目录
- 介绍
- 背景
- 什么是指针?
- 什么是指向指针的指针?
- 悬空指针
- 指针从哪里开始?
- 局部变量和指针之间的差异
- 那么什么时候没有指针就不可能实现?
- 但是,有那么多神奇的智能指针!
- 什么是调用堆栈和堆栈溢出..
- 不能没有指针-案例1
- 不能没有指针-案例2
- 不能没有指针-案例3
- 不能没有指针-案例4
- 不能没有指针-案例5
- 不能没有指针-案例6
- 为什么指针如此强大
- 对象指针和功能指针之间的区别
- 按值传递参数
- 通过引用传递参数
- 兴趣点
介绍
指针是很多初学者的生死大敌,堪称c++的嘉峪关,在本文中,我将尝试阐明有关指针及其用法的某些要点, 希望对正在学习的你有所帮助。
背景
有时,在Web上,我会进行无数次有关C或C ++等语言的指针的讨论,关于使用指针是否值得甚至是明智的争论不断。 这个问题似乎一直持续到今天。 因此,希望澄清一些事情,我决定创建这篇文章。 我不会对这个问题过于熟练,也不会虔诚地要求每个人 new必须具有相应的 delete或每个人 malloc必须具有相应的 free。
本文适用于C和C ++,您除了处理原始指针外别无选择。 其他语言(例如Java,C#等)将所有的伏都教魔术隐藏在幕后。 它也适合那些不使用ASM,C或C ++编写代码但被主题迷惑的初学者。
我将尝试涵盖所有情况,而不会太深入技术细节。 如果您希望对指针有非常深入的技术知识,那么从Wikipedia到众多博客都可以找到很多信息。 cplusplus dot com网站上有一篇很棒的关于指针的文章,因此在这里我不再重复。 鉴于您正在使用C或C ++进行开发,因此我将在以下场景中进行介绍:
- 什么时候不使用指针就不可能实现某些东西
- 使用指针的优点
- 通过值,引用或指针传递变量
- 悬空指针
什么是指针?
指针是一个整数变量保持在所述特定的宽度(一个地址 float, double, int, struct, class,等等)值被存储在计算机存储器中。 因此,指针是计算机在金属层上本机可以理解的“事实”对象。 指针始终是宽度为8、16、32、64、128等位的无符号整数。 这在很大程度上取决于CPU的主寄存器宽度。 它也由操作系统运行时位对齐指示。 完全有可能在64位CPU上运行16位OS,但反之亦然。 但是,在16位OS中,即使CPU为64位宽,您也将被限制在16位地址空间中。
旁记:由于64位寄存器的宽度足以满足上述16位OS的需要,因此可以编写一个特殊的分段内存管理器,该管理器可以窥视超过64Kb的限制,但前提是物理寄存器必须足够宽(哦,旧的16位Windows) )。 16位内存段和偏移量的主题在今天已经过时了。 在当前的讨论中,我仅针对平面内存。
指针的宽度与该指针可以容纳的可寻址内存直接相关,并且其宽度的乘幂为2减1。
通过查看此表,您可以看到过去和将来。
如果您要在sifi小说领域中醒来,首先要检查的是它们使用的计算机上的可寻址指针存储器,以了解您要处理的内容 。
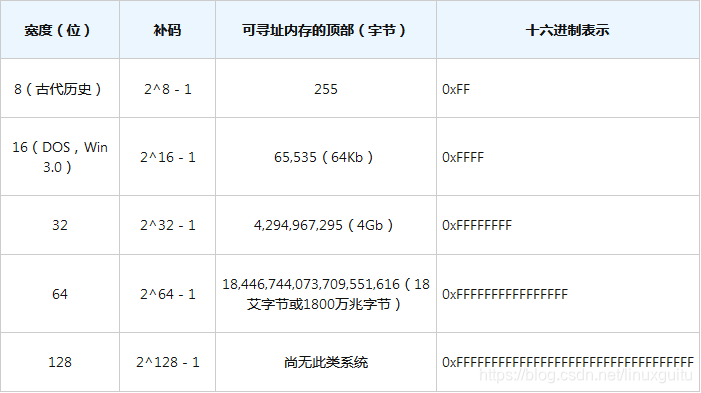
当今的64位处理器中确实存在128位寄存器,通常用于SIMD(单指令多数据)操作码。 长话短说–它们允许并排加载四个32位整数到同一个寄存器中,并在一个CPU周期(赫兹)中执行多个指令,例如MulDiv等。 值得一看:1 EB等于一百万TB。
好。 那么什么是指向指针的指针?
