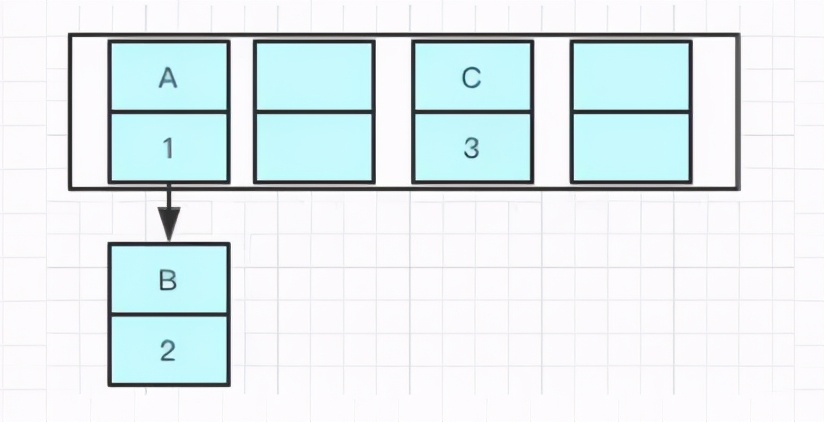
Java7在多线程操作HashMap时可能引起死循环,原因是扩容转移后前后链表顺序倒置,在转移过程中修改了原来链表中节点的引用关系。Java8在同样的前提下并不会引起死循环,原因是扩容转移后前后链表顺序不变,保持之前节点的引用关系。
那是不是意味着Java8就可以把HashMap用在多线程中?
Java8中HashMap即使不会出现死循环,但是通过源码看到put/get方法都没有加同步锁,多线程情况下最容易出现的就是:无法保证上一秒put的值下一秒get的时候还是原值,所以线程安全还是无法保证。
HashMap的默认初始化长度是多少?
源码显示初始化大小是16
/**
* The default initial capacity -MUST be a power of two .
*/
static final int DEFAULT_INITIAL_CAPACITY = 1<<4; //aka 16
这样是为了位运算的方便,位与运算比算数计算的效率高了很多,之所以选择16,是为了服务将Key映射到index的算法。我们是通过key的HashCode值去做位运算,
比方说:key为“你好”的二进制是123456那二进制就是11110001001000000
index 的计算公式;index = hashCode(key) & (Length-1)
15的二进制是1111,那 11110001001000000 & 1111十进制就是4
用位与运算效果和取模一样,性能也提高了不少!
为什么用16不用别的呢?
因为使用2的幂的数字的时候,Length-1的值所有二进制位全为1,这种情况下,index的结果等同于HashCode后几位的值。只要输入的HashCode本身分布均匀,Hash算法的结果就是均匀分布的。
这是为了实现均匀分布。
为啥我没重写equals方法的时候需要重写HashCode方法呢?用HashMap举例
因为在Java中,所有的对象都继承于Object类。Object类中有两个方法,equals、hashCode,这两个方法都是用来比较两个对象是否相等的。在未重写equals方法时候我们是继承object的equals方法,那个equals是比较两个对象的内存地址,显然我们new了两个对象内存地址肯定不一样,在HashMap中通过key的hashCode去寻找index的,如果index一样就形成了链表了,当我们根据key去hash然后计算出index,找到了2两个或多个,具体找哪个值就不知道了
equals!所以我们对equals方法进行了重写,建议一定要对hashCode方法重写,以保证相同的对象返回相同的hash值,不同的对象返回不同的hash值。
HashMap的线程是不安全的,怎么处理HashMap在线程安全的场景
在需要线程安全的场景使用一般使用HashTable或者ConcurrentHashMap,但是HashTable的并发度的原因基本上很少使用,存在线程不安全的场景的时候我们都是使用ConcurrentHashMap。
HashTable的源码很简单粗暴,直接在方法上加锁,并发度很低,最多同时允许一个线程访问,ConcurrentHashMap 就好很多,1.7和1.8有较大的不同,不过并发度都比前者好太多了。