文章目录
一、线程池的简介
1. 什么是线程池
首先我们可以参考下百度百科给出的答案:
线程池是一种多线程处理形式,处理过程中将任务添加到队列,然后在创建线程后自动启动这些任务。
然后我们可以通过百度百科的答案进一步的定义:
在进程开始时创建一定数量的线程,并加到池中以等待工作。当服务器收到请求时,它会唤醒池内的一个线程(如果有可用线程),并将需要服务的请求传递给它。一旦线程完成了服务,它会返回到池中再等待工作。如果池内没有可用线程,那么服务器会等待,直到有空线程为止。
2. 为什么要使用线程池
这里我们先使用多线程的方式实现一个简单的累加场景:
public class Demo01 {
public static int count = 0;
public static int Max = 100000;
public static void main(String[] args) throws InterruptedException {
long currentTimeMillis = System.currentTimeMillis();
while (count < Max) {
Thread thread = new Thread(() -> {
count++;
});
thread.start();
thread.join();
}
System.out.println("多线程执行时长:" + (System.currentTimeMillis() - currentTimeMillis));
}
}
这里看下运行结果

在这里,我们可以发现,简单的一个计数累加操作,由于使用了多线程来处理,处理时长甚至比单线程处理更长,而线程的创建和实例化无疑也频繁的引起了CPU的上下文切换及额外的内存开销,这显然使我们不愿意见到的。
然后我们在看下使用线程池的方式
public class Demo01 {
public static int count = 0;
public static int Max = 100000;
public static void main(String[] args) throws InterruptedException {
ExecutorService newCachedThreadPool = Executors.newCachedThreadPool();
long currentTimeMillis = System.currentTimeMillis();
while (count < Max) {
newCachedThreadPool.execute(() -> {
count++;
});
}
System.out.println("线程池执行时长:" + (System.currentTimeMillis() - currentTimeMillis));
newCachedThreadPool.shutdown();
}
}
运行结果:

那么为什么采用线程池可以节省这么多的时间呢?
3. 线程池的实现原理
线程池作为一种池化技术,其本质其实就是一种容器。用来实现容器的其实是两种数据结构:
- 第一种数据结构是用来存放工作线程的集合
- 第二种数据结构是用来存放待执行任务的队列
这里我简单的画一个图:
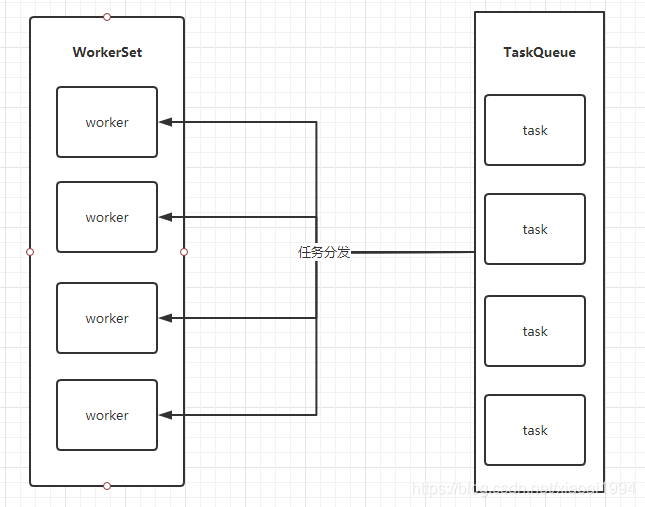
当用户向线程池提交任务时,他首先会将任务放入阻塞队列,然后线程集合中的线程会不断的去队列中获取任务并执行,当任务全部执行完毕后,线程集合中的线程就会阻塞。这像不像之前在讲wait方法的时候提到过的生产/消费模型?那么我们该如何创建一个线程池呢?
4. 创建线程池的方式
通常我们会采用两种方式来创建线程池。
4.1 通过构造方法创建
这里我们先看下通过构造方法如果创建线程池:
public class Demo01 {
public static void main(String[] args) {
new ThreadPoolExecutor(5, 20, 2, TimeUnit.SECONDS, new LinkedBlockingQueue<>(5));
}
}
通过构造函数的方式创建线程池其实也没什么难点,重点需要讲一下的是这里面涉及的一些参数。

- corePoolSize:指的是线程池的核心线程数,核心线程指的是当线程池空闲时并不会被回收的一部分线程。设置核心线程可以有效地较少由于线程创建和回收带来的性能开销,当然这里需要注意的是,核心线程设置的过大或者过小都不是很好,我们可以通过一个简单公式来计算核心线程设置多少性价比最高:核心线程数 = CPU核心数 * CPU使用率 * (1 + 吞吐量)。当然如果是一些简单的应用,我们可以直接设置为2*CPU核心数,获取CPU核心数可以通过int availableProcessors = Runtime.getRuntime().availableProcessors();
- maximumPoolSize:线程池的最大线程数,指的是线程池可以包含的最大容量,最大线程数的设置最好参考业务场景,不建议设置的过大,过大有概率会引起OOM问题(out of memory exception)。
- keepAliveTime: 保持存活时间,指的是当当前线程数大于核心线程数时,非核心线程在空闲状态下的最大存活时间。当空闲时间大于最大存活时间,空闲线程的生命周期就会结束。
- TimeUnit:表示的是等待时间的单位是什么,就比如时,分,秒。
- workQueue:表示的是使用哪种等待队列来实现线程池。常见的队列结构有LinkedBlockedQueue,SynchronousQueue等。
4.2 工厂方法
当然,如果你觉得通过构造方法的方式太过麻烦,Java也提供了一个工厂方法类Executors。