指向指针的指针是一个整数变量,它保存指针的地址。 它通常用作函数的返回值。 它也用于可能出现悬挂指针的危险的地方。
//
// Calling a function that returns a pointer
//
void* ptr = nullptr;
// declared as void SomeFuncReturnsPtr(void** p) { *p = value; }
SomeFuncReturnsPtr(&ptr);
// ptr is no longer null
ptr->DoStuff();悬空指针
作为直接指针(又称为指针副本)传递给不同函数的指针面临着以下危险:如果该函数删除了该指针,则该指针在另一个函数中的另一个副本不会无效。 它仍然保留已擦除内存的地址,因此成为悬空指针,因为它的状态似乎是有效的(不是 null)。 此类指针结果的任何用法都是未定义的运行时行为。 在非托管环境中,这是一个真正的危险,因为它在运行时很难找到,因此最好在编码阶段需要面对。
以下代码防御性地处理了指针悬空的可能性:
// Disastrous main
void main()
{
A* ptr = new A;
NukeA(ptr);
// ptr now is a dangling pointer
assert(ptr == nullptr); // Kaboom. Still points to wiped memory
delete ptr; // Kaboom
}
// Safe main
void main()
{
A* ptr = new A;
NukeSafelyA (&ptr);
// ptr now is null
assert(ptr == nullptr);
}
void NukeA(A* p)
{
p->DoThis();
p->DoThat();
delete p; // Kaboom! A dangling pointer is born
p = nullptr;
}
void NukeSafelyA(A** p)
{
(*p)->DoThis();
(*p)->DoThat();
delete *p; // Nice
*p = nullptr;
}实际上,如果您使用指针来动态分配内存,则永远不要将指针传递给另一个函数,尤其是该函数可以或可能删除它时。 仅通过指针将其传递给指针,然后 了该指针并 中将 则您的指针将变为 null如果实际上删除 在另一个函数 其无效, 。 这是一个非常简单的示例,但确实演示了何时可以发生。
也许干巴巴的文字看起来有写枯燥,如果单看文字不是很容易消化的话,可以进群973961276来跟大家一起交流学习,群里也有许多视频资料和技术大牛,配合文章一起理解应该会让你有不错的收获。
推荐一个不错的c/c++ 初学者课程,这个跟以往所见到的只会空谈理论的有所不同,这个课程是从六个可以写在简历上的企业级项目入手带领大家学习c/c++,正在学习的朋友可以了解一下。
指针从哪里开始?
计算机金属根本不在乎甚至不知道变量是什么或变量是什么。 它所了解的只是CPU寄存器和内存地址-指针。 话虽这么说,编译器通过变量声明创建了一种错觉,使CPU可以将其与内部寄存器以及从中加载该值的内存地址相关联。
局部变量和指针之间的差异
所有局部变量都被声明并驻留在函数堆栈框架中。 指向动态分配内存的指针也位于堆栈帧上,但它指向程序的全局堆内存。 在不受管理的全局堆中,程序有责任对其进行管理。 因此,任何泄漏的内存最终都会导致资源匮乏,并使您的程序迟早崩溃。
那么什么时候没有指针就不可能实现?
我可以列举几种这样的情况,但是让我在进一步尝试之前先解决一下。 每个程序都有多个功能堆栈框架和一个全局堆。 全局堆基本上是OS管理的虚拟内存。 堆栈是LIFO(后进先出)受限大小的数据结构。 可以想象,到相邻堆栈的任何溢出都将有效擦除已保存的数据并使程序崩溃。
但是,有那么多神奇的智能指针!
