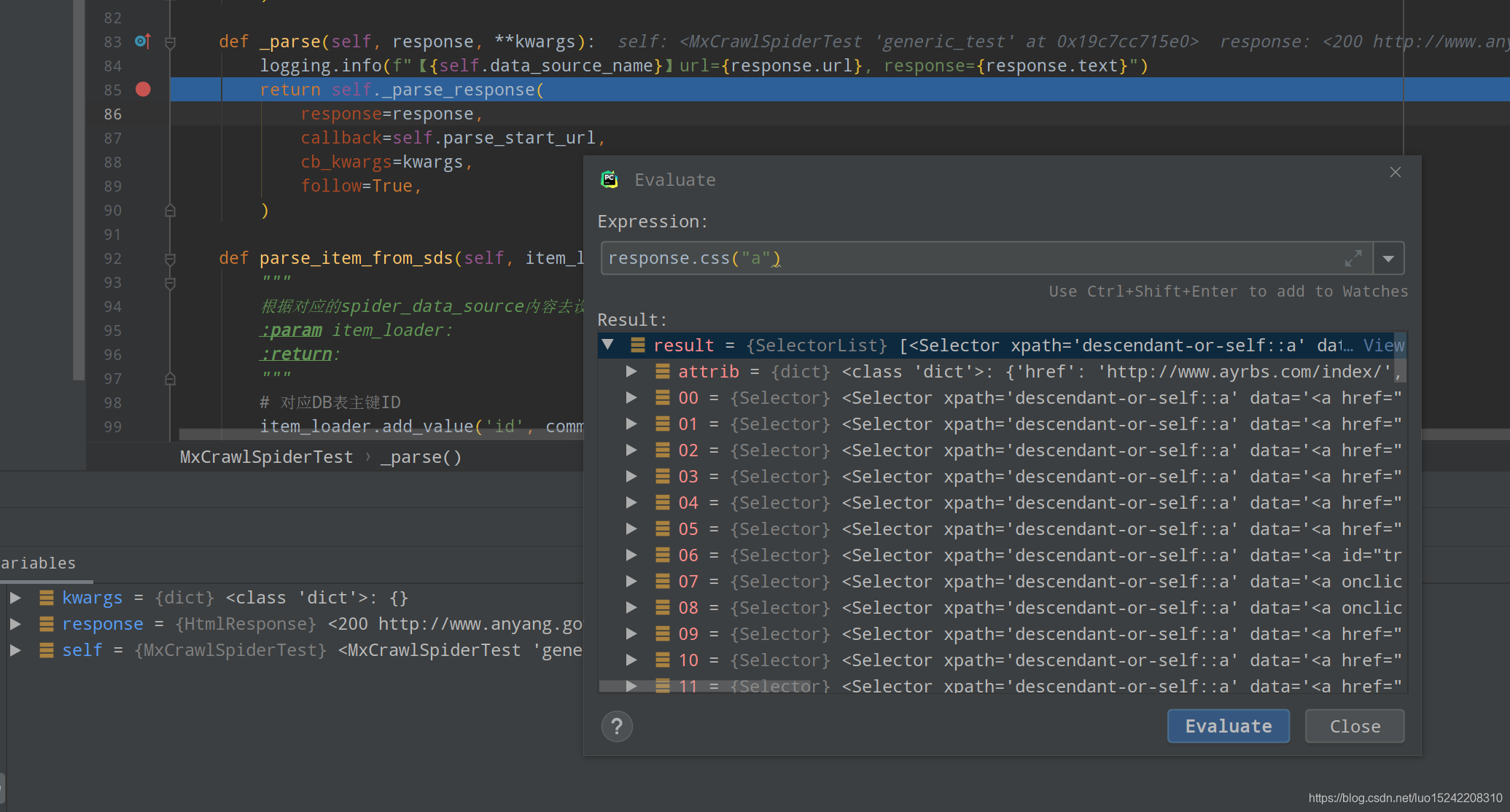
例如CrawlSpider,可重写_parse(如下仅加入logging日志打印)
def _parse(self, response, **kwargs):
logging.info(f"【{self.data_source_name}】url={response.url}, response={response.text}")
return self._parse_response(
response=response,
callback=self.parse_start_url,
cb_kwargs=kwargs,
follow=True,
)
之后可通过debug方法,查看response.url, response.text具体内容,亦可通过response.css或xpath查看选择器是否生效