这里在讲这些不同工厂方法创建的不同的线程池之前,需要重点的提一下,使用工厂方法创建线程池的方式并不推荐应用在生产环境中,理由也很简单,因为工厂方法创建的线程池的默认最大线程数时Integer.MAX_VALUE,之前在讲最大线程数时有提到过,如果最大线程数过大,会导致内存溢出的问题。
接下来就简单的讲下几种常见的线程池:
- newCachedThreadPool:创建一个可缓存的线程池,如果线程池长度超过处理需要,可灵活回收空闲线程。若无可回收则会新建线程。
2.newFixedThreadPool:创建一个定长的线程池,每当提交一个任务就会创建一个工作线程,如果工作线程数量达到线程池设置的最大数,则将提交给线程池中的线程完成任务。
3.newSingleThreadExecutor:单线程化的Executor,只创建唯一的工作者来执行任务,所有任务按照FIFO顺序执行,如果当前线程出现异常,会创建新的线程取代他继续执行任务。其最大的特点就是执行任务的顺序是有序的。
4.newScheduleThreadPool:一个定长的线程池,可支持周期性的任务执行。- newSingleThreadScheduledExecutor 单线程执行的线程池,可以周期性的执行任务。
二、线程池的常用API
1. execute
这里先看下API文档对于方法的定义。

execute方法主要是用来执行我们想要委托线程池去完成的任务。由于他的返回值是void,这代表了方法结束他并不会返回任何对象,当遇到异常后他会第一时间抛出异常。这里我们可以看下execute方法的源码:
public void execute(Runnable var1) {
if (var1 == null) {
throw new NullPointerException();
} else {
int var2 = this.ctl.get();
if (workerCountOf(var2) < this.corePoolSize) {
if (this.addWorker(var1, true)) {
return;
}
var2 = this.ctl.get();
}
if (isRunning(var2) && this.workQueue.offer(var1)) {
int var3 = this.ctl.get();
if (!isRunning(var3) && this.remove(var1)) {
this.reject(var1);
} else if (workerCountOf(var3) == 0) {
this.addWorker((Runnable) null, false);
}
} else if (!this.addWorker(var1, false)) {
this.reject(var1);
}
}
}
我们来简单分析下源码中execute方法的实现步骤:
- 获取当前线程池的核心线程数,如果此时已存在的核心线程数小于设置的最大核心线程数,则在此时创建新的核心线程加入到线程池
- 如果一个task任务已经被加入queue,此时仍然需要重新判断是否需要添加新的线程,因为此时刚才新创建的想爱你成可能已经死亡或者线程池可能重启了,所以我们需要重新检查线程状态以便必要的时候回滚任务。
- 如果无法将task添加到队列并且无法获得新的线程,代表此时线程池处于饱和态或死亡态,此时会拒收任务。
2. submit
按照惯例,还是先看下官方文档:
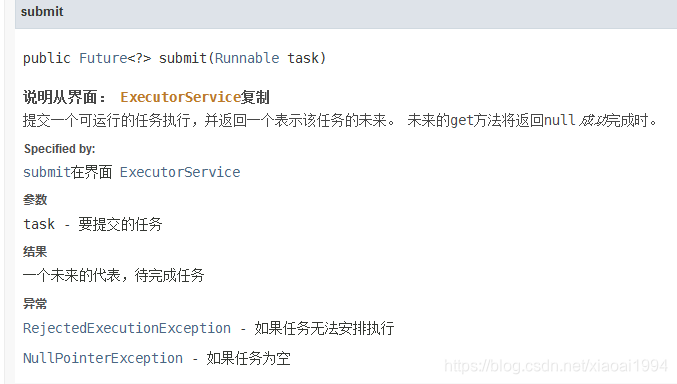
submit方法和execute方法很相似,都是用来执行我们想要委托给线程池的任务,不过submit方法会在执行结束后返回一个代表任务结果的future对象。如果在运行过程中发生异常,异常会被submit方法吞掉并加入到future对象中。当然还有一点需要注意,submit方法允许接收两种类型的参数,一种是实现了runnable接口的对象,这种情况下future对象虽然可以get,但是结果永远是null。另一种就是实现了callable接口的对象,此时submit方法拥有返回值并允许抛出异常。
3. execute方法和submit方法的区别
- execute() 参数 Runnable ;submit() 参数 (Runnable) 或 (Runnable 和 结果 T) 或 (Callable)
- execute() 没有返回值;而 submit() 有返回值
- submit() 的返回值 Future 调用get方法时,可以捕获处理异常
三 、 线程池工具类
这里我提供一个简单的线程池工具类的实现,可以根据实际情况做调整。
public class ThreadPoolUtil {
// 自适应核心线程数
private static final int corePoolSize = Runtime.getRuntime().availableProcessors() * 2;
// 最大线程数
private static final int maximumPoolSize = 500;
// 存活时间
private static final int keepAliveTime = 10;
// 存活时间计数方式
private static final TimeUnit timeUnit = TimeUnit.SECONDS;
// 任务队列
private static final BlockingQueue<Runnable> workQueue = new LinkedBlockingQueue<>(10);
// 单例模式
private static volatile ThreadPoolExecutor threadPool;
public static ThreadPoolExecutor getPool() {
if (threadPool == null) {
synchronized (ThreadPoolUtil.class) {
if (threadPool == null) {
threadPool = new ThreadPoolExecutor(corePoolSize, maximumPoolSize, keepAliveTime, timeUnit,
workQueue);
}
}
}
return threadPool;
}
private ThreadPoolUtil() {
super();
// TODO Auto-generated constructor stub
}
}