记住这一点。 没有任何代码看起来和行为像由不知道指针实际是什么或代表什么的人编写的智能指针所骑的代码一样糟糕。 在尝试使用智能指针沉迷程序之前,请阅读以下所有情况。 另外,返回并重新阅读“悬空指针”部分。 当通过资产而不是通过脑细胞处理原始指针到智能指针的连接/分离时,智能指针会创建此类底层而臭名昭著。
什么是调用堆栈和堆栈溢出
堆栈是LIFO数据结构。 实际上,编译程序也称为“堆栈计算机”。 每个进程和线程都有自己的堆栈。 每个堆栈都细分为调用堆栈。 调用堆栈的数量与程序中函数的数量完全匹配。 调用堆栈是堆栈中的较小块。 调用堆栈大小有一个限制,通常为1Mb。 在UNIX系统上,它是一个环境变量(我相信)。 Visual C ++编译器允许您使用 来更改调用堆栈的大小 /F标志 。
堆栈溢出最好通过以下 伪代码来表征 _chkstk()函数 :
;***
;_chkstk - check stack upon procedure entry
;
;Purpose:
; Provide stack checking on procedure entry. Method is to simply probe
; each page of memory required for the stack in descending order. This
; causes the necessary pages of memory to be allocated via the guard
; page scheme, if possible. In the event of failure, the OS raises the
; _XCPT_UNABLE_TO_GROW_STACK exception.
;
; NOTE: Currently, the (EAX < _PAGESIZE_) code path falls through
; to the "lastpage" label of the (EAX >= _PAGESIZE_) code path. This
; is small; a minor speed optimization would be to special case
; this up top. This would avoid the painful save/restore of
; ecx and would shorten the code path by 4-6 instructions.
;
;Entry:
; EAX = size of local frame
;
;Exit:
; ESP = new stackframe, if successful
;
;Uses:
; EAX
;
;Exceptions:
; _XCPT_GUARD_PAGE_VIOLATION - May be raised on a page probe. NEVER TRAP
; THIS!!!! It is used by the OS to grow the
; stack on demand.
; _XCPT_UNABLE_TO_GROW_STACK - The stack cannot be grown. More precisely,
; the attempt by the OS memory manager to
; allocate another guard page in response
; to a _XCPT_GUARD_PAGE_VIOLATION has
; failed.
;
;*******************************************************************************由于堆栈大小有限,因此会监视溢出到相邻堆栈上的内容,如果发生这种情况,则会引发异常。 A _PAGESIZE_在32位操作系统上为4Kb,在64位操作系统上为8Kb,因此,如果任何变量大小大于页面大小,则会对其进行检查,但不一定会导致堆栈溢出。
Alloca()函数在运行时从本地堆栈中拉出内存。
不能没有指针-案例1
对象大小超过了函数堆栈的大小。 此限制要求使用全局堆,因此,如果对象太大或随着时间增长可能会变大,则需要使用指针。 每个人至少遇到一次堆栈溢出异常或分段错误。
会是什么 仅举几例:
- 读取在堆栈上声明的> 1Mb文件(或大于默认堆栈大小)的字符数组:
//
// Kaboom – Stack overflow
//
char file_readin[2000000]; //to read a file that of that size or less
...- 嵌套类和数组的C ++对象,其累积大小大于1Mb(或大于默认堆栈大小):
class CGiganticClass{…}; // sizeof(CGiganticClass) >= 1,048,576 bytes
//
// Kaboom – Stack overflow
//
CGiganticClass a;- 递归函数可调用数千个调用。 在这种情况下,即使指针也无法挽救您,但可能会延迟不可避免的情况:
//
// Kaboom – Stack overflow
//
void recursive_function(int value)
{
char file_readin[200];
for(int i = 0; i < 100000; i++)
{
recursive_function(i);
}
}- 集合的实现:
//
// Futile attempt to write a collection that uses stack only
//
template class futile_array<class T>
{
T arr[1000]; // zeroed in ctor
size_t avail_index; // zeroed in ctor
public:
void add(const T val)
{
if(avail_index >= 1000)
return;
arr[avail_index++] = val;
}
};
void main()
{
//
// Kaboom – Stack overflow
//
futile_array<CGiganticClass> a;
}- 使用的子系统在编译期间不可用,仅在运行时存在,因此仅返回指针(Windows API,DirectX API,Linux sys调用,Open GL等):
void main()
{
//
// Available only during runtime, but not compile time
//
void* ptr = ::SomeOperatingSysAPI();
// cast and do whatever you need
SomeStruct* p = (SomeStruct*)ptr;
}- 任何其他类型的运行时创建或销毁。
如果您使用的是嵌入式系统,情况将会更加糟糕。 在那里,您将很幸运获得4Kb甚至更小的堆栈大小。
不能没有指针-案例2
受控创建。 通过声明指针,不会创建任何对象。 并且即使它们指向较大的对象,相应的指针在内存中也仅占据4字节(32位指针)或8字节(64位指针)。 您可能只想在运行时中且在某些条件下(例如在任何其他情况下)绝对必要时才创建该对象。 因此,控制程序的内存消耗。
不能没有指针-案例3
与案例2相反。控制破坏。 自动变量在函数退出后以相反的顺序销毁。 这也适用于主要功能。 有时,有必要在函数结束之前进行清理。 您可以释放一些资源,卸载动态库,等等。 想象一个类,例如,包含指向DLL对象的指针,并且该类被声明为堆栈变量。 因此,您可以在函数返回和类析构函数调用之前卸载该DLL。 并且,如果您的类析构函数恰好在同一DLL上执行清理任务,则您的程序将崩溃。 在返回任何函数之前和释放该DLL之前,必须销毁此类对象。 因此,您需要控制该对象破坏的时间。
我知道您会很聪明,并且您会争辩说,使用函数本身内的嵌套括号来控制自动变量的销毁是可以实现的。 是的,但前提是不需要在这些花括号之外使用该变量,而且看起来很丑。
不管潜在的情况是什么,要记住的最重要的事项是您可以及时地或在您选择的特定情况下物理控制对象的死亡。
旁白:BTW智能指针无法提供“受控破坏”功能。 他们从字面上将您的指针砍入一个“堆栈变量”,每个副本都会对其进行引用计数,并在整个位置进行复制。 仅当智能指针提供了删除基础指针的调用时,才可以控制指针的生存期,但是它比对delete运算符本身的调用更为丑陋和隐秘。 反正我的意见。
同样,弱指针是强智能指针的观察者,并且强智能指针实际上在内部携带每个弱指针副本的数组,以便可以将基本强指针消亡通知给它们。 每个弱指针实例都会在一个强指针内添加到数组,并且实际上可以在内部达到一个相当大的大小,与常规的原始指针相比,这在性能上要差得多。
我不主张这样做,但是您必须知道成本是什么,是否值得。
不能没有指针-案例4
单个大小太大的C或C ++对象的集合,以至于不必要地对其进行任何复制或移动都会严重破坏堆,以至于对操作符new(或malloc)的任何连续调用最终都将导致内存不足异常。 这可能是什么? 数据库引擎实现,一种在场景中拥有50,000个对象的游戏,其中包含网格和纹理以及其他数据,仅举几例。 在这种情况下,在分配了这些对象之后,应避免这些对象的任何复制或移动。 它们必须保留在最初创建的位置,并且对它们的任何操作(例如函数调用值,排序等)必须仅通过指针完成,而不能通过对象本身完成。 例如,您可以基于某些对象条件对对象指针进行排序,而无需在内存本身中重新排列对象。 此类对象由指针存储在集合中。 因此, std::vector<CGiganticClass*>存储为指针,并按指针而不是实际的类进行排序。 这可能是一个令人困惑的情况,可以通过一个示例来解决。 任何工业强度集合(例如 std::vector内部)都使用堆来创建类型。 但是,它在堆上恰好为“类型”,对象本身或指向对象的指针分配了空间。 在声明指向指针的向量的情况下,将永远不会创建任何对象,而只会创建指向它们的指针。 因此,您实际上可以稍后分配它们。 或者,如果已经创建/分配了它们,则将指针添加到集合将不会导致对象复制或移动本身。 只能通过仅4或8个字节宽的指针进行复制和移动。
不能没有指针-案例5
如上所述,在情况4中,通过指针存储对象提供了另一个绝佳的优势。 您不仅可以存储在指针数组,但所有在同一时间,你可以在这些非常相同的指针存储 std::map, std::unordered_map, std::list, std::hashmap同时,从来没有产生不必要的对象副本。 您可能希望通过索引,键值或任何其他有效的搜索模式对其进行访问,并获得指向要查找内容的指针,而主对象在堆内存中保持静态。 这甚至使数据繁重的程序也变得异常快速和响应。
不能没有指针-案例6
指针传递的异步执行参数或更好地称为线程参数,它们实际上是调用函数内的堆栈自动变量。 好吧,任何试图通过地址将堆栈变量传递到独立线程中的尝试都是不可避免的灾难的关键。 因为当调用函数退出时,变量将被破坏,并且相应的线程指针将在查找并访问无人区。 这也适用于错误使用智能指针,该智能指针在函数退出后删除了对象,并使线程指针处于悬空状态。
为什么指针如此强大
指针是有状态的对象。 它不仅可以访问对象本身,而且还可以同时保存有关对象是否存在的信息。
对象指针和功能指针之间的区别
声明约定。 对象指针指向数据段,而函数指针指向代码段。 另外,不需要动态分配或删除函数指针。
按值传递参数
你说什么? 每个人都知道! 为什么还要费心讲这个话题。 好吧,好吧,检查一下堆栈部分的图–参数。 在跳转到函数的标签之前,每个参数都会被压入该堆栈,根据该对象的组成,它可能是很多PSH汇编操作码。 还有一个为什么数组始终由指针传递的另一个原因,即使它们没有明确指定。 顺便说一句,这仅适用于C数组,如果您传递类似的东西 std::vector,它将按值传递或复制。 如果您需要计算函数跳转需要多少个CPU周期,则取决于对象的大小。 因为它是完整且独立的副本,所以该推送也可能导致堆栈溢出。 有时,您别无选择,只能传递价值。 但是,当您不必这样做时,通过引用或指针进行传递的速度要快数百倍,因为它只是一个4或8字节的推送,而不是数百次的推送。
通过引用传递参数
它使您可以通过一个PSH操作码将一个巨大的对象传递到一个函数中,并可以对其进行访问,就好像它不是指针一样。 但这要付出另外的代价。 首先,您可能会意外传入一个已取消引用的空指针,并且您的函数将崩溃。 其次,由于引用本质上是无状态的,因此绝对没有办法检查引用是否良好。 这提出了一个有趣的观点,即如果对象是指向动态分配的内存的指针,则不要通过引用(取消引用)将其传递,而应通过指针将其传递。
兴趣点
值得一提的是,即使您的计算机仅安装了1 GB的物理内存,一个32位操作系统也可以在每个进程中寻址整个4 GB的地址空间。 这种魔术是通过磁盘文件系统执行的,因此将不适合物理RAM的内容写入磁盘或“分页”(使其在某种程度上取决于磁盘的读/写速度)。 实际上,每个进程都有自己的单独4 GB地址空间(虚拟),而不管您的硬件RAM容量如何(达到一定程度)。 不仅如此,每个进程还拥有自己的虚拟处理器。 操作系统在切换进程/线程上下文本身时会切换处理器值。 对于处理器寄存器而言,保持指向当前进程内存而不是相邻进程内存的指针非常重要。 一个进程中的任何崩溃都不会损害任何其他进程。 在旧的16位系统(如MSDOS或Windows 1.0、2.0、3.0和3.1)中,情况并非如此。 这些在物理硬件金属本身和一个崩溃的程序上运行的操作系统可能实际上使其他任何程序和OS崩溃。
让你不再害怕C语言中的指针(上)